05: ViViT: A Video Vision Transformer(
ViViT
)
About website
📝 100 AI Papers with Code
About this series
01: Transformer
02: Vision Transformer
03: DeiT
04: Swin Transformer
On this page
1
Preliminary
2
ViViT
2.1
Experiment
3
Summary
4
Key Concepts
5
Q & A
6
Related resource & Further Reading
05: ViViT: A Video Vision Transformer(
ViViT
)
Computer Vision
Transformer
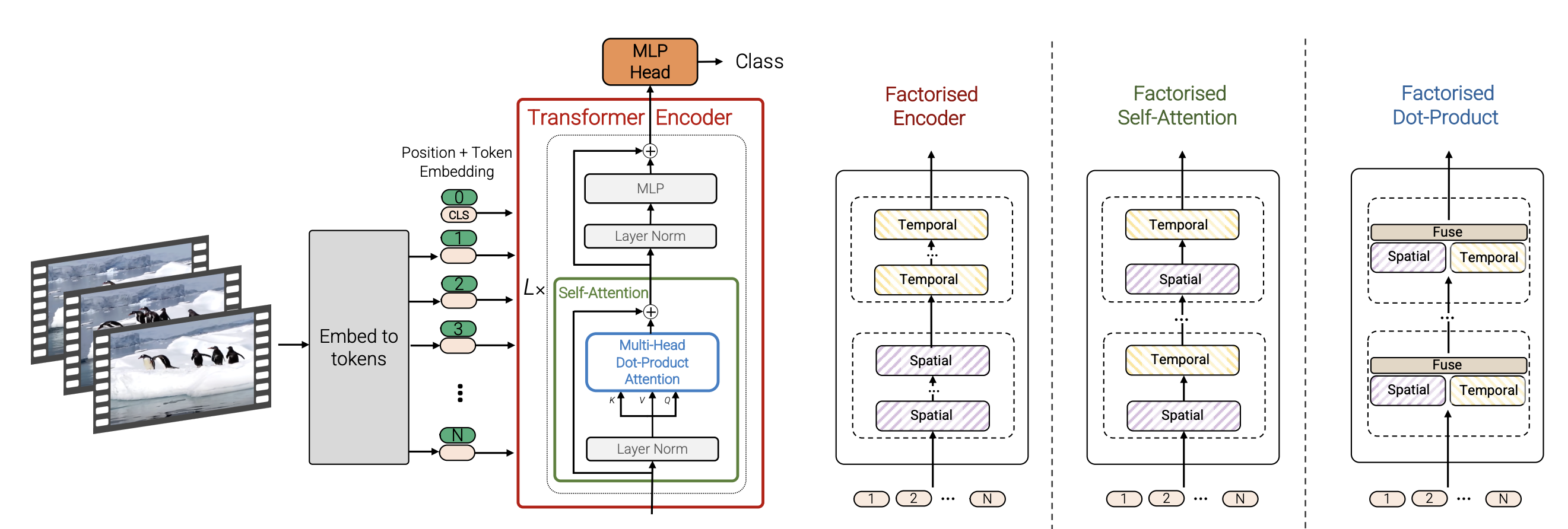
ViViT: A Video Vision Transformer提出将 Vision Transformer 系统性扩展到视频建模,通过
时空分解
与
高效注意力设计
直接对视频序列进行建模,在视频分类等任务上取得强性能与良好可扩展性。
1
Preliminary
2
ViViT
2.1
Experiment
3
Summary
4
Key Concepts
5
Q & A
6
Related resource & Further Reading
Back to top