A Roadmap of Large Language Models (LLMs)
LLM的发展很快速,迭代的也很快,自从2023年ChatGPT的发布,LLM已经成为了AI领域的热点话题。每年都有新的“SOTA”LLM模型发布。并且随着2026年初OpenClaw的发布,让人们讨论AGI的可能性又一次升温了。LLM的应用也越来越广泛,从文本生成到代码生成,从对话系统到LLM Based Autonomous Agents,LLM正在改变我们与计算机交互的方式。在这篇文章中,我们讲从一个开发者的角度,回顾一下LLM的发展历程,如何训练一个LLM,当前的应用,以及未来的发展趋势。
1 LLM
LLM 可以简单的训练可以简单的分为三个阶段: - Pre-Training:在这个阶段,模型会被训练在一个大规模的文本数据集上,学习语言的基本结构和语义。这通常是一个无监督的过程,模型通过预测下一个词来学习语言的规律。 - Post-Training:在这个阶段,模型会被进一步训练在一个特定的任务或者领域的数据集上,以提高在该任务上的性能。比如Fine-Tuning成为一个对话模型,或者微调模型让他变成安全的模型。
不同的阶段有不同阶段的Evaluation Metric以及挑战,我们会在后面详细介绍。首先我们来看看Pre-Training的阶段。
2 Pre-Training Phase
所有的现在SOTA得LLM,包括LLaMA,Qwen,DeepSeek,Gemini,GPT等,都有一个共同的训练目标:
\[ \mathcal{L} = -\sum_{t=1}^{T} \log P(x_t | x_{<t}) \tag{1}\]
这个也叫做Next Token Prediction Task。用大白话来讲,就是成语接龙:给模型一个文本序列,让它预测下一个词是什么。
接下来我们来看一下训练的模型,基本上现在的所有的模型都是Decoder-Only的Transformer(Vaswani et al. 2023)。这种框架之所以这么流行,是因为它的Parallelism非常好,可以利用GPU的计算能力进行大规模的训练。
2.1 Transformer LLM
Transformer LLM的模型有以下几个核心组件:
- Word Embedding:将输入的文本序列转换成一个连续的向量表示。
- Position Embedding:由于Transformer没有内置的序列信息,所以需要通过位置编码来告诉模型每个词在序列中的位置。
- Attention Mechanism:这是Transformer的核心组件,它允许模型在处理输入序列时关注不同位置的信息。对于Decoder-Only的Transformer来说,通常使用的是Masked Self-Attention,这样模型只能关注当前词之前的信息。
- Feed-Forward Network:这是一个全连接的神经网络,用于处理Attention Mechanism输出的结果。
- Normalization Layers:
2.1.1 Work Embedding Layer
Word Embedding Layer的作用是将输入的文本序列转换成一个连续的向量表示。通常使用的是一个查找表(Lookup Table),将每个词映射到一个固定维度的向量空间中。这个向量空间的维度通常是模型的隐藏层维度,比如512,1024,2048等。通过训练,这些词向量会学习到词与词之间的语义关系,使得相似意义的词在向量空间中更接近。这是所有语言模型的必做的第一步,因为模型只能处理数值数据,所以需要将文本转换成数值表示。Word Embedding Layer就是完成这个任务的组件。
2.1.2 Position Embedding Layer
