Lecture 03&04: Transformer LLM Model Architecture & MoE
在Lecture03中,我们会先介绍Transformer Based LLM的模型架构, 包括Normalization Layer, Position Embedding, Feed Forward Network 等。并且告诉大家一些常见的参数设置和一些训练稳定的技巧。在Lecture04中,我们会介绍Transformer中Attention Layer的不同变体,包括Linear Attention,Sparse Attention等。最后我们会介绍Mixture of Experts (MoE) 模型的基本概念,架构组成部分以及训练方法等内容。
1 Transformer Based LLM Architecture Overview
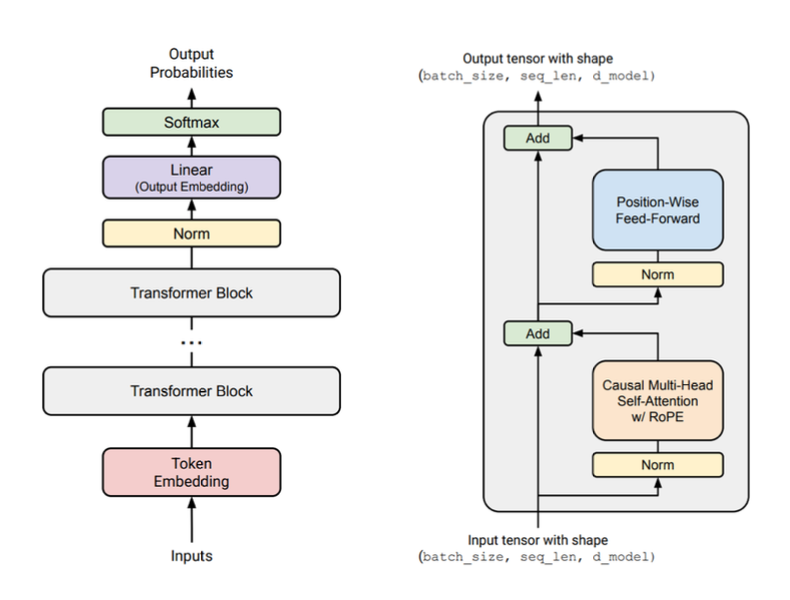
Transformer(Vaswani et al. 2023)的基本架构如下图所示:
包括Encoder和Decoder两部分,现代的LLM模型,基本上都是基于Decoder-only的架构,也就是说,只有Decoder部分被保留下来,而Encoder部分被移除掉了。Decoder-only架构的Transformer模型主要由以下几个组件组成:
- Input Embedding Layer: 将输入的token转换成一个高维的向量表示。
- Position Embedding Layer: 为输入的token添加位置信息,使模型能够感知序列中各个token的相对位置。
- Transformer Block: 包含多个Attention Layer和Feed Forward Network (FFN) Layer的堆叠,每个Transformer Block都包含一个Normalization Layer。
- Output Head: 将Transformer Block的输出转换成最终的预测结果,通常是一个softmax层,用于预测下一个token的概率分布。
- Residual Connection: 在Transformer Block中,Attention Layer和FFN Layer之间通常会有一个Residual Connection,用于缓解深层网络中的梯度消失问题。
- Normalization Layer: 在Transformer Block中,通常会有一个Normalization Layer,用于提升模型的训练稳定性和性能。
整体的架构如下图所示:
随着LLM的流行,Transformer-Decoder 架构也经历了很多的演变和改进,除了基本的框架没有改变之外,基本上每个组件都经历了很多的改进和优化,比如说:
- Normalization Layer的位置和形式:从Post-Normalization到Pre-Normalization,从LayerNorm到RMSNorm。
- Attention Layer的变体:从传统的全局Attention到Linear Attention,Sparse Attention等。
- Activation Function的变体:从ReLU到GeLU,再到Gated Activation Function。
- Transformer Block的设计:从Serial Layer到Parallel Layer。
等等。在接下来的内容中,我们会逐一介绍这些组件的改进和优化,以及它们背后的原理和实现细节。我们首先来看一下Normalization Layer的位置和形式。
2 Normalization Layer
2.1 Position of Normalization
在原本的Transformer(Vaswani et al. 2023)架构中,Normalization Layer通常放在Attention Layer和FFN Layer的后面,这种设计被称为Post-Normalization。然而,在实际训练过程中,Post-Normalization架构往往会遇到训练不稳定的问题,learning hyper-parameters 调节复杂的问题。为了克服这个问题,研究人员提出了Pre-Normalization(Xiong et al. 2020)架构,即将Normalization Layer放在Attention Layer和FFN Layer的前面,如下图所示:
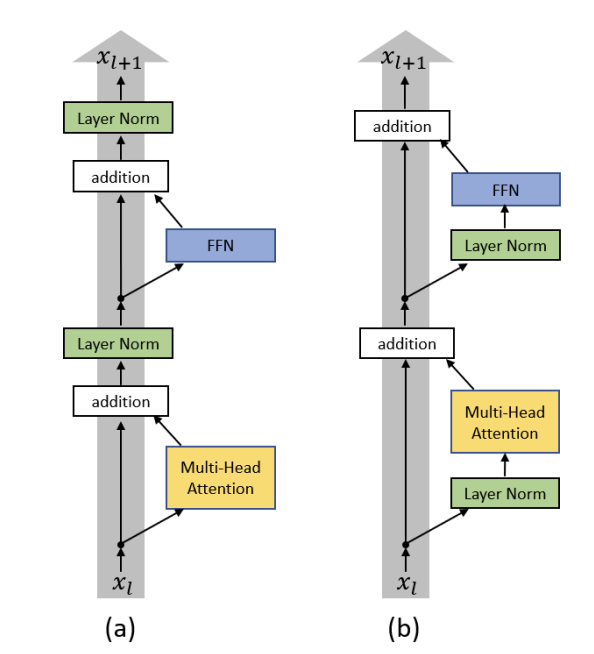
在Pre-Norm最先提出的时候,一开始是为了缓解Learning Rate Schedule的问题(Nguyen and Salazar 2019), 如下图所示:
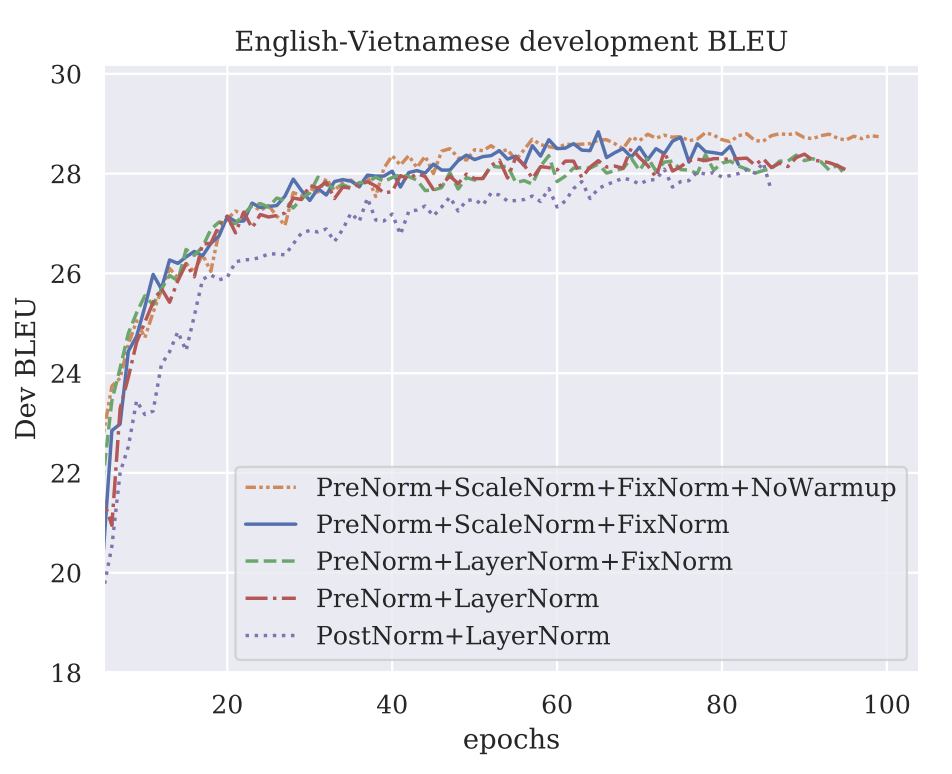
但是,后来研究人员发现,Pre-Normalization架构的优势不仅仅在于缓解Learning Rate Schedule的问题,还在于它能够提升模型的训练稳定性和性能。尤其是在解决:
