LLM Series Part1: Architecture and Training Stages
1 Introduction
随着LLM的迅速发展,模型的架构也在不断的演变。不过万变不离其宗,基于Transformer (Vaswani et al. 2023) 的模型架构依然是现在主流的的基本框架,包括现在SOTA的LLM,比如ChatGPT,LLaMA,DeepSeek,Qwen等都是基于Transformer架构的模型。不过在这个基本框架之上,不同的模型在不同的Component上进行了不同的改进和优化。比如在Attention机制上,除了最初的Scaled Dot-Product Attention之外,还有一些改进的Attention机制,比如Sparse Attention,Linear Attention等,这些改进的Attention机制可以有效地减少计算复杂度,提高模型的效率。另外,在Feed-Forward Network(FFN)部分,也有一些改进的结构,比如Gated Linear Units(GLU),Mixture of Experts(MoE)等,这些改进的结构可以提高模型的表达能力和性能。在这篇文章中,我们将深入探讨不同的LLM模型架构,介绍不同Component的演变和改进,以及除了Transformer架构之外的其他架构,比如Mamba架构。最后,我们还会介绍不同的Optimizer,Loss Functions和Regularization techniques在LLM训练中的应用。

首先我们先来回顾一下Transformer架构的基本组成部分和工作原理。
2 Review of Transformer Architecture
Transformer的基本框架如下图所示:
Transformer模型主要由以下几个部分组成:
- Input Embedding:将输入的文本数据转换为向量表示,通常使用词嵌入(Word Embedding)。