由于Transformer没有内置的序列信息,所以需要通过位置编码来告诉模型每个词在序列中的位置。常见的Position Embedding方法有两种:一种是绝对位置编码(Absolute Position Encoding),另一种是相对位置编码(Relative Position Encoding)。绝对位置编码为每个位置分配一个唯一的向量,而相对位置编码则关注词之间的相对位置关系。Position Embedding Layer的作用是将这些位置信息与Word Embedding结合起来,使得模型能够理解输入序列的顺序和结构。现在常见的最常见的Position Embedding是RoPE(RoFormerEnhancedTransformer2023sun?),它是一种相对位置编码方法,通过旋转位置编码来捕捉词之间的相对位置信息,同时又输入了绝对位置信息,使得模型能够更好地理解输入序列的结构和关系。
2.1.2.1 Extend Position to Longer Sequence
在训练的时候,我们通常会设置一个最大输入长度,比如2048,4096,8192等。但是在实际应用中,我们可能需要处理更长的输入序列,比如10000,20000,甚至更长。为了让模型能够处理更长的输入序列,我们需要对Position Embedding进行扩展。常见的方法有两种:一种是直接将Position Embedding扩展到更长的序列长度,另一种是使用一些特殊的Position Embedding方法,比如ALiBi(ALiBiAttentionBias2023press?),它通过引入一个线性偏置来捕捉词之间的相对位置信息,使得模型能够处理更长的输入序列。或者Yarn(Peng et al. 2023),它通过引入一个可变长度的Position Embedding来捕捉词之间的相对位置信息,使得模型能够处理更长的输入序列。
2.1.3 Attention Mechanism
Attention Mechanism是Transformer的核心组件,它允许模型在处理输入序列时关注不同位置的信息。对于Decoder-Only的Transformer来说,通常使用的是Masked Self-Attention,这样模型只能关注当前词之前的信息。Attention Mechanism通过计算输入序列中每个词与其他词之间的相关性来生成一个加权的表示,使得模型能够捕捉到输入序列中的长距离依赖关系。这是LLM能够理解和生成自然语言的关键所在。但是,简单的Multi-Headed Attention存在一个显然的问题,就是它的计算复杂度是 \(\mathcal{O}(N^2)\),其中N是输入序列的长度。这对于长序列来说是非常昂贵的,也会随着输入序列长度的增加而迅速增长。因此关于Attention的优化方式层出不穷,主要有以下几种:
- Sparse Attention:通过引入稀疏性来减少计算量,比如只关注输入序列中的一部分位置,或者使用一些特殊的Attention模式,比如Local Attention,Global Attention等。
- Low-Rank Approximation:通过对Attention矩阵进行低秩近似来减少计算量,比如使用一些矩阵分解方法来近似Attention矩阵。
- Memory-Augmented Attention:通过引入一个外部记忆来存储输入序列中的信息,从而减少计算量,比如使用一些特殊的Memory机制来存储输入序列中的信息
- Kernel-Based Attention:通过使用一些特殊的核函数来近似Attention矩阵,从而减少计算量,比如使用一些特殊的核函数来近似Attention矩阵。比如Flash Attention
Grouped Query Attention(GQA)(GroupedQueryAttention2023dao?),它通过将查询向量分成多个组来减少计算量,使得模型能够更高效地处理长序列输入。
2.1.4 Feed-Forward Network