- Graident attenutation: 在训练的过程中,模型的梯度可能会出现衰减(Attenuation),导致训练不稳定。
- Gradient Spike: 在训练过程中,模型的梯度可能会出现突然的爆炸(Spike),导致训练不稳定。
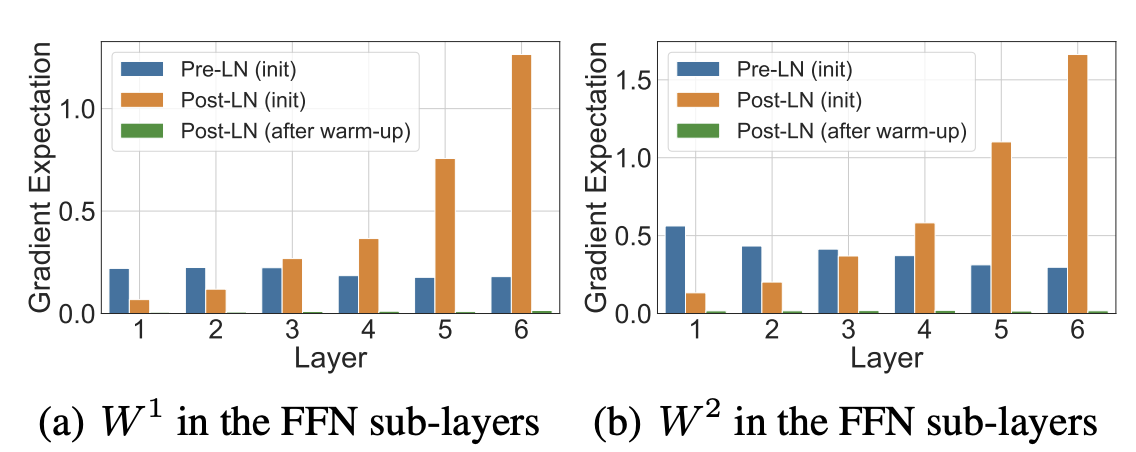
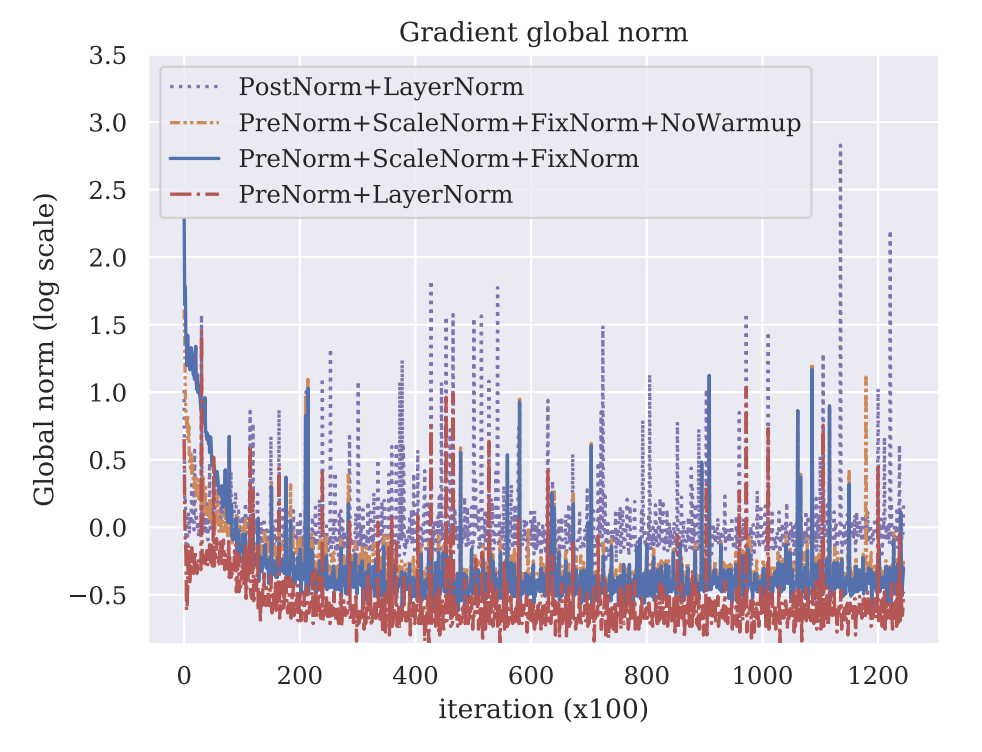
2.1.1 Why Pre-Normalization can improve training stability?
在了解为什么Pre-Normlaization能够提升训练稳定性之前,我们需要先来了解一下什么是Residual Connection(He et al. 2015)。Residual Connection是一种在神经网络中常用的结构,它通过将输入直接添加到输出中,来缓解深层网络中的梯度消失问题。它主要的贡献是:让Gradient能够直接从输出层反向传播到输入层,从而提升训练的稳定性。举个简单的例子:
\[ y = F(x) + x \tag{1}\]
当Gradient从输出层反向传播到输入层时,它可以直接通过Residual Connection传递,而不需要经过复杂的非线性变换:
\[ \begin{split} \frac{\partial L}{\partial x} &= \frac{\partial L}{\partial y} \cdot \frac{\partial y}{\partial x} \\ &= \frac{\partial L}{\partial y} \cdot ( \frac{\partial F(x)}{\partial x} + I ) \\ &= \frac{\partial L}{\partial y} \cdot \frac{\partial F(x)}{\partial x} + \textcolor{red}{\frac{\partial L}{\partial y}} \\ \end{split} \tag{2}\]
可以看到,Residual Connection中的梯度 \(\frac{\partial L}{\partial y}\) 可以直接传递到输入层,而不需要经过复杂的非线性变换,从而提升了训练的稳定性。
TL;DR: Pre-Norm 的好处
Pre-Normalization的好处主要体现在以下几个方面:
- 提升训练稳定性:Pre-Normalization可以缓解梯度衰减和梯度爆炸的问题,从而提升模型的训练稳定性。
- 减少Hyper-parameter Tuning的难度:Pre-Normalization可以缓解Learning Rate Schedule的问题,从而减少模型训练时的Hyper-parameter Tuning的难度。
- 提升模型性能:Pre-Normalization可以提升模型的表达能力,从而提升模型的性能。
从Pre-Norm的优势可以看出:要保持Residual Connection尽可能的“干净”,也就是说,尽量减少Residual Connection中非线性变换的影响,从而让Gradient能够更直接地传递到输入层。
当然,除了Pre-Norm和Post-Norm之外,还涌现出了其他的Normalization Layer的位置设计,比如Sandwich Normalization(Ding et al. 2021),通过在Attention Layer和FFN Layer的前后都添加Normalization Layer来提升模型的训练稳定性和性能:
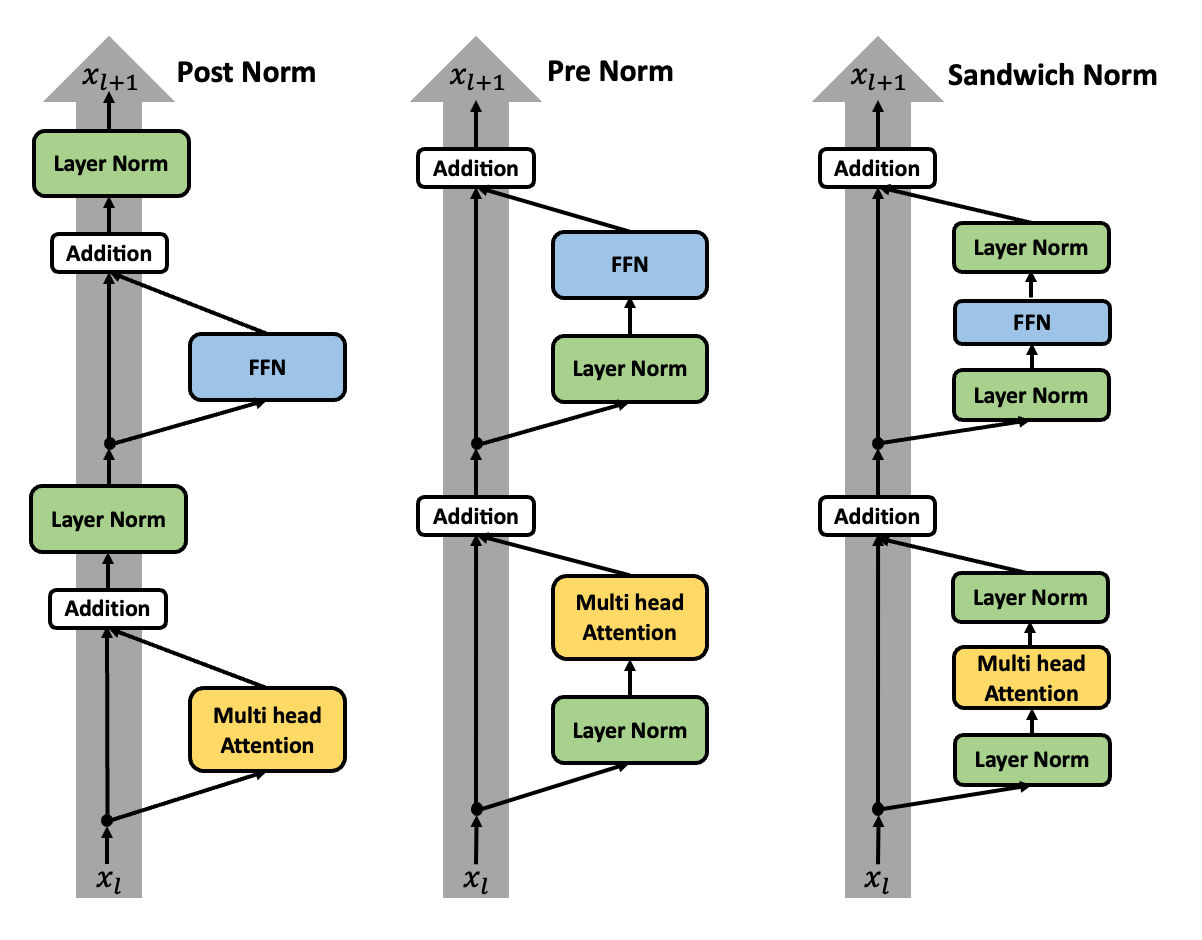
这个训练方式一开始由CogView(Ding et al. 2021)提出,用于训练文本到图像的生成模型,不过并没有在主流的LLM模型中得到广泛的应用,主要原因是它增加了模型的计算量和参数量,从而增加了训练的复杂性和成本。
2.2 Form of Normalization
在了解了Normalization Layer的位置之后,我们接下来来了解一下Normalization Layer的形式。在Transformer的论文中,作者使用的是Layer Normalization(Ba, Kiros, and Hinton 2016), 公式如下:
\[ \text{LayerNorm}(x) = \frac{x - \mathbb{E}[x]}{\sqrt{\text{Var}[x] + \epsilon}} \cdot \gamma + \beta \tag{3}\]
其中,\(x\) 是输入,\(\gamma\) 和 \(\beta\) 是可学习的参数,与输入的维度相同, 表示缩放和平移的参数。LayerNorm是可行的,但是在实际应用中,研究人员发现,使用RMSNorm(Zhang and Sennrich 2019)可以进一步提升模型的性能。RMSNorm的公式如下:
\[ \text{RMSNorm}(x) = \frac{x}{\sqrt{\|x\|^2 + \epsilon}} \cdot \gamma \tag{4}\]
其中, \(\|x\|^2=\frac{1}{d}\sum_{i=1}^{d} x_i^2\) 是输入的平方和,\(d\) 是输入的维度,\(\gamma\) 是可学习的参数,表示缩放的参数。RMSNorm相对于LayerNorm的优势在于,它不需要计算输入的均值,从而减少了计算量,并且在某些情况下可以提升模型的性能,主要有以下几个原因:
- Fewer Operation: RMSNorm不需要计算输入的均值,因此减少了计算量。
- Fewer Parameters: RMSNorm没有平移参数\(\beta\),因此减少了模型的参数量。
我们先来看一下几个常见的算子:
- Tensor Contraction:指带有“求和收缩”的张量运算,本质上就是矩阵乘、批量矩阵乘、线性层这类操作。比如 Transformer 里的 \(XW\)、attention 里的 \(QK^\top\)都属于这一类。
- Stat. normalization:指统计归一化操作,也就是需要先计算均值、方差或范数,再做归一化的操作。典型例子有 LayerNorm、BatchNorm、RMSNorm。
- Element-wise:指逐元素的操作,比如激活函数、缩放和平移等。
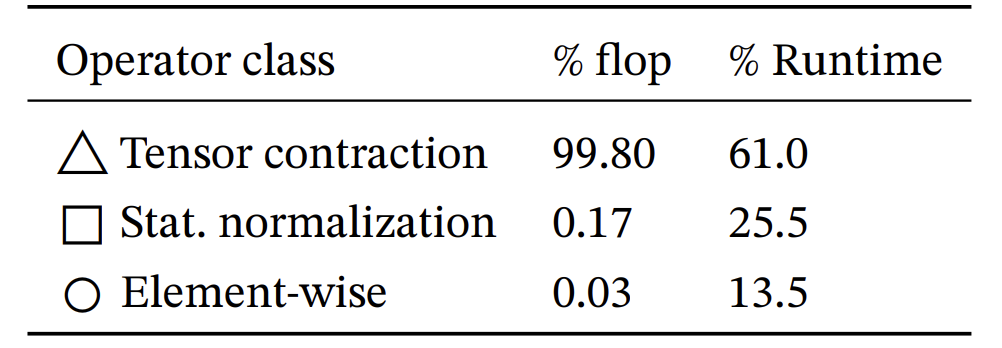