- Position Encoding:由于Transformer模型没有循环结构,因此需要通过位置编码来引入位置信息,使模型能够理解输入序列中各个元素的相对位置。
- Attention Mechanism: Transformer模型的核心组件是Attention机制,最初的Transformer使用的是Scaled Dot-Product Attention,它通过计算输入序列中各个元素之间的相关性来捕捉上下文信息。随着模型的发展,出现了一些改进的Attention机制,比如Sparse Attention,Linear Attention等,这些改进的Attention机制可以有效地减少计算复杂度,提高模型的效率。
- Feed-Forward Network (FFN): 在每个Transformer层中,除了Attention机制之外,还有一个Feed-Forward Network(FFN)。
- Normalization Layer: 在Transformer模型中,通常会在每个层的输入和输出之间添加一个Normalization Layer,它可以帮助模型更好地训练和收敛。
- Residual Connection: 在Transformer模型中,通常会在每个层的输入和输出之间添加一个Residual Connection,用来训练模型更深的层数,避免梯度消失问题。
- Output Layer: 最后,Transformer模型会通过一个输出层来生成最终的输出结果,通常是一个线性层或者一个Softmax层。
相比于Transformer的Encoder和Decoder的架构,LLM通常采用Decoder-Only的架构,也就是只使用Transformer的Decoder部分来进行文本生成任务。
接下来我们来逐一介绍Transformer的不同Component的演变和改进。
