16: Scalable Diffusion Models with Transformers (
DiT
)
About website
📝 100 AI Papers with Code
About this series
01: Transformer
02: Vision Transformer
03: DeiT
04: Swin Transformer
On this page
1
DiT
2
Preliminary
3
DiT
3.1
Experiment
4
Summary
5
Key Concepts
6
Q & A
7
Related resource & Further Reading
8
Summary
9
Key Concepts
10
Q & A
11
Related resource & Further Reading
16: Scalable Diffusion Models with Transformers (
DiT
)
Generative Model
Diffusion Model
一种将 Transformer 架构引入扩散模型的生成方法,通过序列化建模与规模化训练,在大模型与大数据设置下实现更强的生成质量与可扩展性。
# Preliminary
1
DiT
2
Preliminary
3
DiT
3.1
Experiment
4
Summary
5
Key Concepts
6
Q & A
7
Related resource & Further Reading
8
Summary
9
Key Concepts
10
Q & A
11
Related resource & Further Reading
Back to top
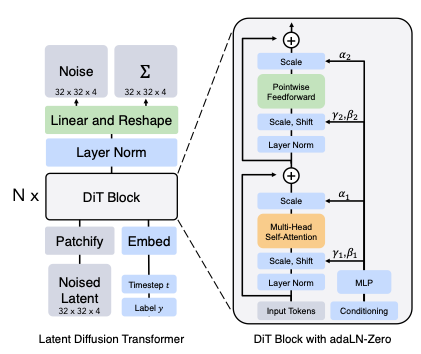 # Preliminary # Preliminary
# Preliminary # Preliminary