可以看到,尽管 Stat. normalization 需要的Flops比较少,但是wall-clock time占比却并不少,其主要原因是Data Movement(从内存到计算单元的传输)却占了很大一部分,因此减少Normalization Layer的参数量,可以显著提升训练的效率,这就是为什么RMSNorm更受欢迎的原因之一。
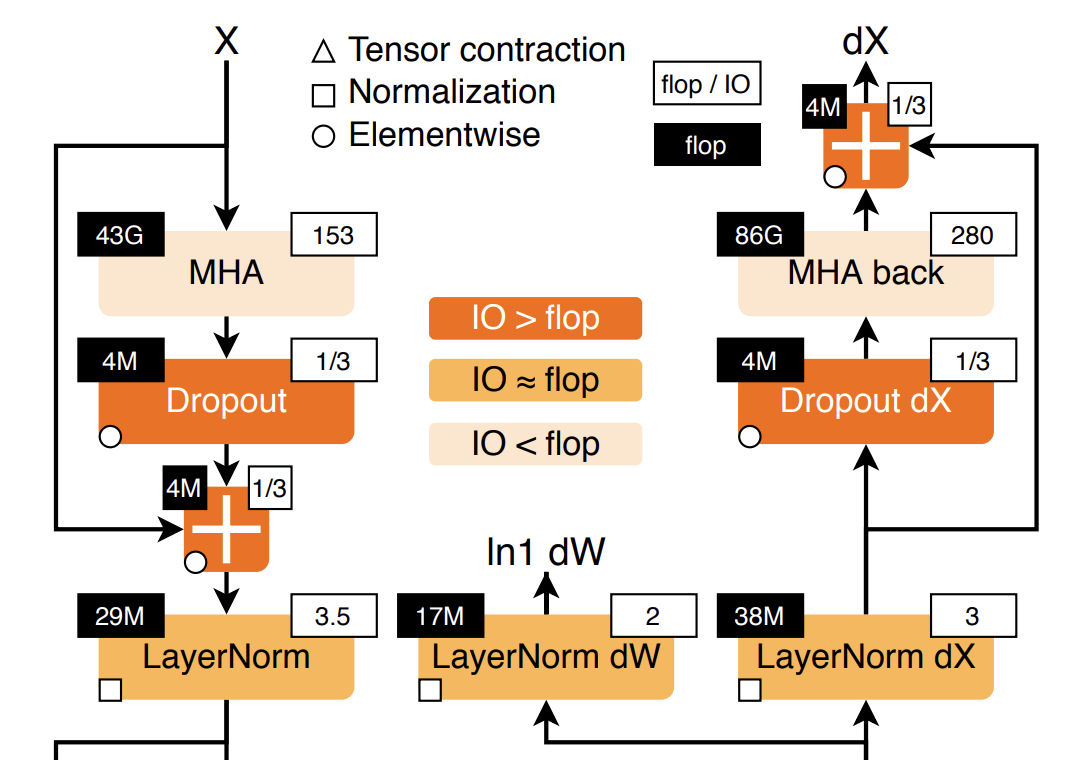
这个概念,同时也在Feed Forward Network体现,通过移除bias项,来减少数据移动的数量,提高训练效率。
TL;DR: Normalization Summary
现在大多数模型都会采用 非 residual stream 上的归一化,通常就是 PreNorm,也就是先做归一化再进入 attention 或 FFN。这样做的直觉是:尽量保留 residual connection 直接传递信息和梯度的好处,因此梯度传播通常更平稳、训练中的 spike 更少。有些模型还会在 residual stream 外再额外加一层 norm 来进一步稳定训练。
另外,实践里很多模型已经从 LayerNorm 转向 RMSNorm。原因是 RMSNorm 实际效果通常和 LayerNorm 差不多,但结构更简单、需要处理的参数更少,因此能减少一些实际训练时间开销。与此同时,现在大家也更倾向于 去掉 bias,因为它带来的收益通常不够大,不太值得增加额外的参数和计算。
3 Activations
Activation Function 通过引入非线性变换来增强模型的表达能力。在 Transformer 中,早期常见的激活函数是 ReLU,但在实际应用中,研究人员发现 GeLU 往往效果更好,因此在现代大语言模型中被更广泛采用。相比 ReLU 直接将负值截断为 0,GeLU 会根据输入大小对信息进行更平滑的保留与抑制,使模型优化过程更加稳定,也通常能带来更好的性能表现:
\[ FF(x) = \max(0, xW_1)W_2 \tag{5}\]
\[ FF(x) = \text{GeLU}(xW_1)W_2 \quad \text{where} \quad \text{GeLU}(x) = x \Phi(x) \tag{6}\]
3.1 Gated Activations(*GLU)
研究人员发现,通过引入Gated Activation Function (Shazeer 2020),可以进一步提升模型的性能。Gated Activation Function通过引入一个门控机制,来控制信息的流动。
Gated Linear Units (GLU), a neural network layer defined as the componentwise product of two linear transformations of the input, one of which is sigmoid-activated. GLU Variants Improve Transformer p.1
GLU的公式如下: \[ GLU(x) = \sigma(xW) \otimes (xV) \tag{7}\]
通过改变不同的激活函数可以得到不同的Gated Activation Function的变体,比如说:
\[ \begin{split} \mathrm{FFN}_{\mathrm{GLU}}(x, W, V, W_2) &= \left(\sigma(xW) \otimes xV\right) W_2 \\ \mathrm{FFN}_{\mathrm{Bilinear}}(x, W, V, W_2) &= \left(xW \otimes xV\right) W_2 \\ \mathrm{FFN}_{\mathrm{ReGLU}}(x, W, V, W_2) &= \left(\max(0, xW) \otimes xV\right) W_2 \\ \mathrm{FFN}_{\mathrm{GEGLU}}(x, W, V, W_2) &= \left(\mathrm{GELU}(xW) \otimes xV\right) W_2 \\ \mathrm{FFN}_{\mathrm{SwiGLU}}(x, W, V, W_2) &= \left(\mathrm{Swish}_1(xW) \otimes xV\right) W_2 \end{split} \tag{8}\]
其中最常见的就是SwiGLU,SwiGLU使用了Swish作为激活函数:
\[ \mathrm{Swish}_\beta(x) = \frac{x}{1 + e^{-\beta x}} \tag{9}\]
需要注意的是,随着引入Gated Activation Function,模型的参数量也会增加,因此在实际应用中,需要权衡模型的性能和计算资源的限制。 比如downscale \(d_{ff}\) by \(\frac{2}{3}\),来抵消GLU引入的参数增加。
4 Serial vs. Parallel Layers
现在的LLM模型,都是Serial的,也就是说,Attention Layer和FFN Layer是串行的,每个token先经过Attention Layer,再经过FFN Layer。这种明显有个问题就是,无法充分利用计算资源,尤其是在分布式训练环境下。为了克服这个问题,研究人员提出了Parallel Layers的设计,即将Attention Layer和FFN Layer并行化,从而提升模型的训练效率。Parallel Layers的设计可以让模型在每一步计算中同时利用Attention Layer和FFN Layer,从而更好地利用计算资源,提高训练效率。
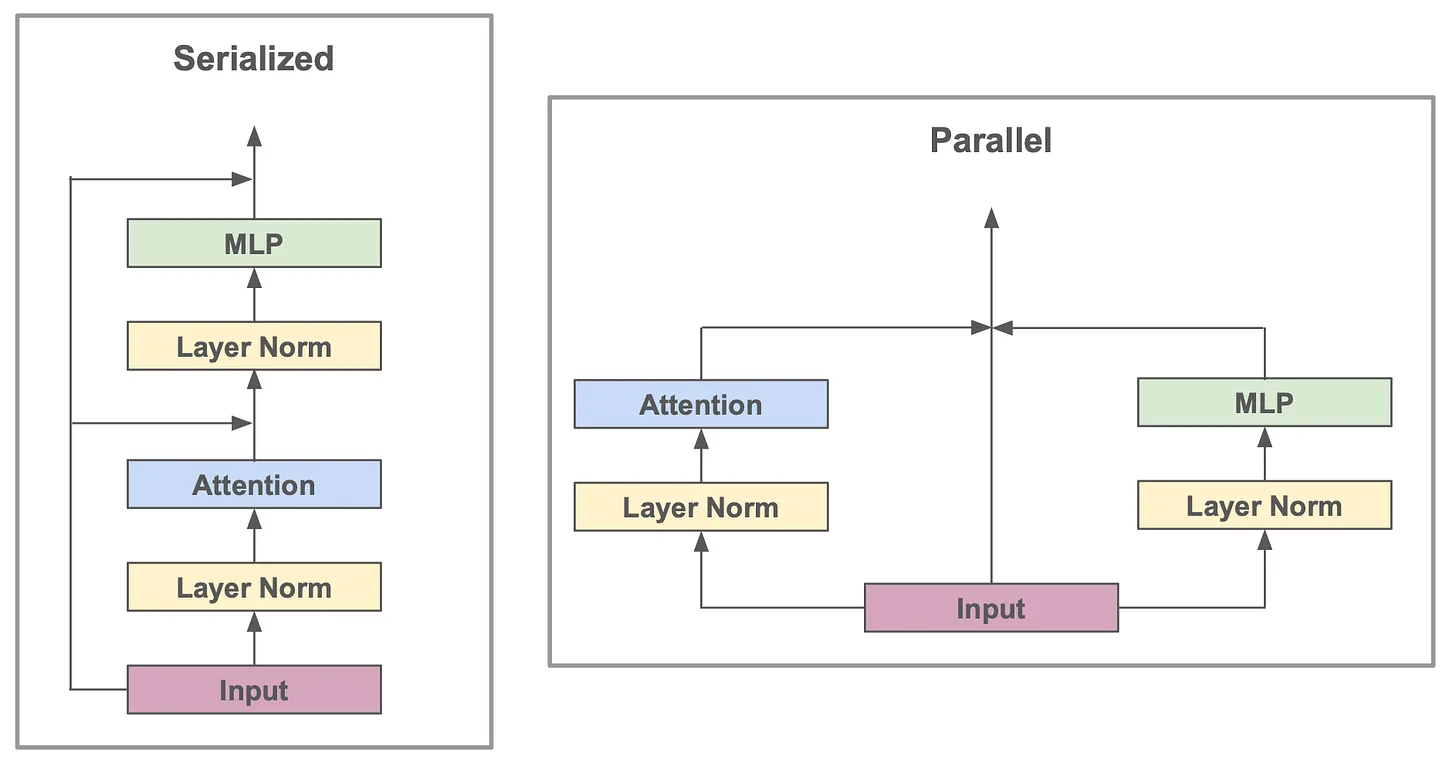
比如 PaLM(Chowdhery et al. 2022) 就采用了Parallel Layers的设计,在每个Transformer Block中,Attention Layer和FFN Layer是并行的,如下图所示:

这样设计的好处就是,如果设计的好,许多操作可以fused,具体来说:
- Normalization Layer:因为两个分支的输入一样,没必要各算各的Normalization,可以fused成一个Normalization Layer。
- Matrix multiplies: 如果Attention和FFN都基于相同的输入,那么它们的矩阵乘法也可以fused成一个矩阵乘法,比如:\(h [W_Q \| W_K \| W_V \| W_{\text{ffn}}]\), 通过 GEMM 做完,再把输出切块分给不同分支。
5 Position Embedding