3 Word Embedding Layer
所有的LLM的模型,不论是基于Transformer框架,还是其他框架,都会有一个Embedding Layer来将所有的输入Tokens(One hot encoding)转化为Dense Vector的形式。通常来说,Embedding Layer的输入是一个整数序列,表示输入文本中的每个Token的索引,输出是一个二维矩阵,每一行对应一个Token的向量表示。这个向量表示可以通过训练来学习得到,也可以使用预训练的词嵌入(Word Embedding)来初始化。数学的表达也很简单:
\[ x_i = E[t_i] \tag{1}\]
其中:
- \(t_i\) 是输入文本中的第\(i\)个Token的索引。
- \(E\) 是一个矩阵,表示词嵌入的权重矩
- \(x_i\) 是第\(i\)个Token的向量表示。
- \(E[t_i]\) 表示从矩阵\(E\)中取出第\(t_i\)行的向量作为第\(i\)个Token的向量表示。
举个例子,假如我们有一个输入文本:
第一步就是先将这个文本进行Tokenization,得到一个整数序列,比如:
这些数字只是词表里的索引,本身没有大小意义。也不能进行比较或者计算。接下来,我们就可以通过Embedding Layer来将这个整数序列转化为一个二维矩阵,每一行对应一个Token的向量表示,比如:
这个二维矩阵就是输入文本的向量表示,可以作为后续模型的输入。通过训练,模型可以学习到更好的词嵌入,从而提高模型的性能和表达能力。
那么Embedding Layer长什么样子呢?假如:
- vocab size = 10,000
- hidden size = 512