Feed-Forward Network是Transformer中的一个全连接的神经网络,用于处理Attention Mechanism输出的结果。它通常由两个线性层和一个非线性激活函数组成,比如ReLU或者GELU。Feed-Forward Network的作用是对Attention Mechanism输出的结果进行进一步的处理,使得模型能够更好地理解输入序列中的信息。它可以看作是一个特征提取器,通过对Attention Mechanism输出的结果进行非线性变换来提取更高层次的特征,从而提高模型的表达能力和性能。 ### Activation Functions
2.1.4.1 Mixture of Experts (MoE)
Mixture of Experts(MoE)是一种特殊的Feed-Forward Network,它通过引入多个专家网络来提高模型的表达能力和性能。每个专家网络都是一个独立的Feed-Forward Network,它们通过一个门控机制来选择哪个专家网络来处理输入数据。MoE的主要优势在于它能够通过引入多个专家网络来提高模型的表达能力和性能,同时又能够通过门控机制来控制计算量,从而使得模型能够更高效地处理输入数据。MoE在LLM中被广泛使用,比如GLaM(GLaMEfficientMixture2021du?),Switch Transformer(SwitchTransformerScaling2021fedus?),等等。
当一个MoE层有N个专家网路时,每个输入数据只会被分配到其中的K个专家网络进行处理,这样就可以大大减少计算量,同时又能够提高模型的表达能力和性能。这就是为什么很多模型命名为 -20BA2B,其中20B代表模型的参数量,2B代表MoE层中每个输入数据被分配到的专家网络数量。
2.1.5 Normalization Layers
Normalization Layers是Transformer中的一个重要组件,它用于对模型的输入进行归一化处理,从而提高模型的训练稳定性和性能。常见的Normalization方法有Layer Normalization,Batch Normalization,等等。在LLM中,通常使用的是Layer Normalization,它通过对每个样本的特征进行归一化来提高模型的训练稳定性和性能。Normalization Layers的作用是对模型的输入进行归一化处理,使得模型能够更好地学习输入数据中的模式和规律,从而提高模型的表达能力和性能。
2.1.5.1 Position of Normalization
主要有Pre-Norm和Post Norm
2.2 Scaling Laws
当我们提出一个模型,我们通常关心模型的性能和效率。性能通常是指模型在某个任务上的表现,比如准确率,召回率,等等。效率通常是指模型的计算资源消耗,比如训练时间,推理时间,等等。Scaling Laws是指当我们增加模型的参数量或者训练数据量时,模型的性能和效率会如何变化。通常来说,当我们增加模型的参数量或者训练数据量时,模型的性能会提高,但是效率会降低。这就是为什么我们需要在性能和效率之间进行权衡,以找到一个合适的模型规模。
3 Parallelism
LLM之所以这么,并且能够训练这么大规模的模型,主要是因为它的Parallelism非常好。我们可以通过数据并行,模型并行,流水线并行等方式来加速训练过程。
3.1 Data Parallelism
Data Parallelism是指将训练数据分成多个小批次,然后在多个GPU上并行地处理这些小批次。每个GPU都会计算一个小批次的梯度,然后通过通信来同步这些梯度,从而更新模型的参数。Data Parallelism的主要优势在于它能够通过并行处理训练数据来加速训练过程,同时又能够保持模型的性能和效率。
3.2 Model Parallelism
3.3 Pipeline Parallelism
3.4 ZeRO
3.5 FSDP
3.6 4D Parallelism
4 Optimizer
模型训练最重要的组件之一就是Optimizer,它负责更新模型的参数以最小化损失函数。常见的Optimizer有SGD,Adam,AdamW,等等。在LLM中,通常使用的是AdamW,它是一种改进的Adam优化器,通过引入权重衰减来提高模型的泛化能力和性能。Optimizer的选择对于模型的训练效果和效率有着重要的影响,因此在训练LLM时需要仔细选择合适的Optimizer。