Position Embedding是Transformer模型中的一个重要组件,它通过为输入的token添加位置信息,来帮助模型理解序列数据的结构。在原始的Transformer架构中,作者使用了Sinusoidal Position Embedding(Vaswani et al. 2023),之后涌现出来许多种不同的Position Embedding的设计,主要可以分为以下几类:
- Sine Embeddings
- Absolute Embeddings
- Relative Embeddings
在这里主要介绍RoPE(Su et al. 2023)
5.1 RoPE
RoPE(Su et al. 2023)是一种基于旋转的相对位置编码方法,它通过对输入的token进行旋转变换,来引入位置信息。RoPE的核心思想是:通过对输入的token进行旋转变换,使得模型能够感知序列中各个token的相对位置,并且保留了Absolute Positional Embedding的优势。具体来说,RoPE的公式如下:
\[ \begin{split} \text{RoPE}(x, p) &= x \cdot R(p) \\ R(p) &= \begin{bmatrix} \cos(p) & -\sin(p) \\ \sin(p) & \cos(p) \end{bmatrix} \end{split} \tag{10}\]
RoPE有:
- Relative Position Embedding的优势:两个模型token之间的相对位置关系是由它们之间的旋转角度决定的。
- Absolute Positional Embedding的优势:通过旋转矩阵 \(R(p)\),模型可以感知每个token的绝对位置。
RoPE的旋转实现如下图所示:
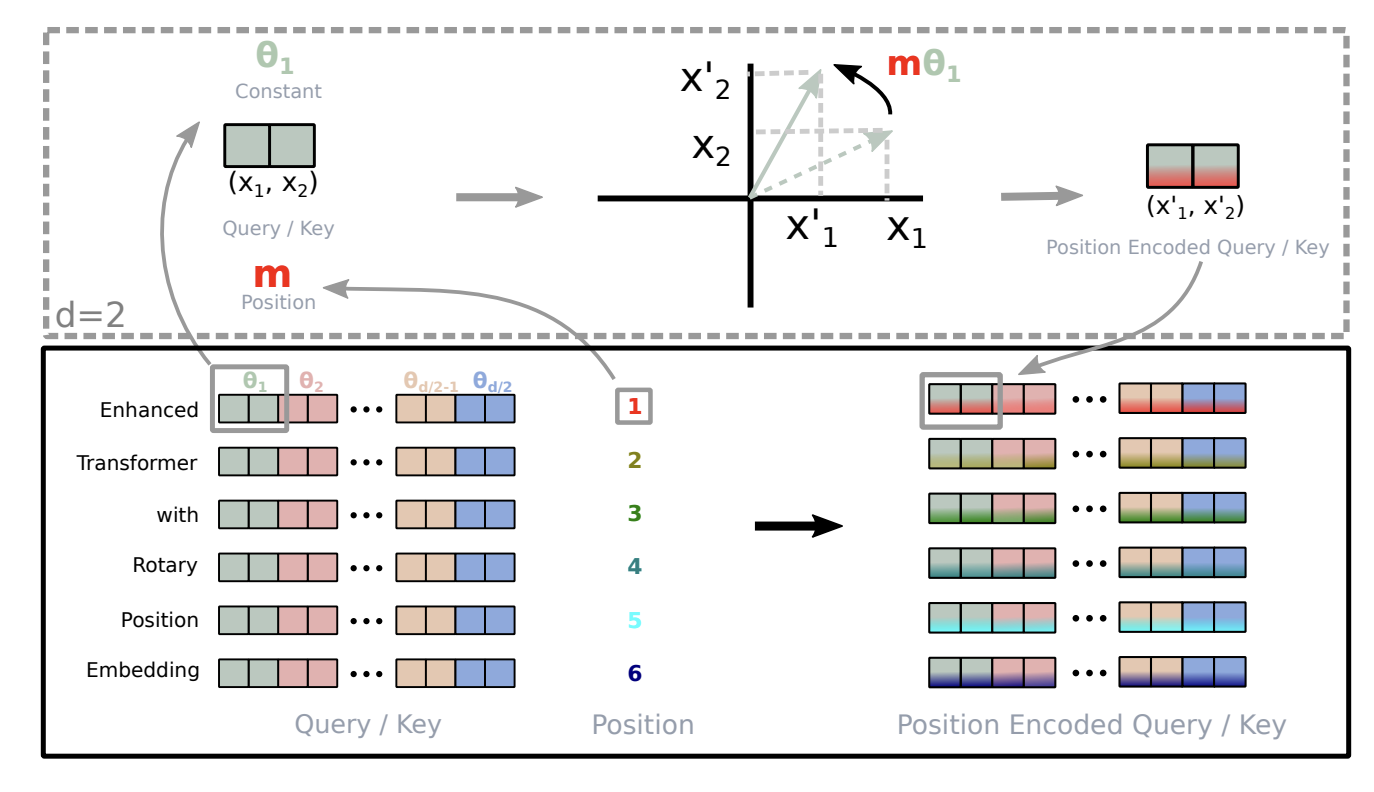
对于一个\(d_{model}\)维的输入向量,我们可以将其分成\(d_{model}/2\)个二维的子向量,然后对每个子向量进行旋转变换:
\[ R_{\Theta,m}^{d} = \begin{pmatrix} \cos m\theta_1 & -\sin m\theta_1 & 0 & 0 & \cdots & 0 & 0 \\ \sin m\theta_1 & \cos m\theta_1 & 0 & 0 & \cdots & 0 & 0 \\ 0 & 0 & \cos m\theta_2 & -\sin m\theta_2 & \cdots & 0 & 0 \\ 0 & 0 & \sin m\theta_2 & \cos m\theta_2 & \cdots & 0 & 0 \\ \vdots & \vdots & \vdots & \vdots & \ddots & \vdots & \vdots \\ 0 & 0 & 0 & 0 & \cdots & \cos m\theta_{d/2} & -\sin m\theta_{d/2} \\ 0 & 0 & 0 & 0 & \cdots & \sin m\theta_{d/2} & \cos m\theta_{d/2} \end{pmatrix} \tag{11}\]
其中,\(m\) 是token之间的相对位置,\(\theta_i\) 是一个预定义的角度,通常设置为 \(\theta_i = 10000^{-2(i-1)/d}\)。
6 Hyperparameters
在了解了基本的框架之后,我们看一下一些重要的Hyperparameters,包括:
- Attention Head Number
- FFN Hidden Size
- Number of Layers
- Vocab Size
- …
6.1 Model-Dimension Ratio
Model Dimension Ratio 是指模型在FFN中,\(d_{ff}\) 与 \(d_{model}\) 的比例。一般来说,\(d_{ff}\) 通常设置为 \(4d_{model}\),这是因为较大的FFN Hidden Size可以提升模型的表达能力,从而提升整体性能。不过,也是有几个特例,比如:
- 像我们之前提到的*GLU模型中,为了抵消GLU引入的参数增加,通常会将\(d_{ff}\)设置为\(\frac{8}{3}d_{model}\)。
- T5模型, \(d_{ff} = 64d_{model}\)
这个4倍的比例,通过实验得出来的,如下图所示:
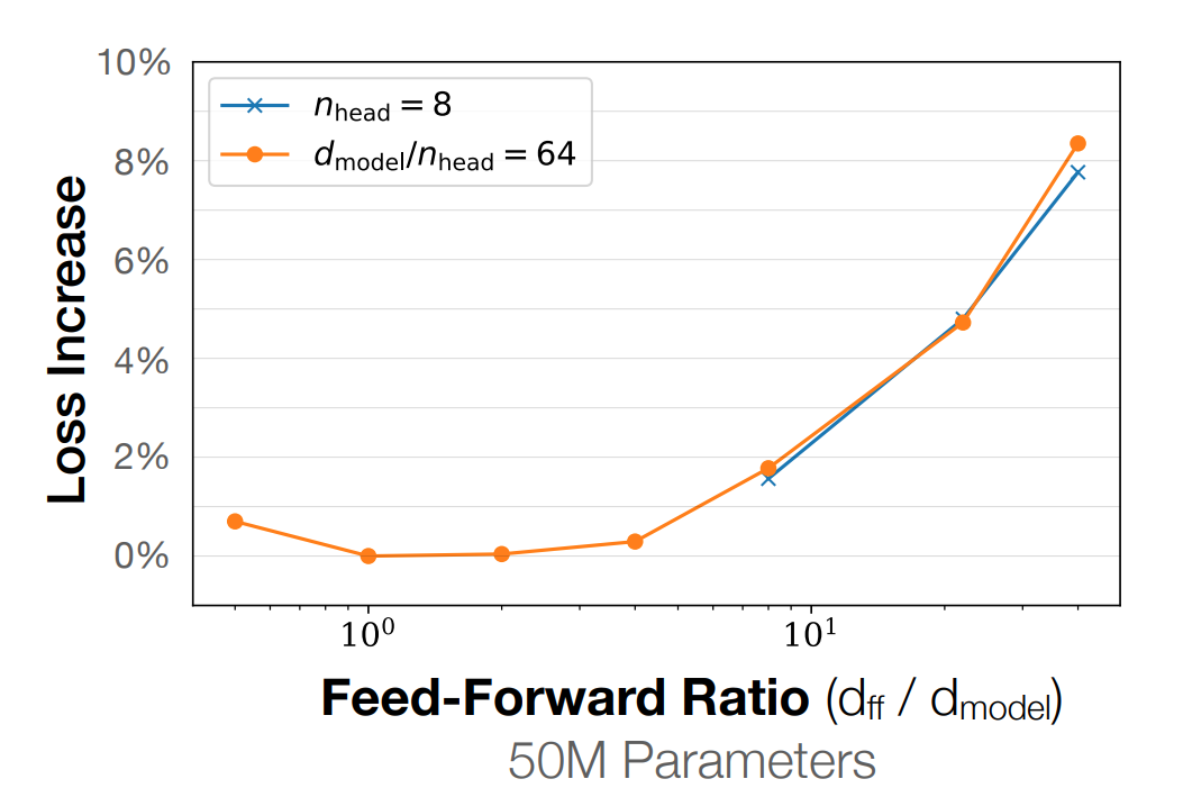
当model-dimension ratio在1-10之间,模型的性能表现最好。
6.2 Attention Head Dimension
在几乎所有的默认的Transformer中,\(d_{head} = d_{model} / \text{num\_heads}\),也就是说,Attention Head Dimension是由Model Dimension和Attention Head Number共同决定的。但事实上,我们可以设置任何大小的\(d_{head}\),只不过大家约定俗成的做法是保持$d_{head} = d_{model} / 。
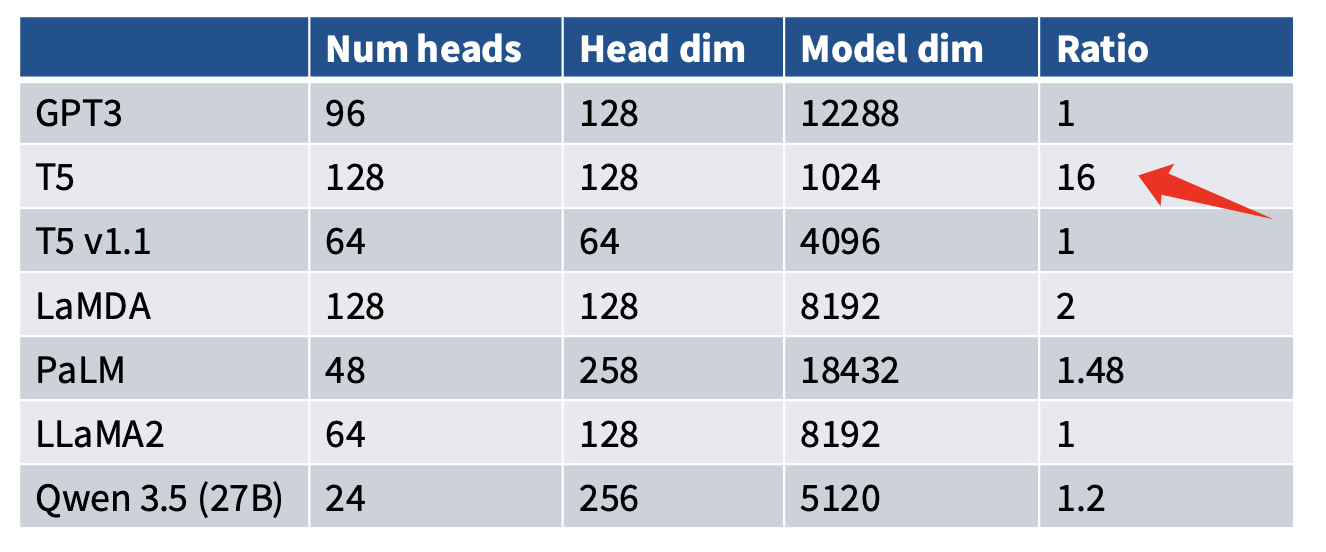
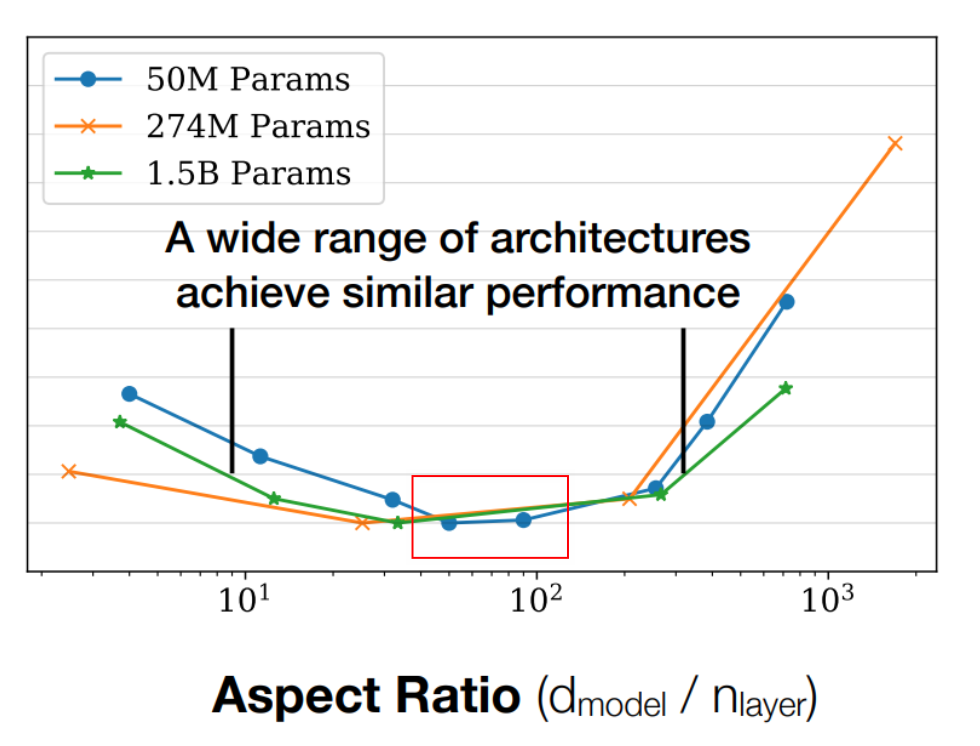
6.3 Aspect Ratio
Aspect Ratio 指的是Number of Layers与Model Dimension的比例:
- 越深的模型,越难并行训练,并且Inference时候的Latency也会增加。
6.4 Vocab Size
Vocab Size for 单一语言模型,不需要太大,但是对于多语言模型,尤其是包含了很多低资源语言的模型,通常需要更大的Vocab Size来覆盖更多的词汇,从而提升模型的性能。
6.5 Dropout & Other Regularization
Dropout是一种常用的正则化方法,它通过在训练过程中随机丢弃一部分神经元来防止模型过拟合。但是在训练模型的时候,Data 的数量大于模型的参数量时,过拟合通常不是一个大问题,因此在训练大规模模型时,很多人不选择使用Dropout,但是还会使用Weight Decay。
但是很多人使用Weight Decay的目的,并不是出于Regularization,而是把它看作是Optimizer的一部分。
7 Stability Tricks