那么Embedding Layer的权重矩阵\(E\)的维度就是\(10,000 \times 512\),也就是说,\(E\)是一个10,000行,512列的矩阵,每一行对应一个Token的向量表示,每一列对应一个隐藏维度。这个矩阵的大小取决于词表的大小和隐藏维度的大小。通常来说,词表越大,隐藏维度越大,模型的表达能力就越强,但同时也会增加模型的参数量和计算复杂度。因此,在设计Embedding Layer的时候,需要根据具体的任务和资源来选择合适的词表大小和隐藏维度大小。
4 Position Encoding
在Transformer中,由于Attention机制是通过观察比较全局的输入序列来捕捉上下文信息的,因此模型本身并没有循环结构,也没有卷积结构,所以无法直接捕捉输入序列中各个元素的相对位置关系。为了引入位置信息,Transformer使用了Position Encoding来为输入序列中的每个Token添加位置信息,使模型能够理解输入序列中各个元素的相对位置。通过不同的实现方式,Position Encoding大致可以分为三类:
- Absolute Position Encoding:给句子中的每个Token分配一个唯一的位置信息。
- Learnable Position Encoding:将位置信息作为一个可学习的参数来训练模型。(其实也可以看成是Absolute Position Encoding的一种特殊情况)
- Relative Position Encoding:通过计算输入序列中各个元素之间的相对位置关系来引入位置信息。
接下来我们来逐一介绍这三种Position Encoding的实现方式和特点。
4.1 Absolute Position Encoding
Absolute Position Encoding是Transformer中最初使用的Position Encoding方式,它通过给句子中的每个Token分配一个唯一的位置信息来引入位置信息。具体来说,Absolute Position Encoding使用一个固定的函数来计算每个Token的位置信息,通常使用正弦和余弦函数来计算位置信息。数学的表达如下:
\[ \begin{split} PE_{(pos, 2i)} & = \sin\left(\frac{pos}{10000^{2i /d_{model}}}\right) \\ PE_{(pos, 2i+1)} &= \cos\left(\frac{pos}{10000^{2i /d_{model}}}\right) \end{split} \tag{2}\]
其中:
- \(pos\) 是Token在输入序列中的位置索引。
- \(i\) 是隐藏维度的索引。
- \(d_{model}\) 是模型的隐藏维度大小。
我们可以看到,Absolute Position Encoding将Word Embedding的维度分成两个为一组,每组使用一个正弦函数和一个余弦函数来计算位置信息。这样做的好处是,模型可以通过观察输入序列中各个元素的位置信息来捕捉上下文信息,从而提高模型的性能和表达能力。
4.2 Learnable Position Encoding
Learnable Position Encoding是Absolute Position Encoding的一种特殊情况,它将位置信息作为一个可学习的参数来训练模型。具体来说,Learnable Position Encoding使用一个可学习的矩阵来存储位置信息,每一行对应一个位置索引,每一列对应一个隐藏维度。数学的表达如下:
\[ PE_{(pos)} = P[pos] \tag{3}\]
其中:
- \(pos\) 是Token在输入序列中的位置索引。
- \(P\) 是一个可学习的矩阵,表示位置信息的权重矩阵。
- \(PE_{(pos)}\) 是第\(pos\)个位置的位置信息向量。