4.1 AdamW
4.2 Muon
4.3 SOAP
5 Fine-Tuning
当我们训练完一个LLM之后,我们通常会进行Fine-Tuning来让模型在特定的任务或者领域上表现更好。Fine-Tuning是指在一个预训练的模型基础上,使用一个特定的任务或者领域的数据集来进一步训练模型,以提高在该任务上的性能。Fine-Tuning的主要优势在于它能够通过利用预训练模型中学到的知识来提高在特定任务上的性能,同时又能够减少训练时间和计算资源的消耗。
5.1 LoRA & Q-LoRA
5.2
6 Post-Training
6.1 Supervised Fine-Tuning (SFT)
6.2 Reinforcement Learning with Human Feedback (RLHF)
6.3 Reinforcement Learning with Verified Feedback (RLVF)
6.4 Reinforcement Learning with AI Feedback (RLAIF)
7 Inference & Deployment
在我们训练完,并且Fine-Tuning完一个LLM之后,我们需要将模型部署到生产环境中,以供用户使用。在这个过程中,我们需要考虑模型的Inference效率,安全性,等等。最主要的是模型Inference的效率,因为LLM通常是非常大的模型,具有数十亿甚至数百亿的参数,因此在推理过程中需要消耗大量的计算资源和时间。因此,在部署LLM时,我们需要采取一些优化措施来提高模型的Inference效率,比如使用量化技术,蒸馏技术,等等。
7.1 KV-Cache
7.2 Quantization
7.3 Distillation
8 Continuous Learning
当然,LLM的训练和部署并不是一个一次性的过程,而是一个持续的过程。我们需要不断地收集新的数据,更新模型,以适应不断变化的环境和需求。这就是Continuous Learning的概念,它指的是模型能够在部署后继续学习和适应新的数据和任务,从而保持其性能和效率。
9 LLM Applications
在训练完LLM之后,
9.1 Multi-Modality LLM
最训练完LLM之后,我们可以讲它最为基座,继续训练它,让它能够处理多模态的数据,比如图像,视频,音频等。这些模型通常被称为Multi-Modality LLM,比如GPT-4,Gemini,等等。Multi-Modality LLM的主要优势在于它能够通过处理多模态的数据来提高模型的表达能力和性能,从而更好地理解和生成自然语言。
9.2 LLM-Based Autonomous Agents
这个现在最火的OpenClaw, Claude Code等,都是基于LLM的Autonomous Agents。它们通过利用LLM的强大语言理解和生成能力,结合一些特定的工具和环境交互能力,来实现自主决策和行动。这些Autonomous Agents能够在各种任务中表现出色,比如对话系统,代码生成,等等。LLM-Based Autonomous Agents的主要优势在于它们能够通过利用LLM的强大语言理解和生成能力来实现自主决策和行动,从而更好地满足用户的需求。 它利用LLM作为它的大脑
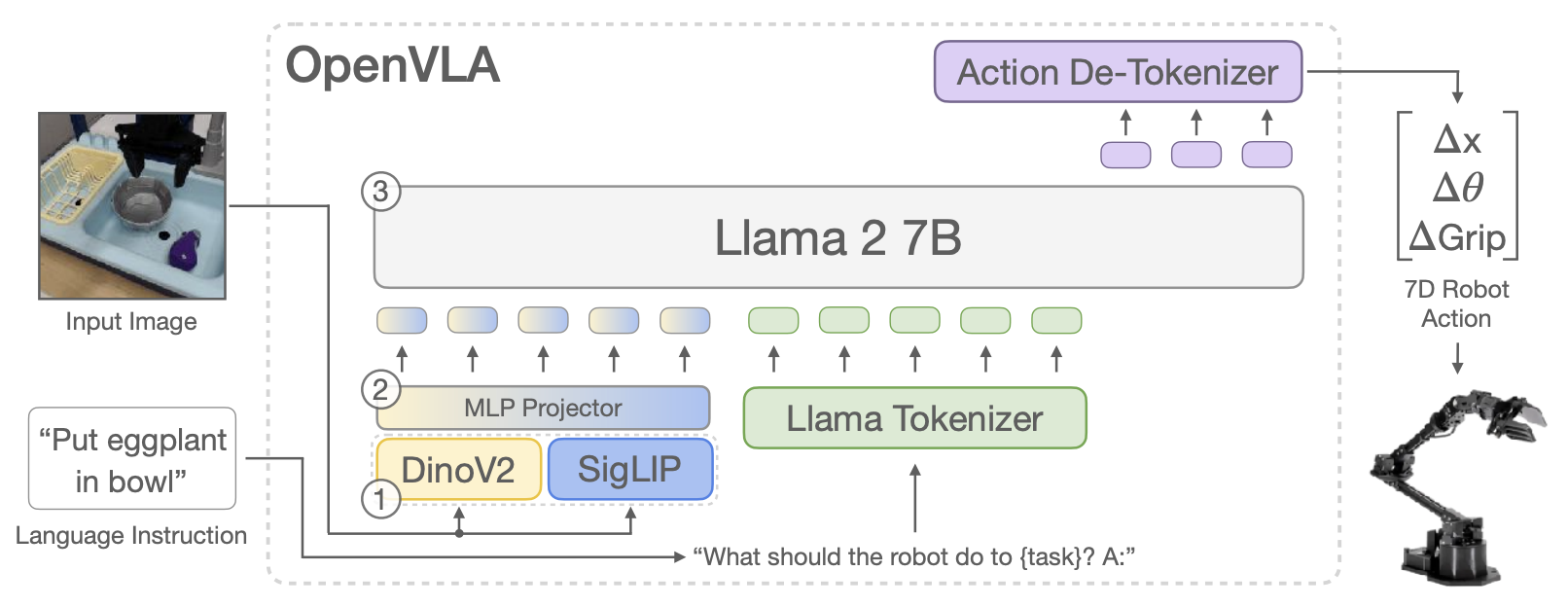
9.3 Vision Language Action(VLA) Models
10 Future of LLM
现在LLM的已经非常强大了,但是仍然还有很多的局限性,比如Inference的效率,不管怎么优化,LLM的Inference效率仍然是一个瓶颈。还有就是LLM的安全性和伦理问题,LLM可能会生成有害的内容,或者被恶意使用。
12 In the end
创作不易,如果你觉得内容对你有帮助,欢迎请我 喝杯咖啡/支付宝红包,支持我继续创作!你们的支持是我最大的动力! :)