接下来我们来介绍一些稳定训练的技巧,来避免训练过程中出现Loss Spike或者Gradient Spike等问题。我们先来看一下什么是Loss Spike:
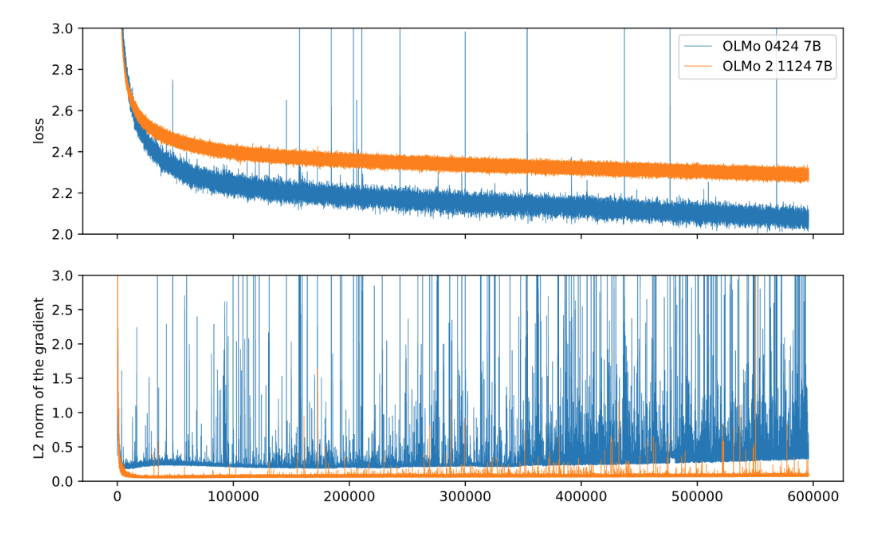
这是Loss Spike的一个例子,我们可以看到,在训练的过程中,模型的Loss出现了突然的爆炸(Spike),这导致了训练的不稳定,我们也不希望模型的Loss出现这样的情况。因此,在训练模型的时候,我们需要采取一些稳定训练的技巧来避免Loss Spike的发生。在提出方案之前,我们先来分析一下,为什么Loss Spike会发生?主要是因为softmax,exponent和division的存在,可能导致数值不稳定。
哪里存在softmax的operation呢?一个出现在Attention Head当中,另一个存在Output Head当中。先来看一下如何解决Output softmax stability的问题
7.1 Output Softmax stability (z-loss)
7.2 Attention Softmax Stability (QK-Norm)
7.3 Logit soft-capping
控制logit的范围,避免过大或过小导致的数值不稳定。
8 Attention
接下来,我们将来介绍 Transformer中Attention 层,以及一些Attention的变体,包括:
8.1 GQA/MQA
8.1.1 KV Cache
8.2 Sliding Window Attention
8.3 Linear Attention
我们知道,对于一个长度为 \(n\) 的序列,传统的Attention机制需要计算 \(\mathcal{O}(n^2)\) 的注意力分数,主要原因是 \(QK^\top\)。这个操作需要计算 \(n \times d\) 的 \(Q\) 和 \(d \times n\) 的 \(K^\top\),从而得到一个 \(n \times n\) 的矩阵,其时间复杂度是\(\mathcal{O}(nnd)\) 我们可以把Attention的操作抽象成以下的公式:
\[ Attn(Q, K, V) = \rho(QK^\top) V \tag{12}\]
其中,\(\rho\)在传统的Attention中是softmax函数。如果我们取 \(\rho\) 是一个Identity函数,那我们就可以把时间复杂度从 \(O(n^2)\) 降低到 \(O(n)\),从而实现Linear Attention:
\[ Attn(Q, K, V) = QK^\top V = Q(K^\top V) \tag{13}\]
其中,\(K^\top V\) 的计算量是 \(O(nd^2)\),而 \(Q(K^\top V)\) 的计算量也是 \(O(nd^2)\),因此整个Attention的计算量是 \(O(nd^2)\),从而实现了线性时间复杂度, 这也是Linear Attention名字的由来。
WARNING: The Choice of \(\rho\)
对于\(\rho\)的选择,我们不能简单选择Identity函数,因为这样会导致模型的性能大幅下降。我们实际希望的是: \[ Attn(Q, K, V) = \phi(Q) (\phi(K)^\top V) \tag{14}\]
其中,\(\phi\) 是某种feature map/kernel map,它可以将\(q,k\)映射到一个新的空间中,使得\(\phi(Q) \phi(K)^\top\) 可以近似地表示原始的 \(QK^\top\),从而在保持线性时间复杂度的同时,尽可能地保留原始Attention的性能。 在这里,为了简单起见,我们就先不考虑复杂的变换
Linear Attention更好的一点是,我们只需要存储一个 state \(S_t\),而不需要存储整个 \(K\) 和 \(V\),简单来说,对于下一个传入的token, 我们只需要更新state \(S_t\),而不需要重新计算整个Attention矩阵:
\[ S_t = S_{t-1} + k_tv_t^\top \quad \text{and} \quad y_t = q_t^\top S_t \tag{15}\]
其中 \(k_tv_t^\top \in \mathbb{R}^{d \times d}\) 是当前token的 \(k\) 和 \(v\) 的外积,\(S_{t-1}\) 是之前的状态,\(y_t\) 是当前token的输出。
WARNING: The Transpose of \(k, v\)
细心的读者可以发现,在 Equation 14 中,\(k\) 和 \(v\) 的转置位置和 Equation 15 中不一样。这是因为在 Equation 14 中,\(K, V \in \mathbb{R}^{n \times d}\),而在 Equation 15 中,\(k_t, v_t \in \mathbb{R}^{d}\)。
Linear Attention的这个特性(Equation 15), 让我们在训练模型的时候,可以保持Transformer的高并行性,同时在推理的时候,可以实现RNN式的线性计算,提升推理的效率。
接下来,我们来看一下基于这个公式Equation 15的变体以及应用。
8.4 Minimax M1
Minimax(MiniMax et al. 2025)基于Lightning Attention(Qin et al. 2024),实现了Long Context Inference的Linear Scaling。
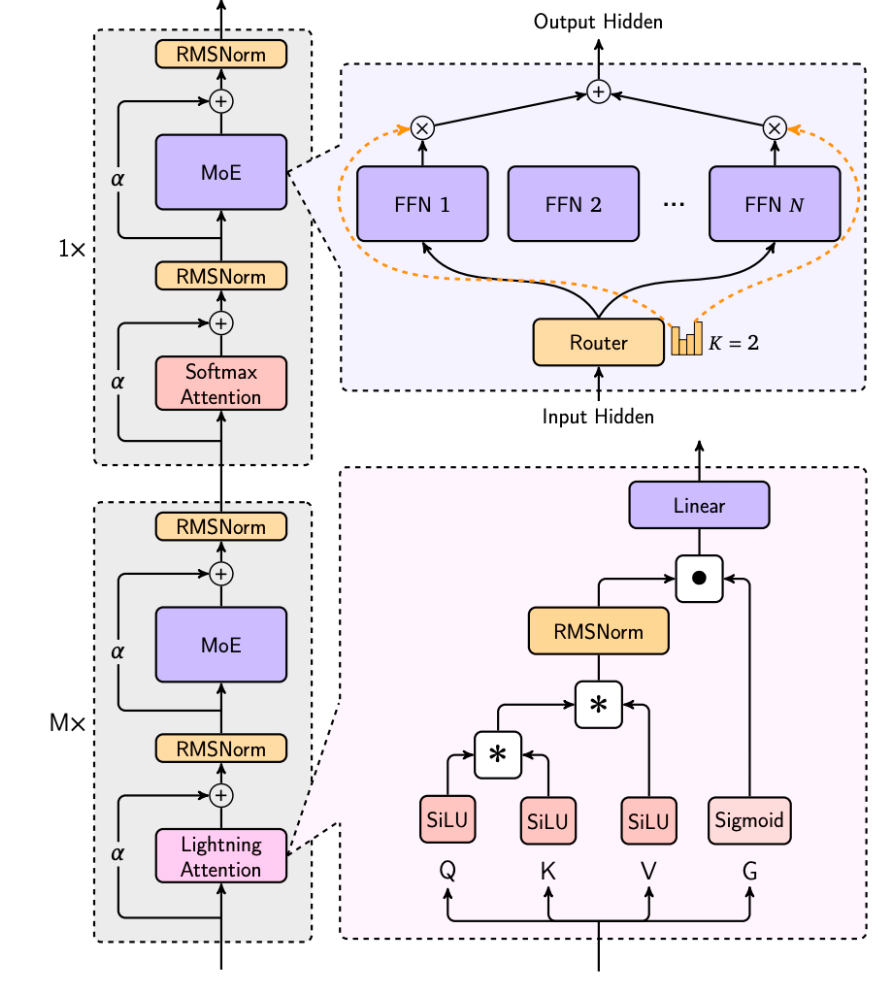
其中,Lightning Attention(Qin et al. 2024)是Linear Attention的一种变体,它通过引入一个新的state \(S_t\),来提升模型的表达能力。具体来说,Lightning Attention的state更新公式如下:
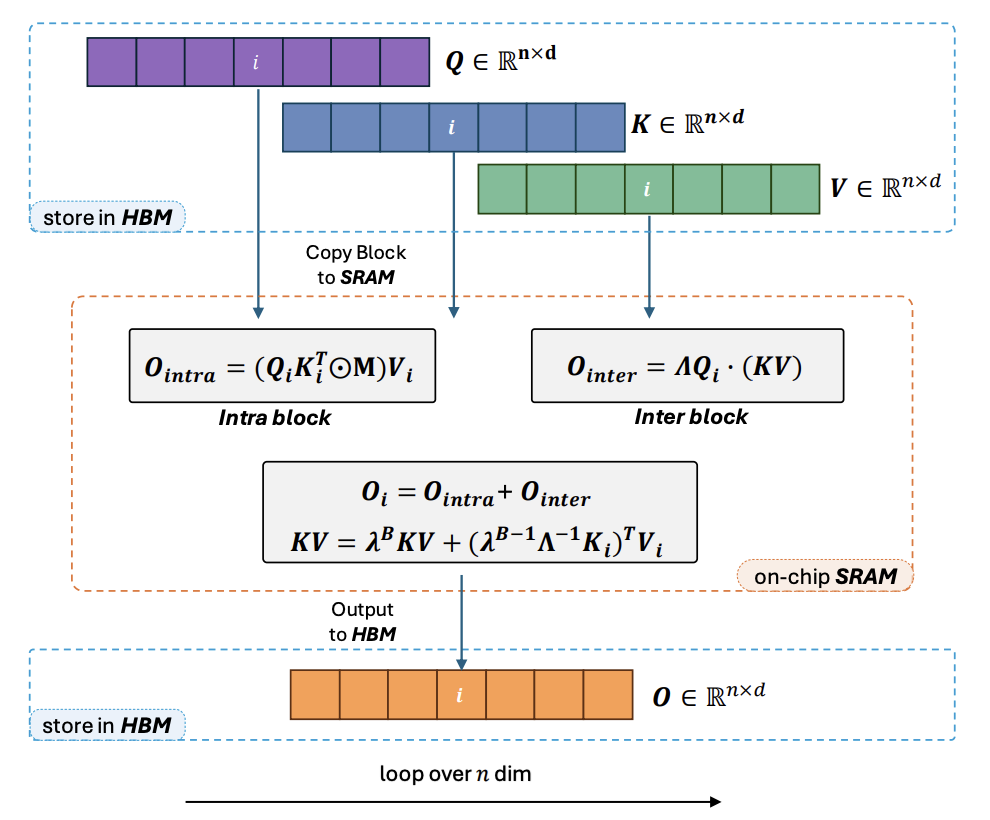
MiniMax Lighting Attention本质上是一个 分块(block-wise)的线性注意力:
- 块内(intra-block):对一个 block 内的 token,仍然做类似因果注意力的二次交互。
- 块间(inter-block):不再保存全部历史 K,V,而是维护一个递推的状态 kv,把过去的信息压缩成一个 d × e 的矩阵状态。
8.5 RetNet
RetNet(Sun et al., n.d.)是Transformer的一种变体
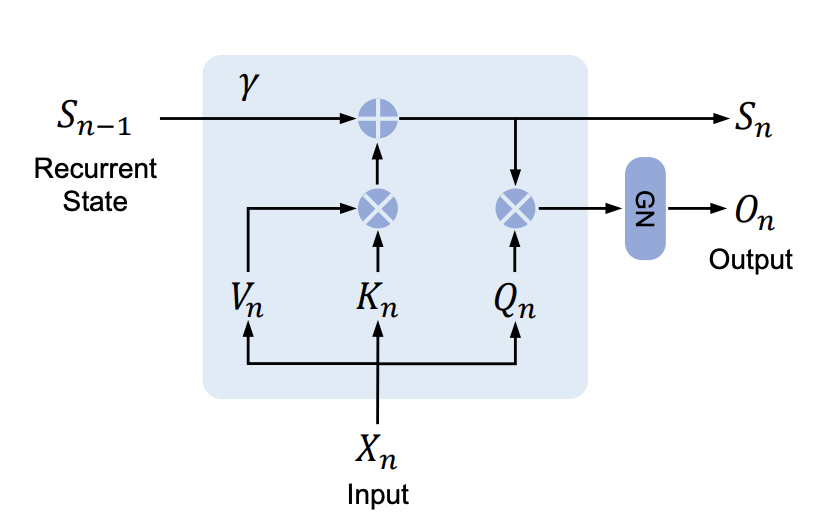