其实在LLM的训练中,Learnable Position Encoding时很少见的Encoding方式,其原因就是它的参数量比较大,尤其是当输入序列的长度比较长的时候,Learnable Position Encoding的参数量会急剧增加,从而增加模型的计算复杂度和内存占用。因此,在实际应用中,Learnable Position Encoding通常不如Absolute Position Encoding常见。最常见的Learnable Position Encoding的应用场景是在Vision Transformer (Dosovitskiy et al. 2021)中,在Vision Transformer中,输入序列的长度通常比较短,因此Learnable Position Encoding的参数量相对较小。
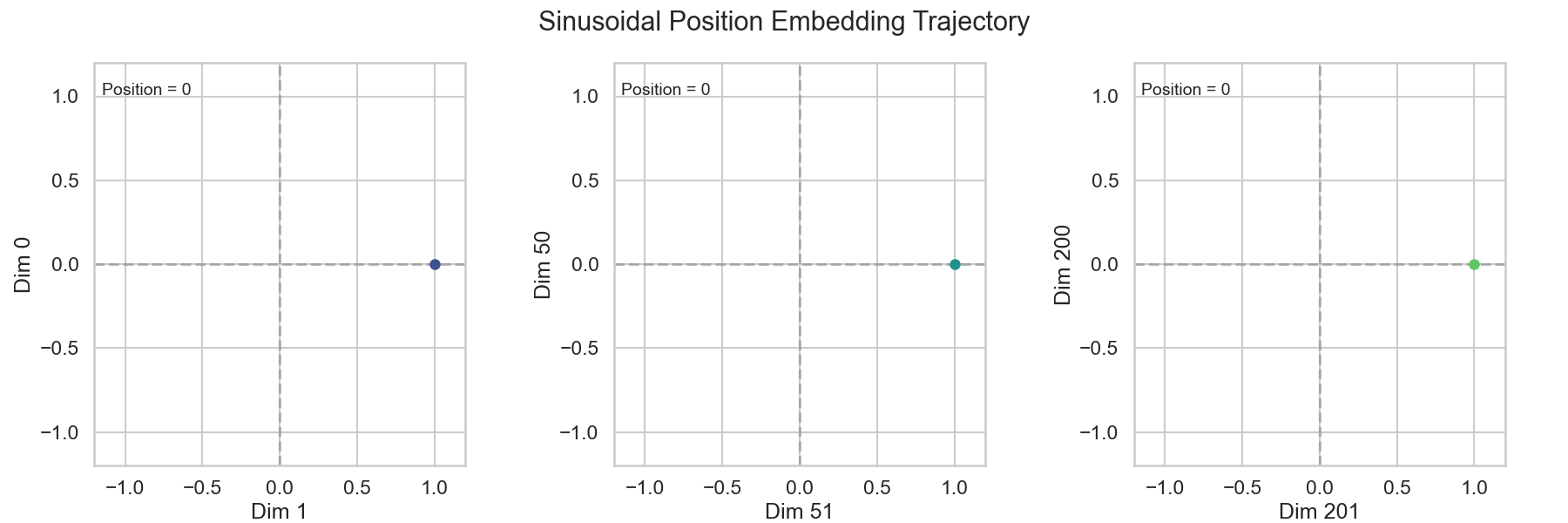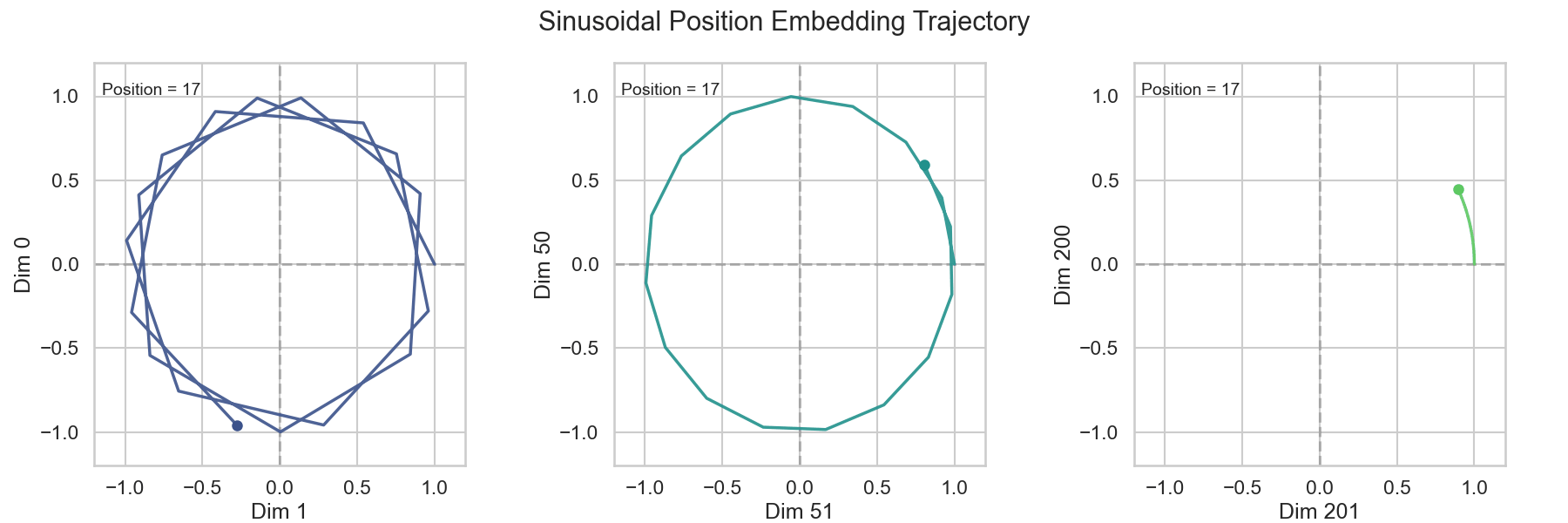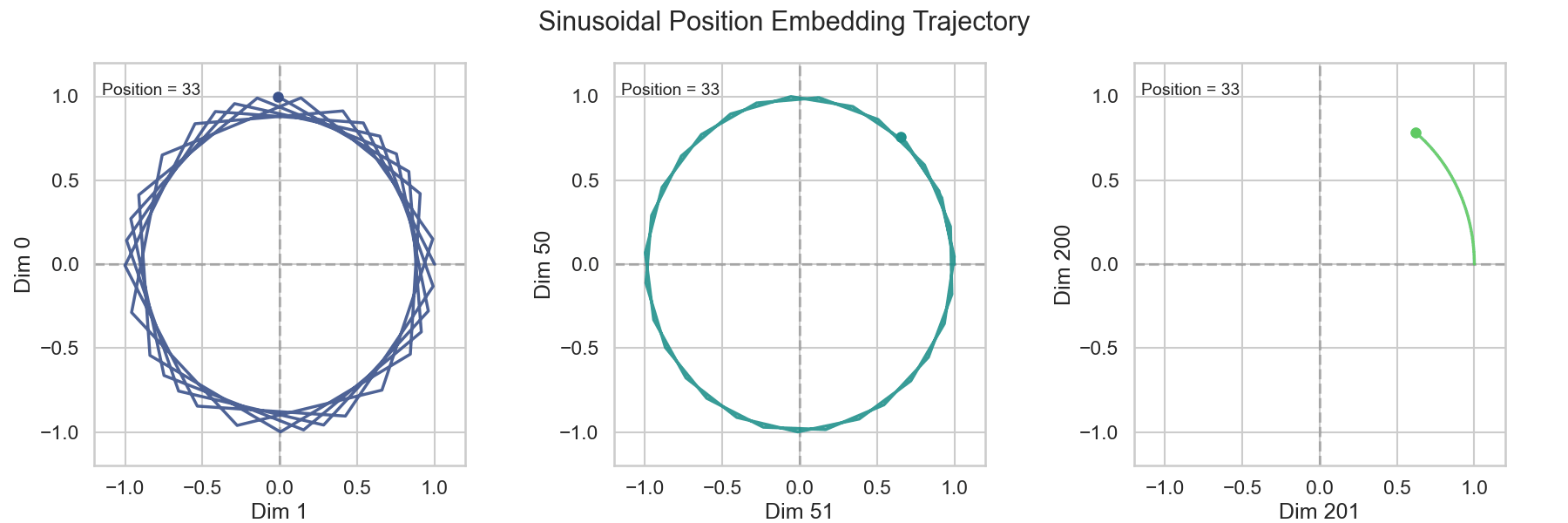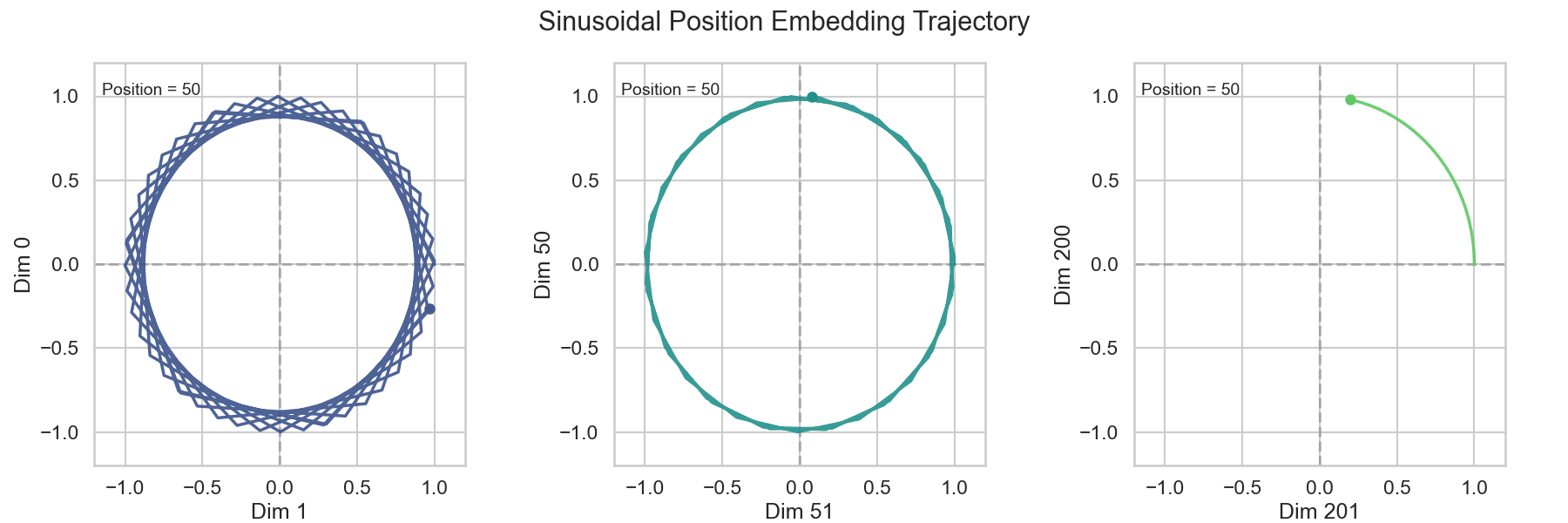
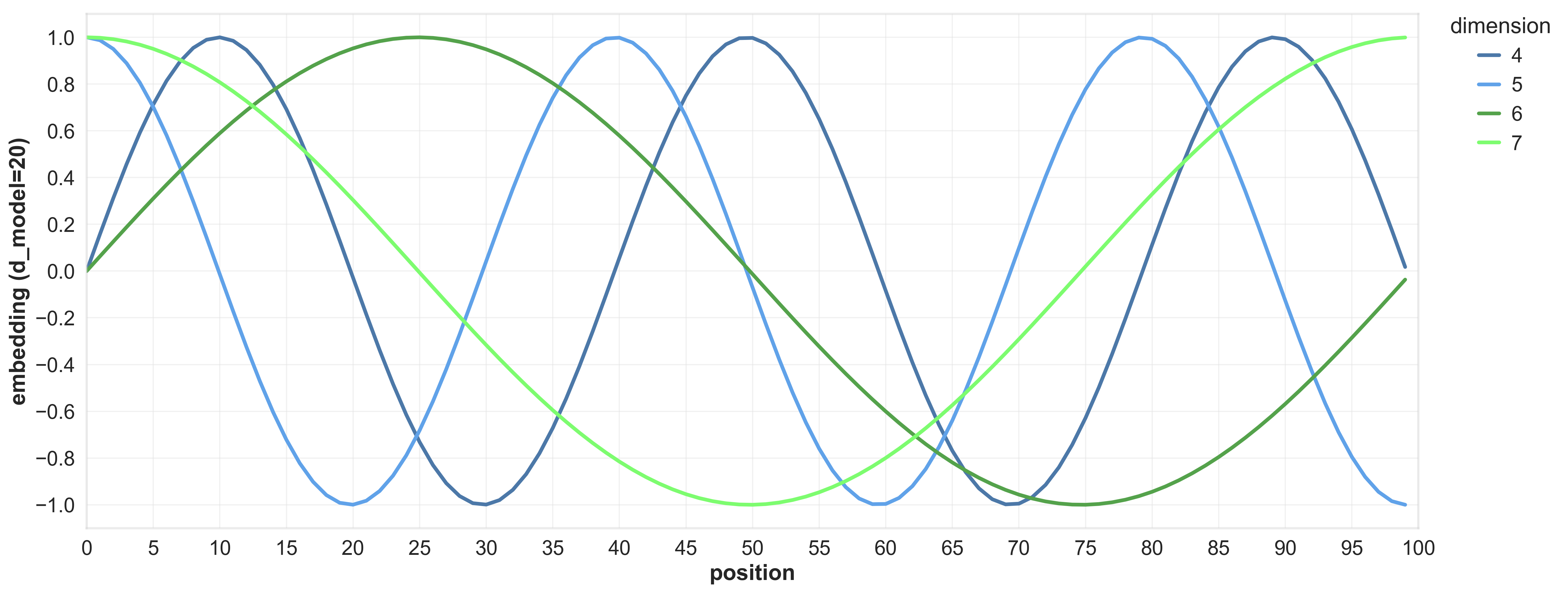
4.3 Relative Position Encoding
比如Alibili(Press, Smith, and Lewis 2022) 和 T5
4.4 RoPE
4.5 Position Interpolation
在训练的时候,我们设定最长的长度,但是在Inference的时候,我们可能会遇到比Max Position更长的Sequence,
4.5.1 Frequence-Based PI
4.5.2 Dynamic-Scaling
4.6 NoPE
5 Attention Mechanism
5.0.1 Multi-Head Attention(MHA)
5.0.2 Groped Query Attention(GQA)
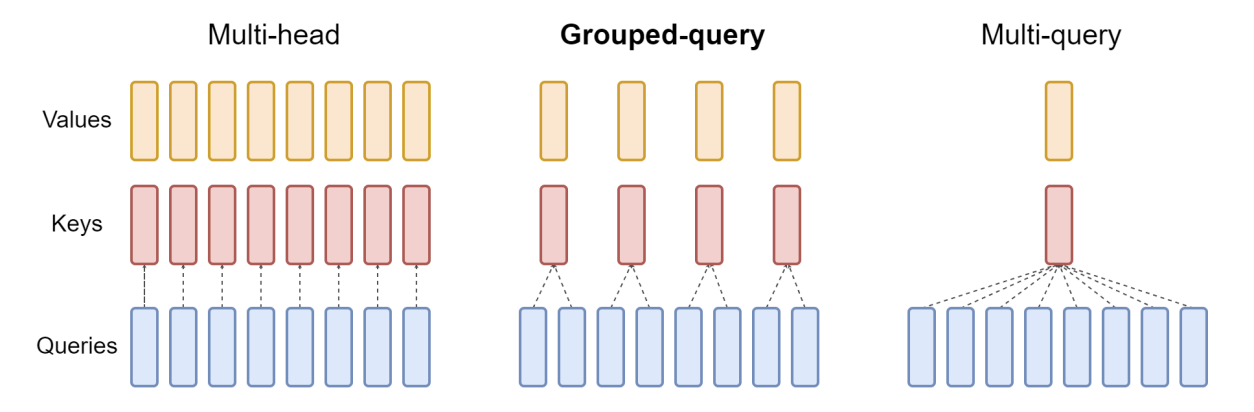
