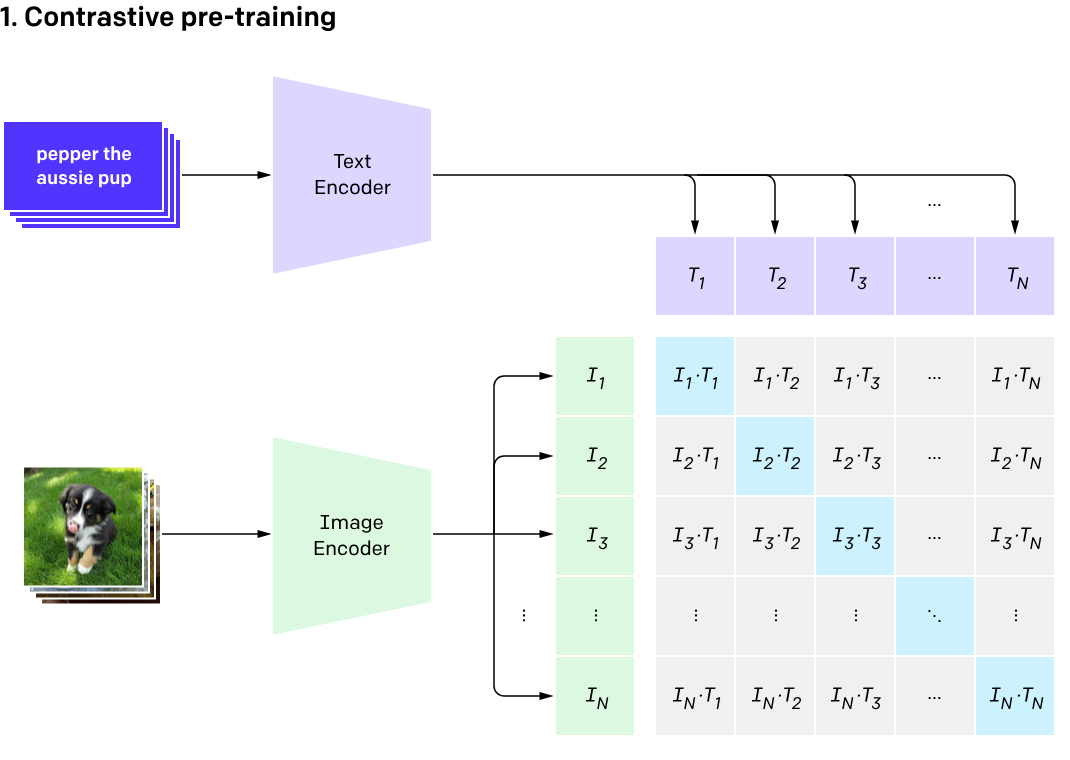
06: Learning Transferable Visual Models From Natural Language Supervision (
CLIP
)
About website
📝 100 AI Papers with Code
About this series
01: Transformer
02: Vision Transformer
03: DeiT
04: Swin Transformer
On this page
1
Preliminary
2
CLIP
3
Summary
4
Key Concepts
5
Q & A
6
Related resource & Further Reading
06: Learning Transferable Visual Models From Natural Language Supervision (
CLIP
)
Multi Modality
Representation Learning
一种通过对齐图像与自然语言文本的对比学习框架,在海量图文对上训练统一表示,从而获得强零样本泛化能力的视觉模型。
1
Preliminary
2
CLIP
3
Summary
4
Key Concepts
5
Q & A
6
Related resource & Further Reading
Back to top