通过在state中加入一个gating \(\gamma\),
\[ S_t = \gamma S_{t-1} + k_t v_t^\top \quad \text{and} \quad y_t = q_t^\top S_t \tag{16}\]
8.6 Mamba-2
NOTE: State Space Model
State Space Model 来自控制论和信号处理, 它的核心思想是:不把整个历史都存下来,而是维护一个隐藏状态 state,让这个 state 压缩过去的信息;每来一个新信息,就更新一次 state,然后用这个 state 来做预测。通过公式可以表示为:
\[ \begin{split} h_{t} &= Ah_{t-1}+Bx_t \\ y_t &= Ch_t+Dx_t \end{split} \]
其中,\(h_t\) 是隐藏状态,\(x_t\) 是输入,\(y_t\) 是输出,\(A, B, C, D\) 是模型的参数。简单来说就是当前状态 h_t 由“过去状态” \(Ah_{t-1}\) 和“当前输入” \(Bx_t\) 决定输出由状态 \(Ch_t\) 和输入 \(Dx_t\) 决定
Mamba-2(Dao and Gu, n.d.)是Transformer的另一种变体,它通过引入一个新的state \(M_t\),来提升模型的表达能力。具体来说,Mamba-2的state更新公式如下:
\[ S_t = \textcolor{red}{\gamma_t}S_{t - 1} + k_t v_t^\top \quad \text{and} \quad y_t = q_t^\top S_t + \textcolor{red}{v_t^\top D} \tag{17}\]
其中,\(\gamma_t\) 是一个动态的gating,它可以根据当前的输入和状态来调整过去信息的权重,从而提升模型的表达能力。\(D\) 是一个新的参数矩阵,它可以让模型更好地利用当前输入的信息,从而提升模型的性能。
Mamba-2可以替换Transformer的Attention Layer,比如说,在Nemotron里,我们可以把Transformer的Attention Layer替换成Mamba-2 Layer:
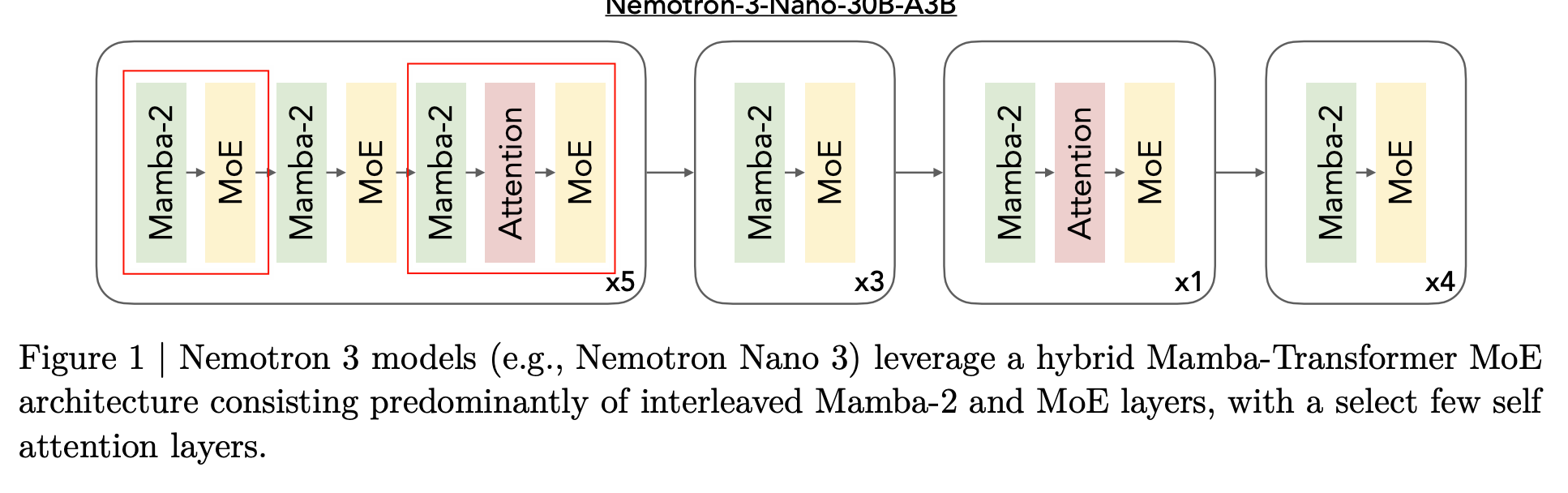
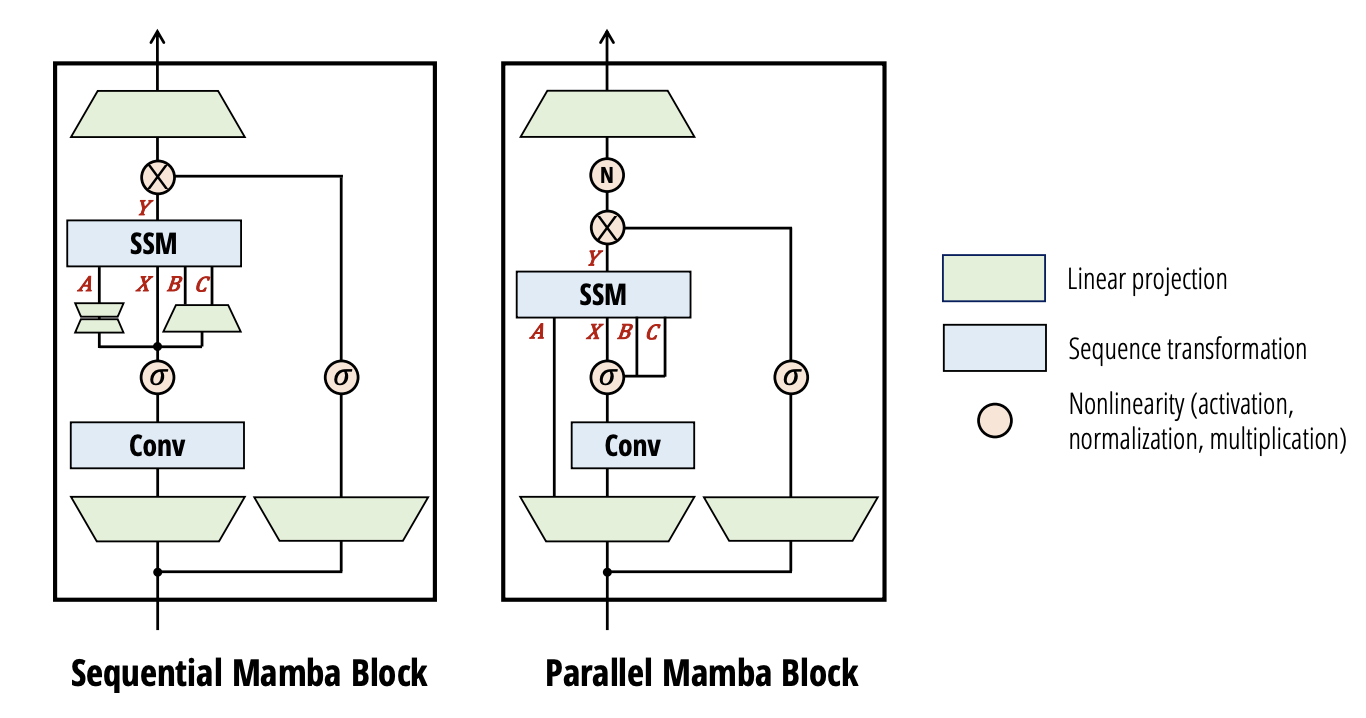
8.7 Gated Delta Net
在Mamba-2的基础上,我们可以再进一步,(S. Yang, Kautz, and Hatamizadeh 2025)提出了Gated Delta Net,它通过引入一个新的delta state \(\Delta_t\),来进一步提升模型的表达能力。具体来说,Gated Delta Net的state更新公式如下:
\[ \begin{split} \Delta_t &= \textcolor{red}{\alpha_t} \Delta_{t-1} + k_t v_t^\top \\ S_t &= \textcolor{red}{\gamma_t} S_{t-1} + \Delta_t \\ y_t &= q_t^\top S_t + \textcolor{red}{v_t^\top D} \end{split} \tag{18}\]
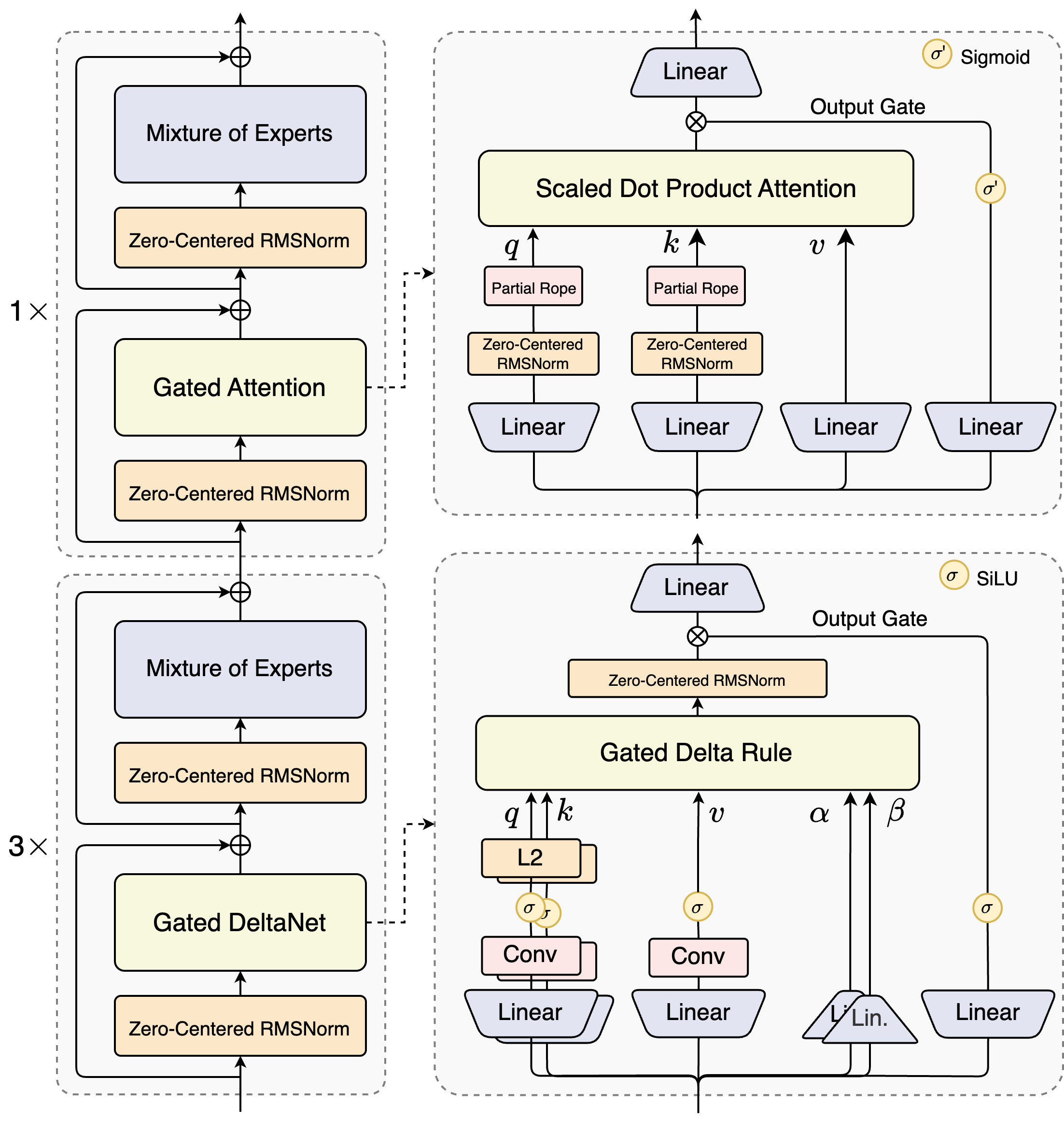
8.8 DeepSeek Sparse Attention
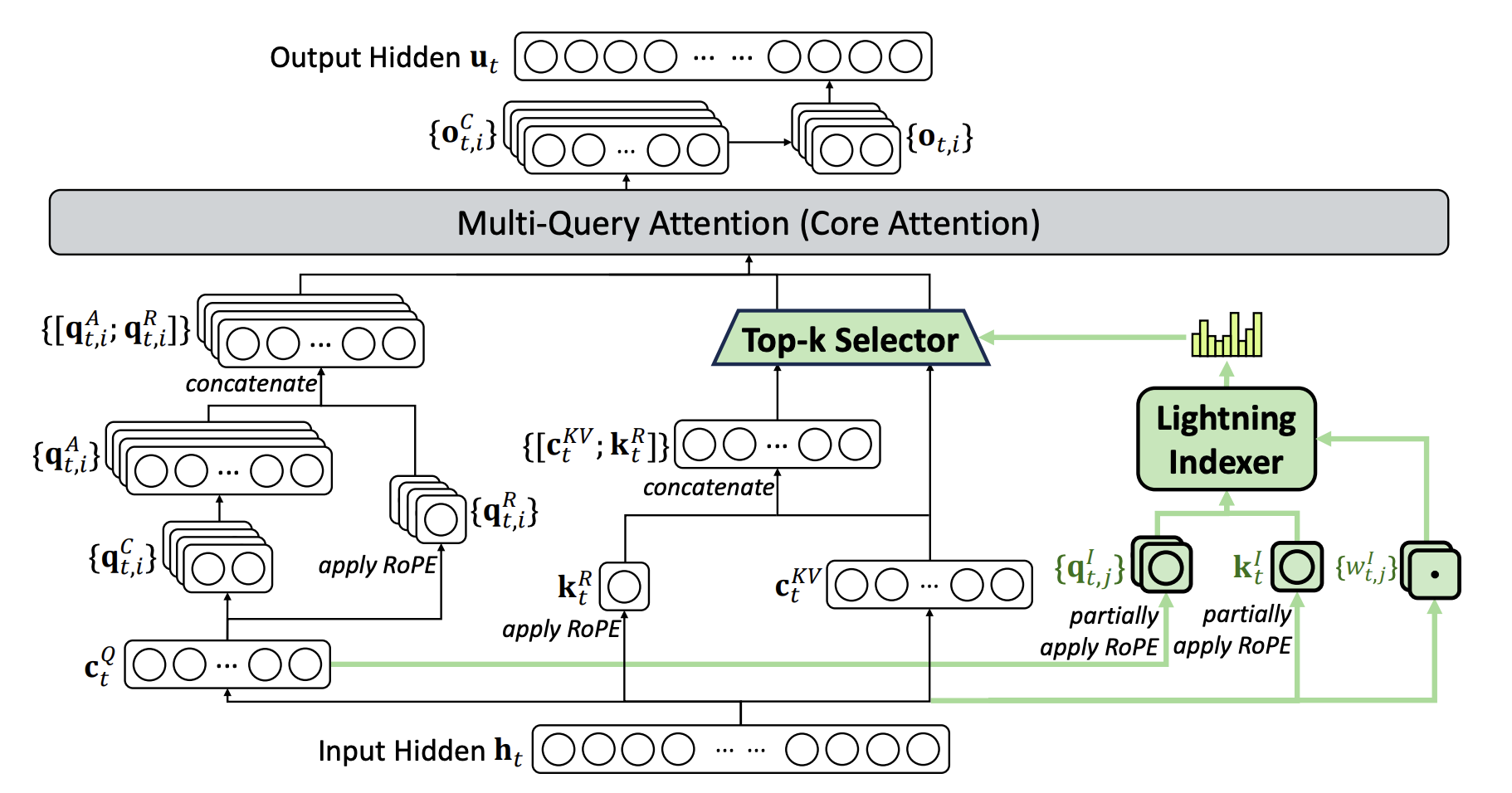
9 What is Mixture of Experts (MoE)?
随着2025年春节DeepSeek-R1 的发布,Mixture of Experts (MoE) 模型在自然语言处理领域重新引起了广泛关注。这节课我们将会学习什么的MoE Layer。它的基本原理是什么?它是如何工作的?以及它为什么能够提升模型的性能。
在Assignment01中,我们实现了FFN Layer。但是作业中并没有要求大家实现MoE Layer。为了帮助大家更好地理解MoE Layer的实现细节,也作为大家关注我的Bonus,我在Assignment01的代码库中添加了MoE Layer的实现代码。大家可以参考以下链接查看代码实现。
过去几年,大模型的主流路线几乎只有一条:把 Transformer 做得更大、更深、更宽,然后用更多数据与更多算力堆上去。Mixture of Experts(MoE)的出现,给这条路线增加了一个非常“工程味”的分支:在不显著增加每一步计算量(FLOPs)的前提下,把模型的参数容量做得更大。
在这里需要提一点的是,MoE中的“专家”(Expert)指的是模型中的一个子网络,通常是一个独立的神经网络层或模块。而并不是模型里真的存在“代码专家 / 英语专家 / 数学专家”。
如果你把大模型训练理解为“在固定预算下换取最强效果”,那 MoE 之所以引发关注,核心就一句话:
同样的训练/推理 FLOPs,MoE 往往能给你更低的 loss、更好的 perplexity、更好的下游表现——只要你能把它训练稳、跑得快。
这也解释了为什么 MoE 在 2024–2025 迅速从“研究圈的技巧”变成“工业界的默认选项”之一.
其实MoE的概念并不新鲜,比如 Switch Transformer (Fedus, Zoph, and Shazeer 2022) 早在2021年就提出,并且改进了MoE的训练稳定。我们先来看一下MoE的基本结构。
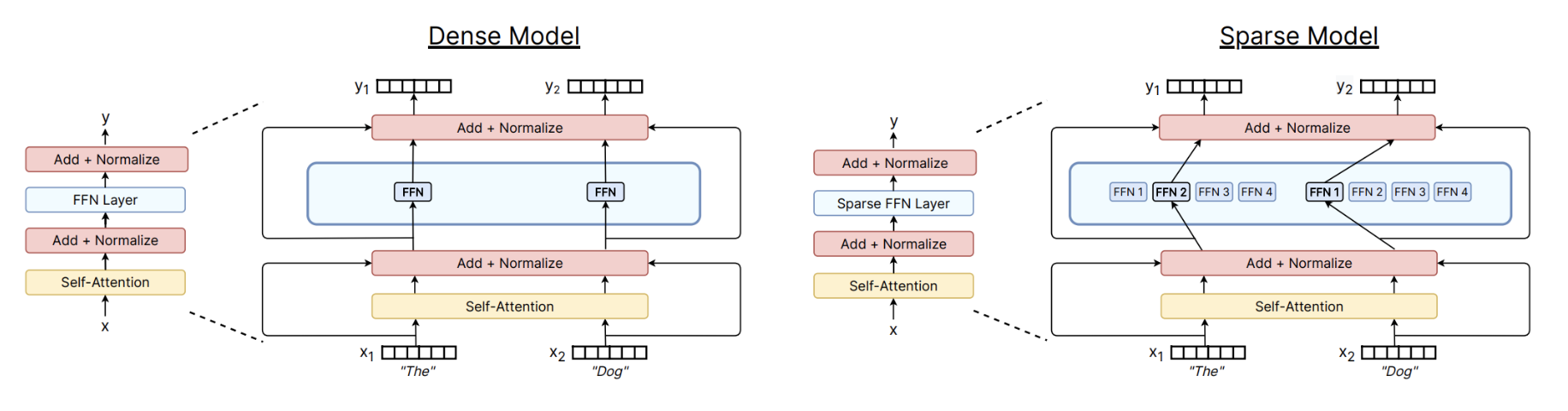
从 Figure 25 中可以看出,每个token被送入其中一个专家网络(Expert)进行处理,而不是像传统的FFN Layer那样,所有token都经过同一个FFN Layer。这样一来,MoE Layer的参数量可以大幅增加,而每个token实际计算的FLOPs并没有显著增加。
在相等的FLOPs下,参数量的增加,往往能带来模型表达能力的提升,从而提升模型的性能。这也是MoE能够在不显著增加计算量的前提下,提升模型性能的原因之一。
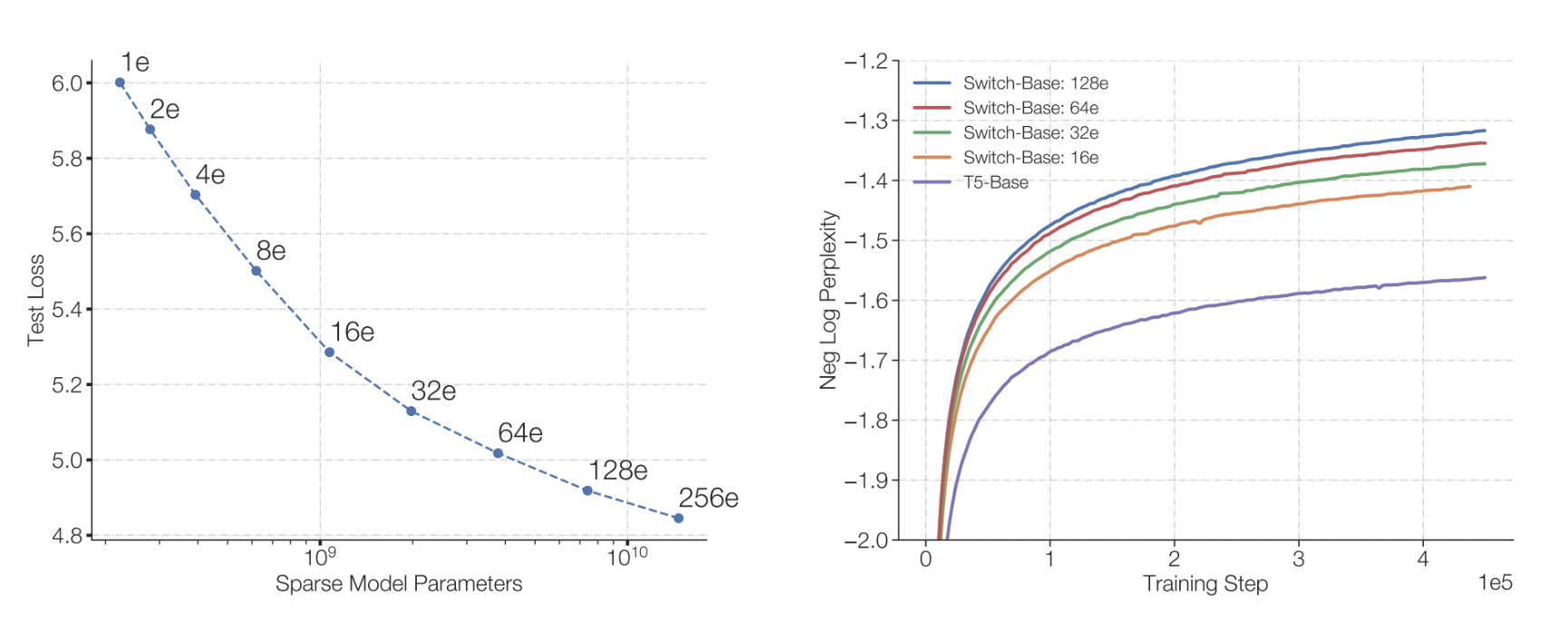
另外一个优点就是了, MoE所需的训练时间更短。如下图所示,在达到相同的perplexity水平下,MoE模型所需的训练时间明显少于Dense模型。
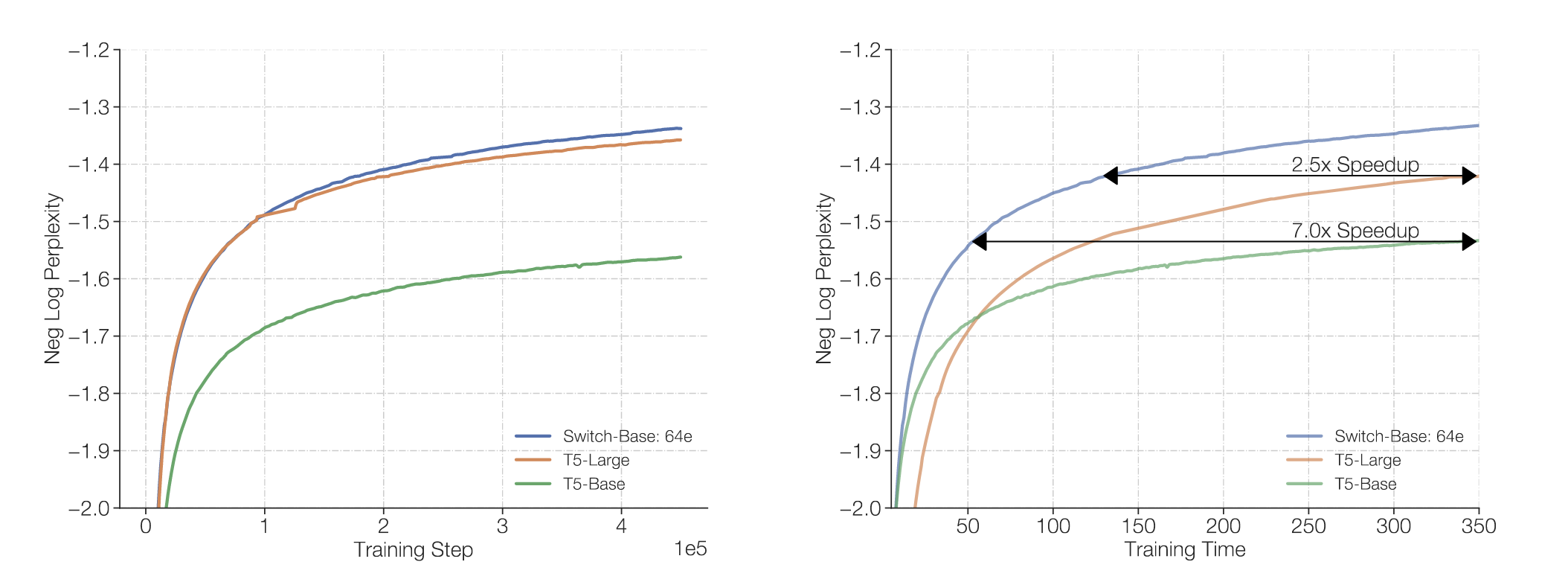