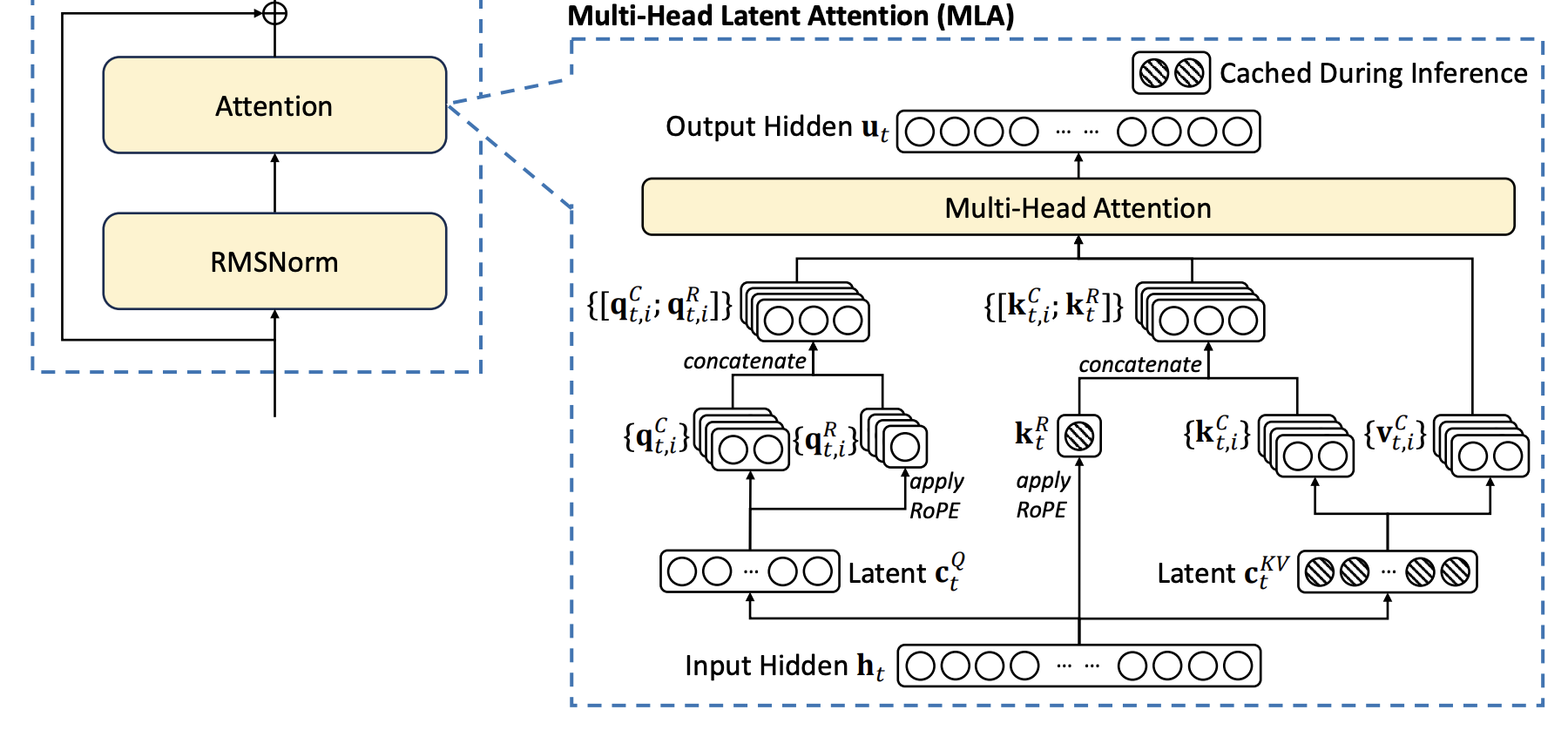
5.0.3 Multi-Head Latent Attention(MLA)
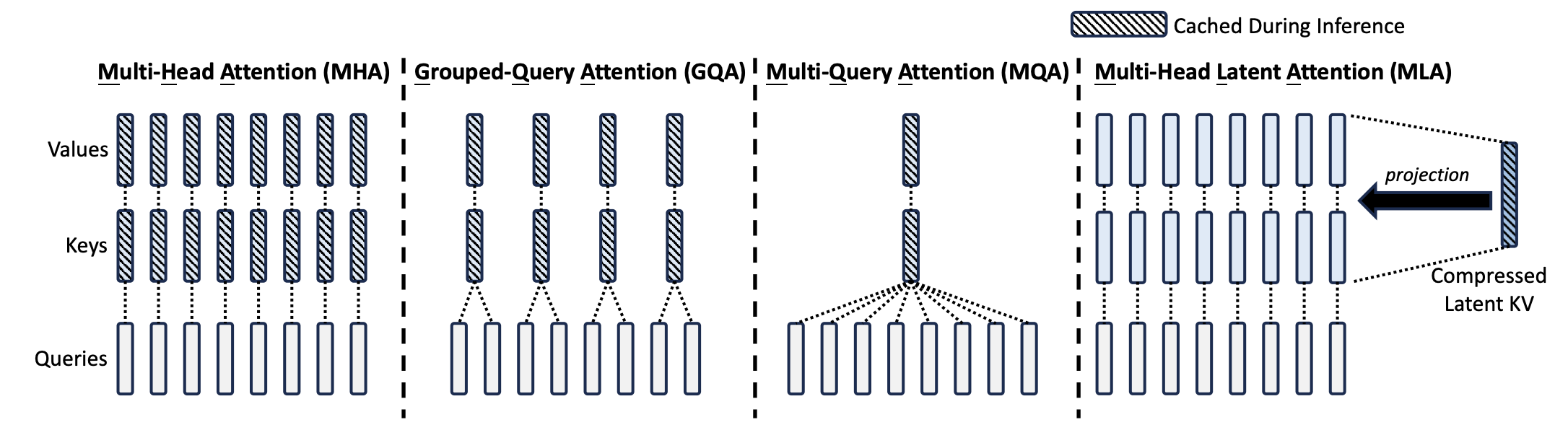
5.0.4 Sliding Window Attention
5.0.5 Flash Attention
5.0.6 Gated Attention
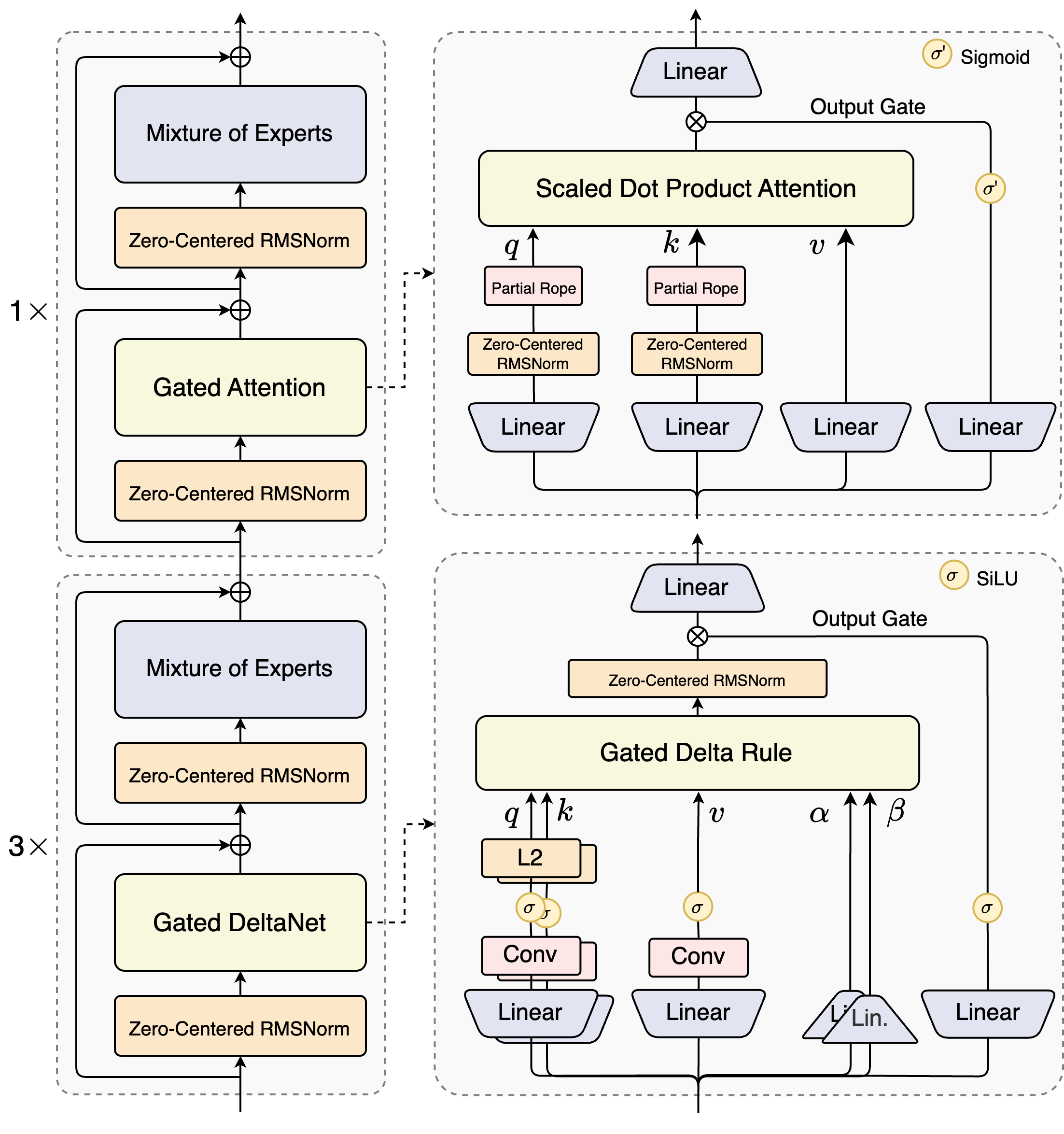
当然,Attention的变形和种类还是很多的,比如:
- Sparse Attention:通过只计算输入序列中部分元素之间的相关性来减少计算复杂度。
- Linear Attention:通过使用线性函数来计算输入序列中各个元素之间的相关性来减少计算复杂度。
- Memory-Augmented Attention:通过引入一个外部的记忆模块来存储输入序列中各个元素的相关信息,从而提高模型的表达能力
在这里就不展开介绍了,不过万变不离其宗,基本上都是在原始的Scaled Dot-Product Attention的基础上进行改进和优化的。
6 Feed-Forward Network (FFN)
7 Mixture of Expert
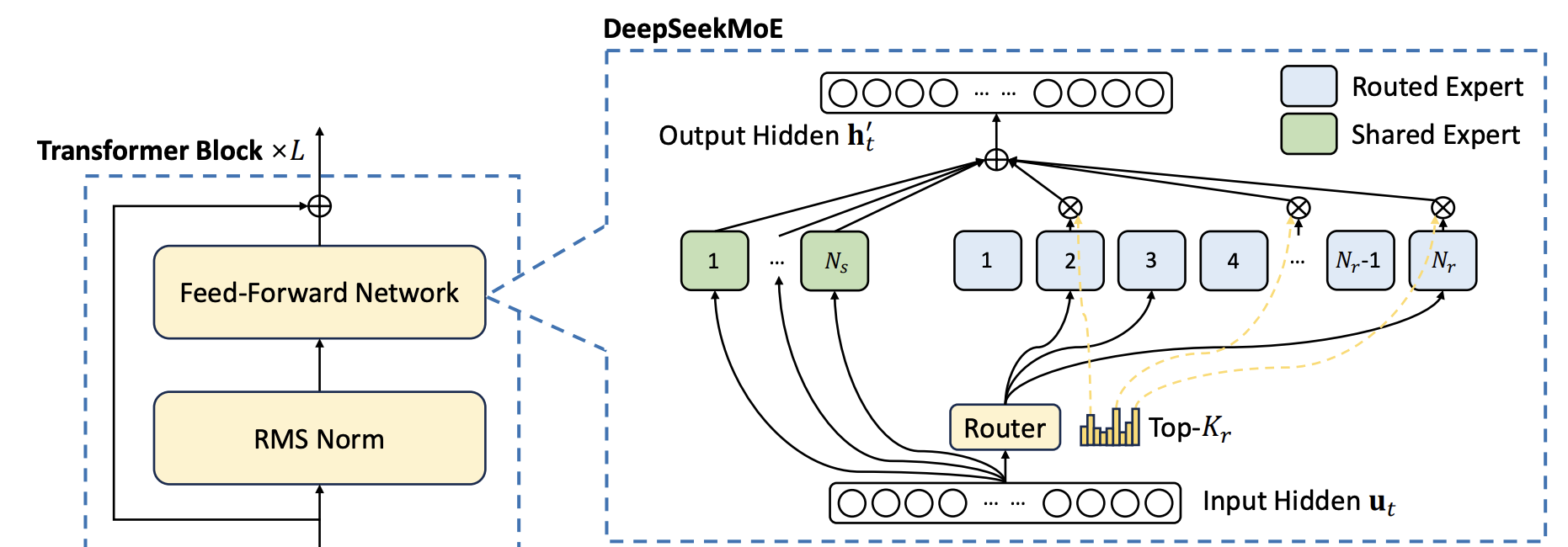
8 Normalization Layer
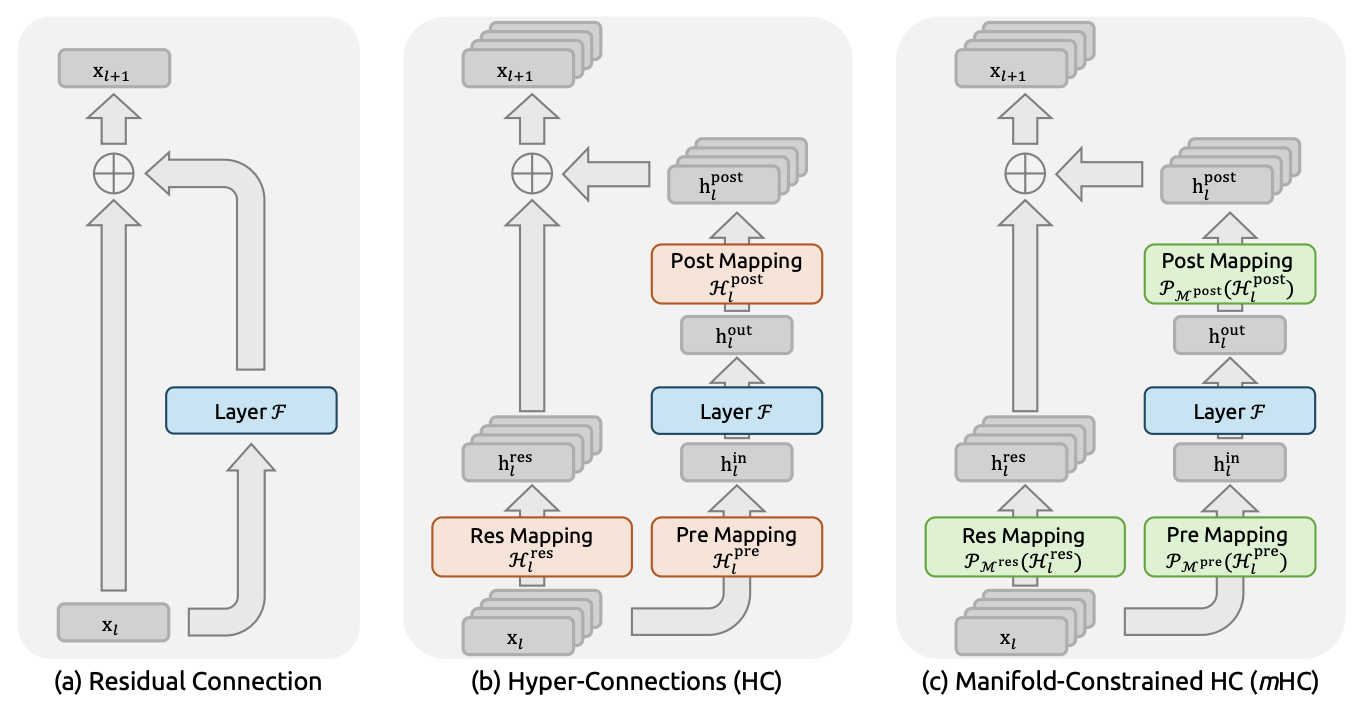
9 Residual Connection
9.1 mHC
9.2 Attention Residual
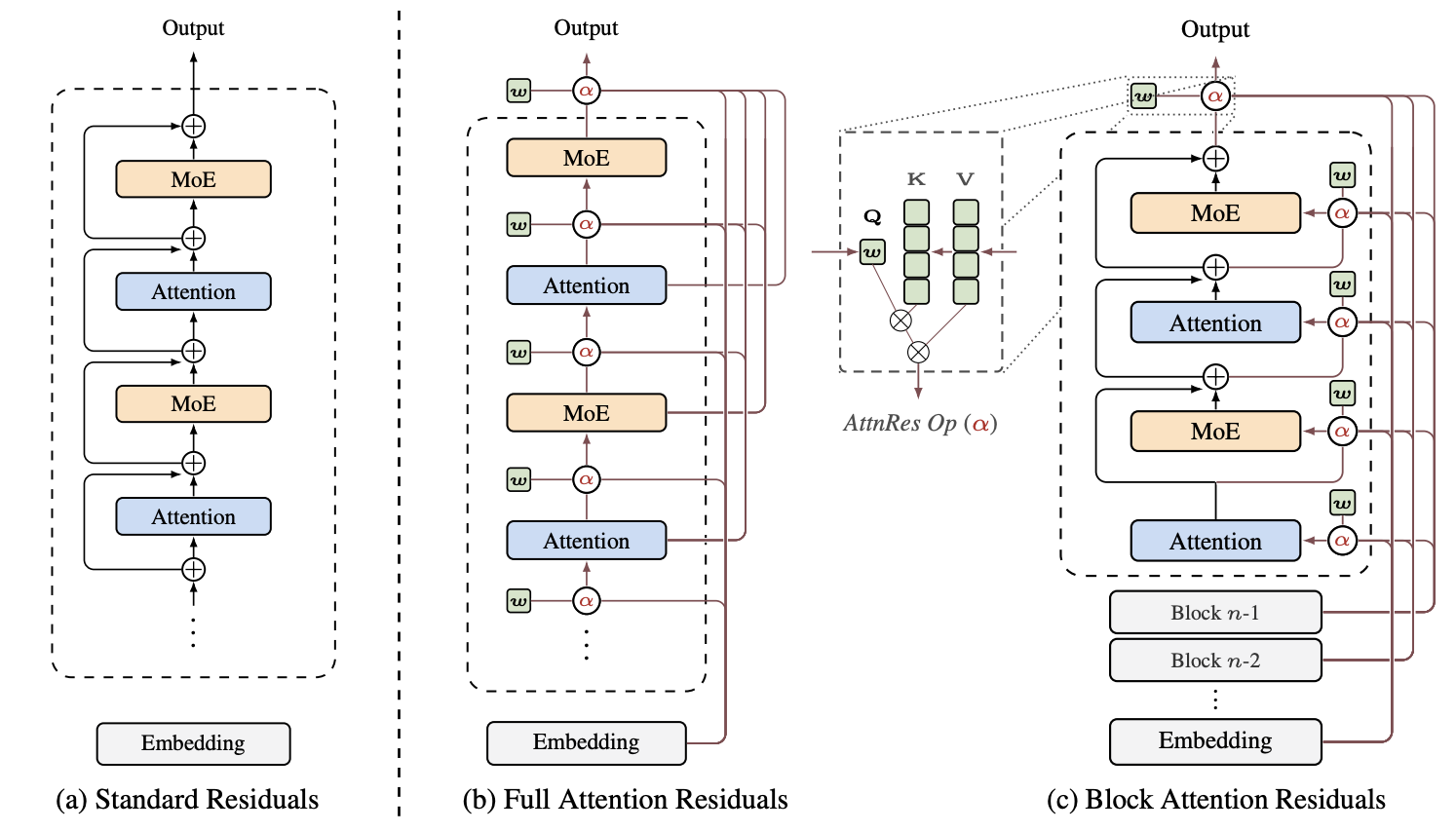
10 Output Layer
11 Other Architectures
11.1 Mamba Architecture