并且,由于MoE有不同的Experts, 并且每个Expert可以独立训练,这使得MoE模型在分布式训练中更具优势。我们可以将不同的Experts分配到不同的计算节点上,从而更好地利用分布式计算资源,提高训练效率。
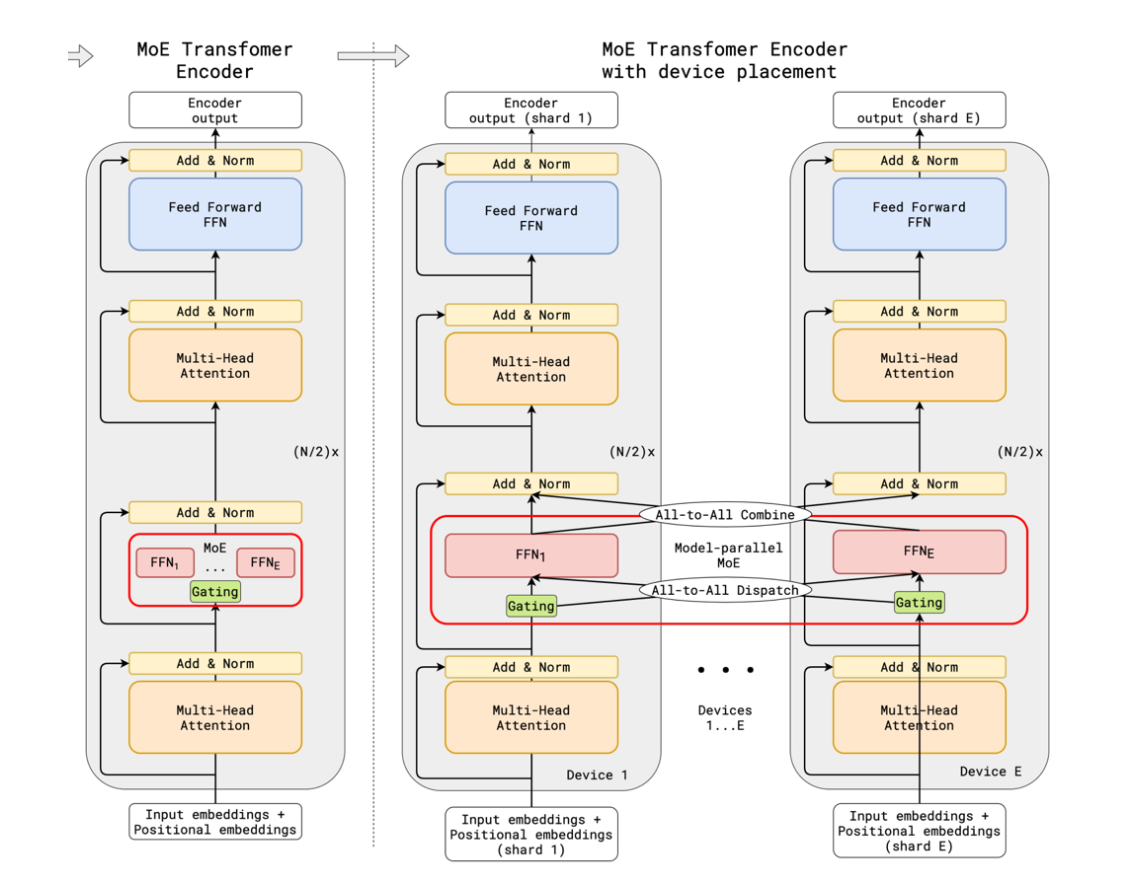
但是,既然MoE有这么多优点,为什么它不是大模型的唯一选择呢?这就要提到MoE的几个挑战了。
- 训练稳定性:由于MoE模型中有多个Experts,如何确保每个Expert都能得到足够的训练数据是一个挑战。如果某些Experts很少被选择,可能会导致它们无法有效学习,从而影响整体模型的性能。
- 路由机制:MoE模型需要一个路由机制来决定每个token应该送入哪个Expert。设计一个高效且有效的路由机制是MoE模型的关键之一。
- 实现复杂性:MoE模型的实现相对于传统的Dense模型更为复杂,尤其是在分布式训练环境下,需要处理更多的通信和同步问题。
正是由于这些挑战,MoE模型在实际应用中需要更多的工程技巧和经验。因此,虽然MoE有很多潜在的优势,但它并不是适合所有场景的万能解决方案。
TL;DR
MoE 之所以火,是因为它把 Transformer 里最“贵”的 FFN 变成很多个专家,但每次只激活少数几个:在 FLOPs 近似不变的情况下显著增加参数容量,通常能带来更好的训练/推理性价比;代价是训练稳定性与系统实现复杂度。
了解了MoE的基本概念,优点和挑战后,接下来我们将深入探讨MoE的具体实现细节,包括路由机制、训练方法等内容。
在第一节我们意见了解了MoE的基本概念以及基本的架构 Figure 25,在这一节我们将更详细地介绍MoE的架构组成部分,包括:
- Routing Function: 决定每个token应该送入哪个Expert的函数。
- Experts :多个独立的FFN Layer,每个Expert负责处理一部分token。
- Training Objectives:MoE模型的训练目标和损失函数设计。
首先,我们来看一下Routing Function的设计。
10 MoE Routing Function
MoE 的核心不是“有很多专家”,而是每个 token 该去哪些专家。这个决策由 Router(路由器)完成。我们可以把它理解成一个“轻量的分类器/打分器”:输入是每个 token 的 hidden state,输出是对所有专家的偏好分数,然后选出 top-K 个专家执行。有一点很重要的是:
Router 是具有上下文感知能力的,也就是说它会根据 token 的内容动态决定路由结果,也就是说同一个 token 在不同语境下可以被送去不同专家。
Router实现大概有3种思路:
- Token-choice(token 选专家): 每个 token 给所有专家打分,选择 top-K 专家处理它(现代主流)
- Expert-choice(专家选 token): 每个专家从一批 token 里挑 top-K 个来处理(天然更均衡)
- Global assignment(全局分配):把 token–expert 匹配视作优化问题(如线性分配/最优传输),追求更均衡或更低通信成本
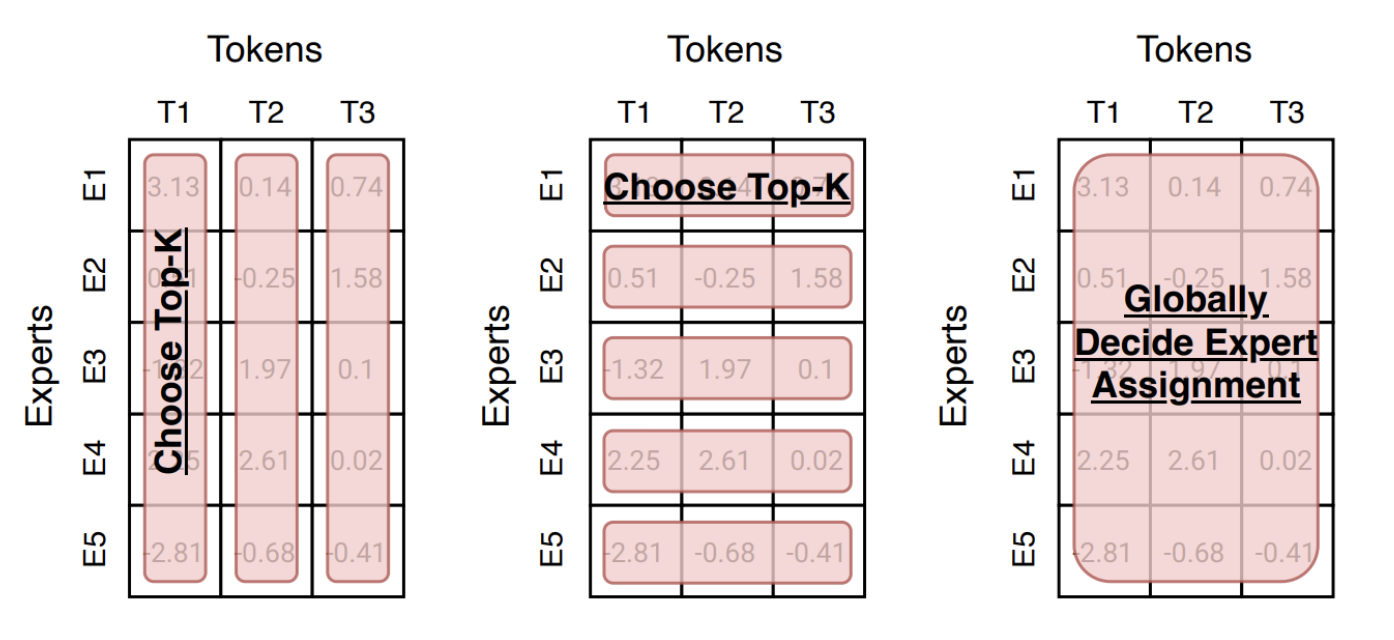
在实际应用中,Token-choice 是目前最主流的设计思路,因为它实现简单且易于扩展。下面我们来看一下Token-choice Router的具体实现。
10.1 Token-choice Router
Token-choice Router, 顾名思义,就是每个 token 给所有专家打分,选择 top-K 专家处理它。当然,这个“打分”过程(Routing)可以有很多种实现方式,比如:
- Top-K Gating:使用一个线性层对 token 的 hidden state 进行投影,得到每个专家的分数,然后选择 top-K 个专家。
- Hashing-based Routing:使用哈希函数将 token 映射到专家,从而实现路由(通常作为Baseline)。
- RL to learn Routing:使用强化学习方法来学习路由策略。
- Solve a Optimization Problem:将路由问题视作一个优化问题,通过求解该问题来确定路由结果。
下图展示了不同的Token-choice Router实现方式。
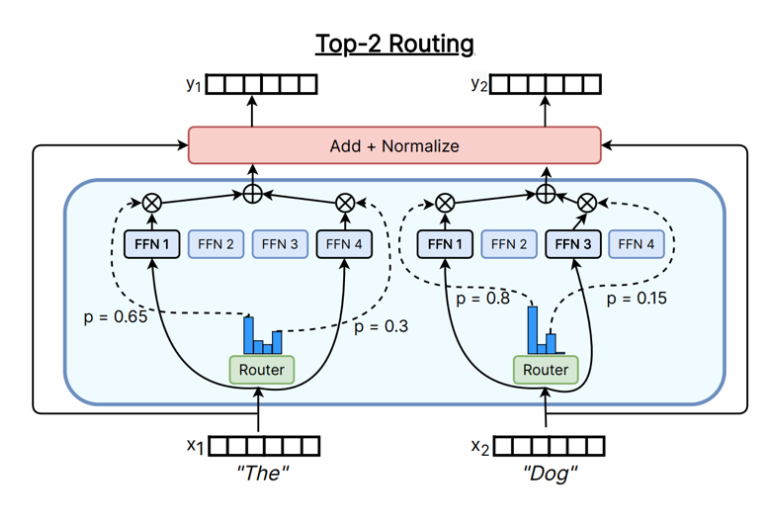
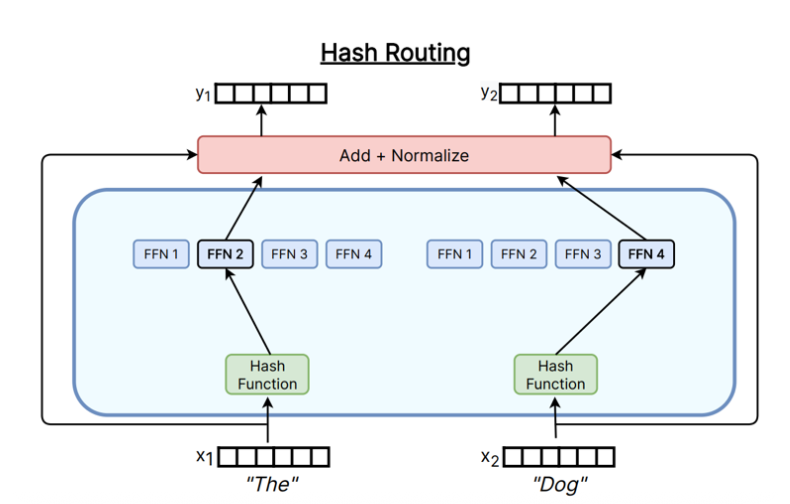
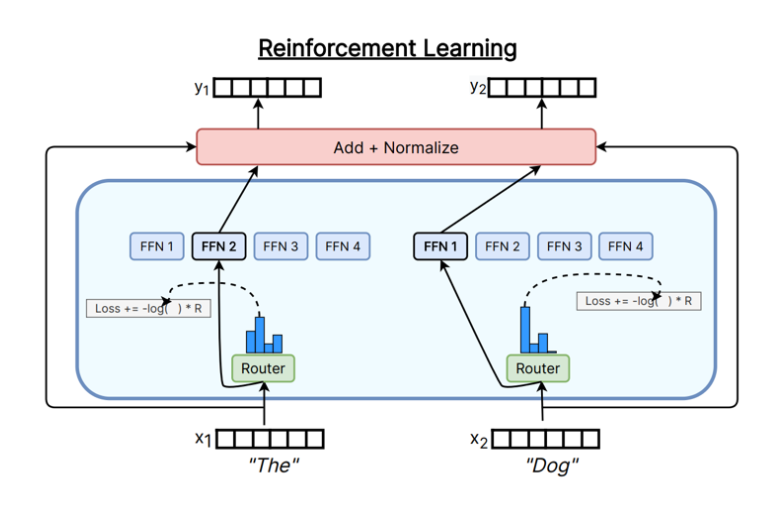
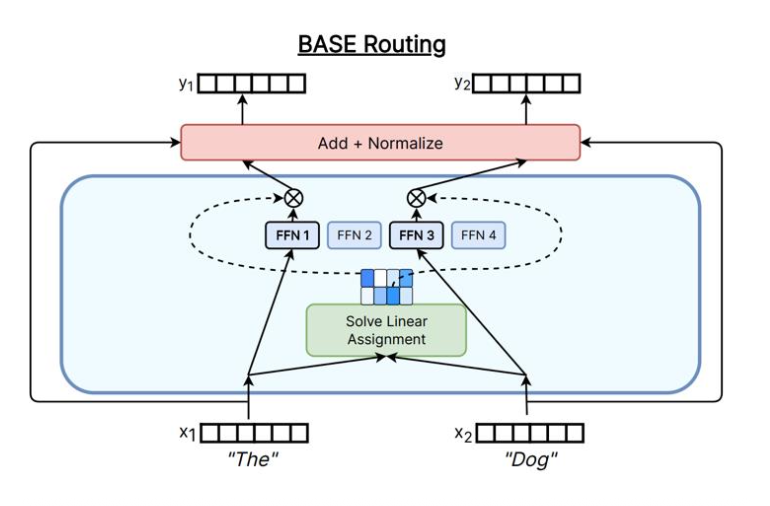
在实际应用中,Top-K Gating 是目前最常用的 Token-choice Router 实现方式,因为它简单且高效。下面我们来看一下 Top-K Gating 的具体实现细节。
10.1.1 Top-K Gating
Top-K Gating 的实现步骤如下:
- Score Calculation:对于每个 token 的 hidden state \(h_i\),通过一个线性层计算每个专家的分数: \[ s_{i,j} = W_g h_i + b_g \tag{19}\] 其中,\(W_g\) 和 \(b_g\) 是路由器的参数,\(s_{i,j}\) 是 token \(i\) 对专家 \(j\) 的分数。
有了score之后,接下来我们需要选择 top-K 个专家,不过在此之前,我们通常会对score进行归一化处理,以便更好地比较不同专家的分数。常用的方法是使用softmax函数: \[ p_{i,j} = \frac{exp(s_{i,j})}{\sum_{k} exp(s_{i,k})} \tag{20}\] 其中,\(p_{i,j}\) 是 token \(i\) 对专家 \(j\) 的归一化分数。
Top-K Selection:对于每个 token,选择分数最高的 K 个专家: \[ g_{i, j} = \begin{cases} s_{i, j}, \quad s_{i, j} \in \text{Top-K}(s_i) \\ 0, \quad \text{otherwise} \end{cases} \tag{21}\] 其中,\(g_{i,j}\) 是 token \(i\) 对专家 \(j\) 的选择结果。
Passing to Experts:将 token 送入选择的专家进行处理。每个专家只处理被选中的 token,其余 token 被忽略。