11.2 RetNet Architecture
12 Training Objective
12.1 Cross-Entropy Loss
之前提到的所有模型的训练目标都是基于Cross-Entropy Loss的,也就是最大化输入文本的条件概率。具体来说,给定一个输入文本序列\(X = (x_1, x_2, ..., x_n)\),模型的目标是最大化条件概率\(P(X) = P(x_1)P(x_2|x_1)P(x_3|x_1, x_2)...P(x_n|x_1, x_2, ..., x_{n-1})\)。在训练过程中,我们通常会使用Cross-Entropy Loss来衡量模型生成的文本序列与真实文本序列之间的差异,从而指导模型的优化和训练。数学的表达如下:
\[ \mathcal{L} = -\sum_{i=1}^{n} \log P(x_i|x_1, x_2, ..., x_{i-1}) \]
12.2 Diffusion Loss
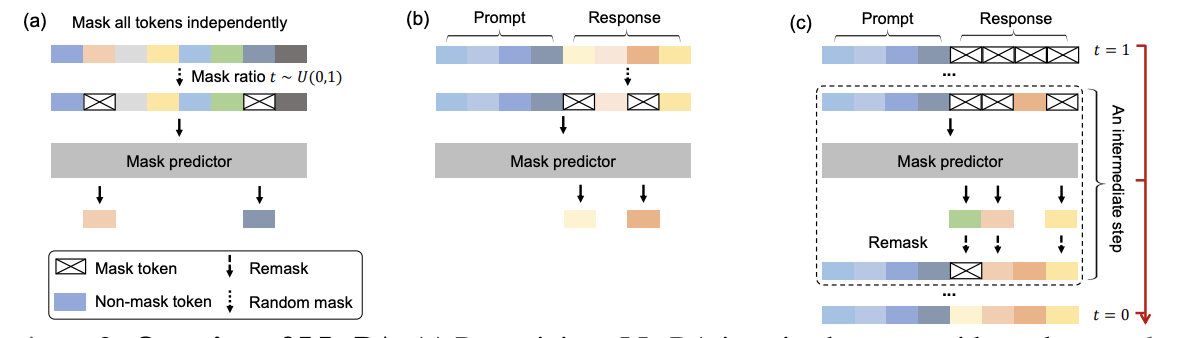
现在的SOTA的模型,最大问题就是Auto-Regressive,要等到生成完一个Token之后才能生成下一个Token,这样的生成方式效率非常低,尤其是当输入文本序列比较长的时候,生成的时间会急剧增加。为了提高模型的生成效率,最近有一些研究提出了一些新的训练目标,比如Diffusion Loss,它通过引入一个噪声分布来模拟输入文本序列中的噪声,从而使模型能够在生成过程中更快地收敛和优化。具体来说,Diffusion Loss通过引入一个噪声分布来模拟输入文本序列中的噪声,从而使模型能够在生成过程中更快地收敛和优化。数学的表达如下:
13 Conclusion
14 In the end
创作不易,如果你觉得内容对你有帮助,欢迎请我 喝杯咖啡/支付宝红包,支持我继续创作!你们的支持是我最大的动力! :)