Combining Outputs:将专家的输出进行合并,得到最终的 token 表示。通常使用加权平均的方式: \[ h_i' = \sum_{j} g_{i,j} \text{Expert}_j(h_i) + h_i \tag{22}\] 其中,\(h_i'\) 是 token \(i\) 的最终表示,\(\text{Expert}_j(h_i)\) 是专家 \(j\) 对 token \(i\) 的处理结果, \(h_i\) 是 token \(i\) 的原始表示(Residual Connection), \(g_{i,j}\) 是 token \(i\) 对专家 \(j\) 的选择结果。
通过以上步骤,Top-K Gating 实现了对 token 的动态路由,使得每个 token 只经过少数几个专家,从而实现了 MoE 的高效计算。
10.1.2 Top-K Variants
在实际应用中,Top-K Gating 有一些变体,其中比较常见的是DeepSeek提出的Top-K变形(Dai et al. 2024), 它提出,在选择Top-K专家的基础上,每个token还会固定传入一个Shared Expert。这样做的好处是,可以确保每个token至少有一个专家能够处理它。 并且Expert的大小变小,但是数量变多(fine-grained Experts),从而提升模型的表达能力。
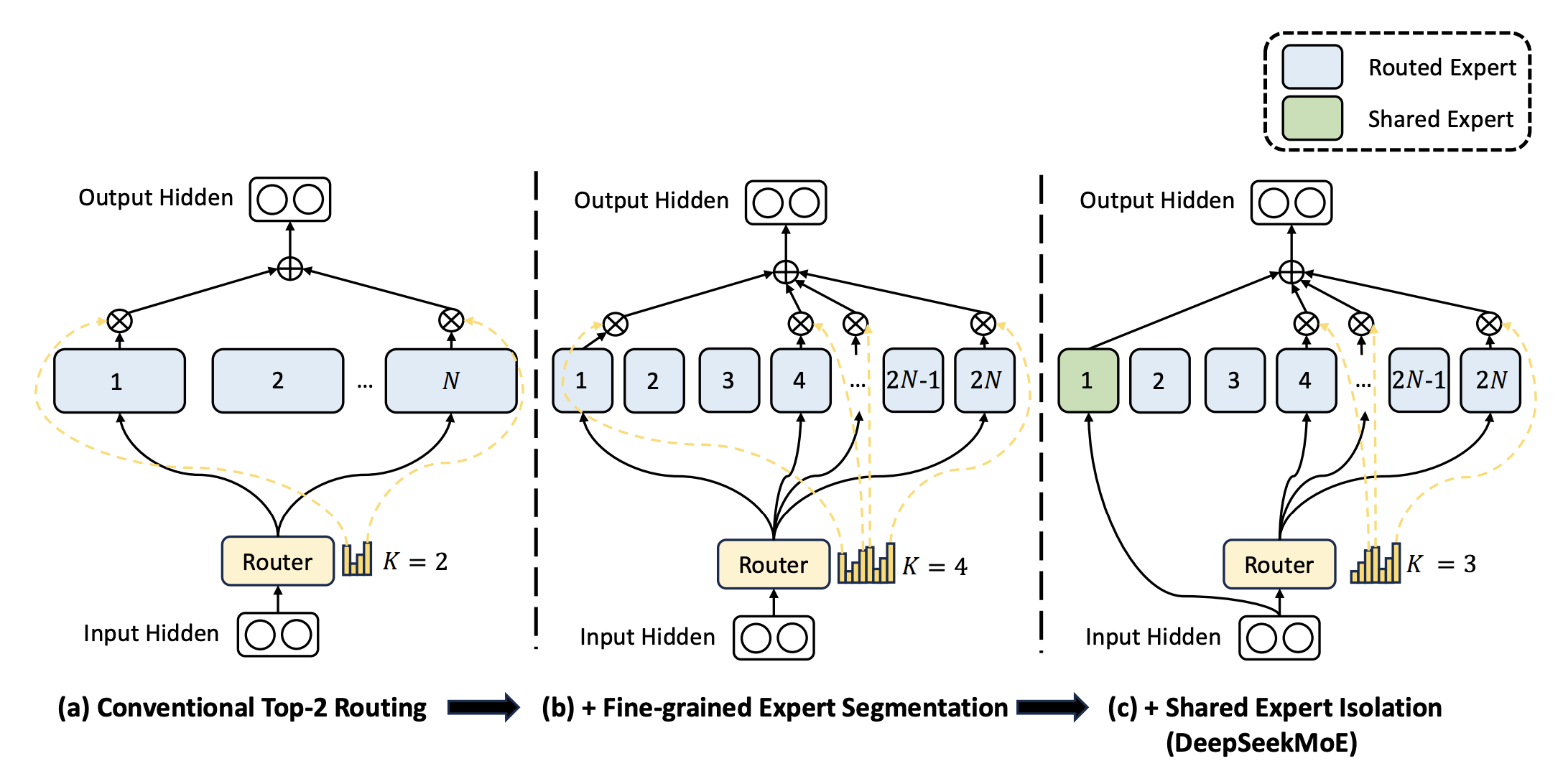
这种方式,在之后的实验中也被证明是有效的。 Qwen3模型(A. Yang et al. 2025) 也采用了类似的设计。
10.1.3 Choice of K
我们了解了Top-K Gating的实现细节,接下来我们来看一下K值的选择对模型性能的影响。 K值的选择对MoE模型的性能有显著影响。一般来说,较小的K值可以减少计算量,但可能会限制模型的表达能力;而较大的K值则可以提升模型的表达能力,但会增加计算量。因此,在实际的应用中,通常使用 K=1 或 K=2 作为默认选择。
课堂中有提到,K > 1 时。我们可以把它想象成Bandit的问题(熟悉Reinforcement Learning的同学应该了解)。每个token在选择专家时,就像是在玩一个多臂老虎机(Multi-armed Bandit),每次选择K个专家进行尝试,从而获得更好的奖励(模型性能)。这也是RL中探索与利用(Exploration vs. Exploitation)问题的一个体现。
10.1.4 Is Top-K Gating Optimal?
我们了解了Top-K Gating的实现,那么它是不是最优的呢?其实也不尽然。Lecture中有提到一个比较有趣的观察:即使 router 很弱(比如基于 hashing 的确定性映射),很多时候也能比 dense 更强。有一种合理的解释是:只要映射是确定性的,每个专家仍会长期看到某个子分布,从而形成某种“专门化”(不一定是你以为的语义专门化,可能是频率/模式上的专门化)。因此,Router并不一定要设计的很复杂,简单有效即可,这也就是为什么Top-K Gating能这么受欢迎的原因之一。
11 MoE Experts
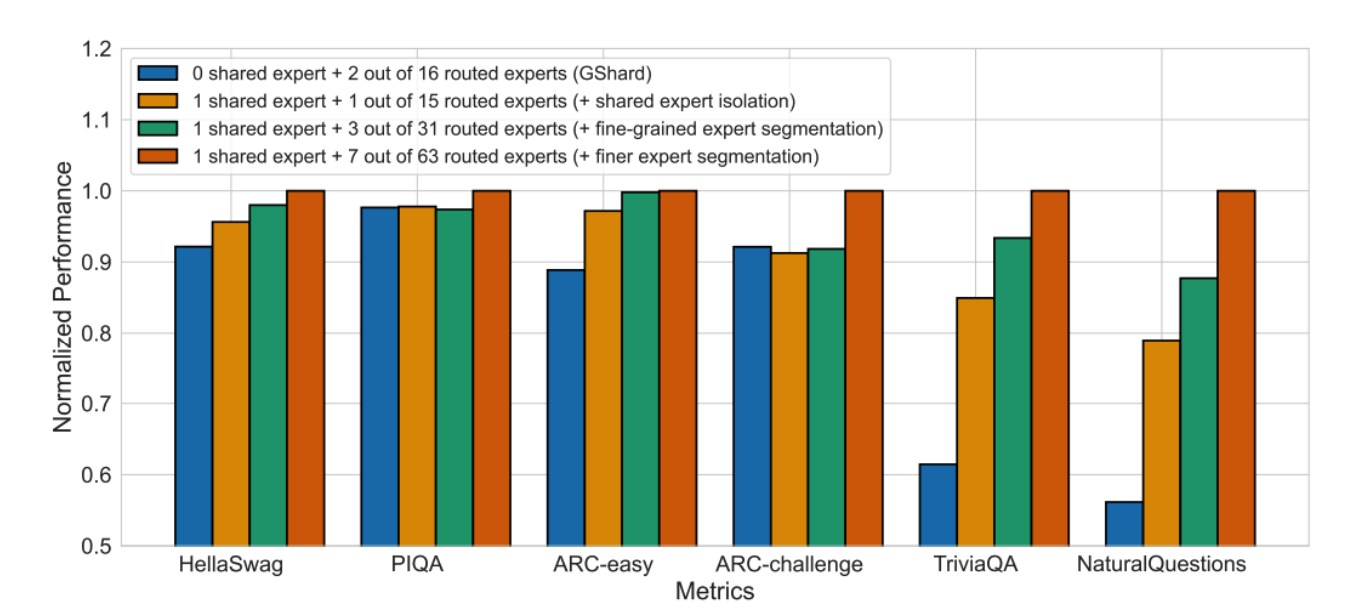
在MoE模型中,Experts是多个独立的FFN Layer,每个Expert负责处理一部分token。每个Expert通常由一个前馈神经网络(Feed-Forward Neural Network, FFN)组成,结构与传统的Transformer中的FFN类似,但参数是独立的。那么,Experts的中间层的维度应该如何选择呢? 一般来说,Experts的中间层维度通常设置为输入维度的4倍(即\(4d_{model}\)),和传统的FFN Layer保持一致。这是因为较大的中间层维度可以提升模型的表达能力,从而提升整体性能。 但是,在Figure 31中,我们看到DeepSeek介绍了Fine-Grained Experts的概念,即通过增加Experts的数量,同时减少每个Expert的中间层维度,从而提升模型的表达能力。在DeepSeek MoE 中(Dai et al. 2024), 每个Expert的中间层维度被设置为\(\frac{1}{4}d_{ff}\). 这样做的好处是,可以让模型拥有更多的专家,从而提升模型的多样性和表达能力。
DeepSeekMoE has 1 shared expert and 63 routed experts, where each expert is 0.25 times the size of a standard FFN. DeepSeekMoE: Towards Ultimate Expert Specialization in Mixture-of-Experts Language Models, p.9
12 Training Objectives
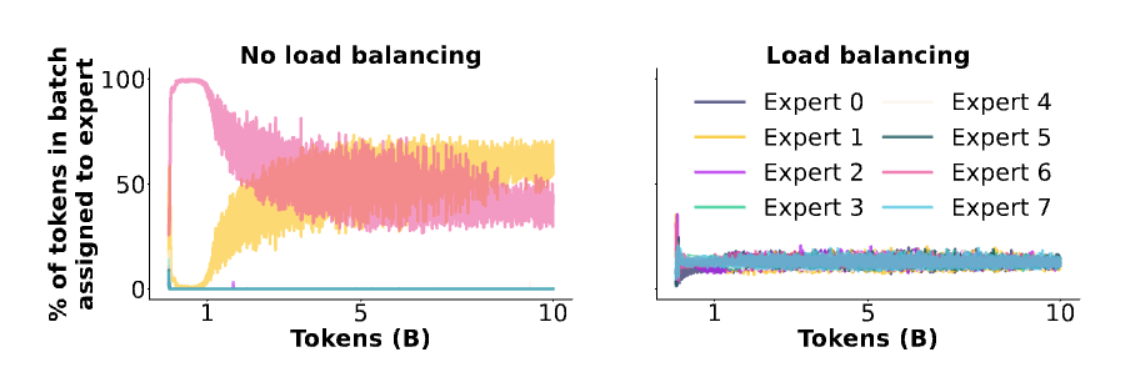
如果说 Routing Function 解决的是“每个 token 去哪些专家”,那 Training Objectives 解决的是更现实的问题:“每个专家到底学什么”。在 MoE 里,单纯靠主任务 loss(Next token Prediction Loss) 往往不够.如果你只用语言模型的主损失(next-token loss)去训 MoE,router 很容易把所有 token 都送去同一个专家。结果是:一个专家变成“万能专家”,其它专家几乎从不被激活(dead experts),你白白存了一堆参数,性能也会变差。
因此,课堂上也在反复强调的一点是:
MoE 的 forward 很简单,难点在于训练时如何避免 expert collapse,并让专家使用更均匀、更有效率。
接下来,我们来看看这个训练问题难在哪里,以及有哪些常用的解决方法。
12.1 The Challenge of MoE Training
MoE 的优势在于,在训练时,我们只需要根据Router来选择激活部分(Top-k)专家进行计算,而不是所有专家都参与计算。这种稀疏激活的方式,可以大幅减少每一步的计算量(FLOPs),从而提升训练效率。但是,这种稀疏激活的方式也带来的挑战是:Top-K是不可微的,这使得我们无法直接使用梯度下降法来优化模型参数。因此,研究员们提出了几种方法来解决这个问题。
12.1.1 RL Based Optimization
一种思路是使用强化学习(Reinforcement Learning, RL)的方法来优化路由器的参数。
对于不熟悉强化学习的同学,简单介绍一下。强化学习是一种机器学习方法,它通过与环境的交互来学习最优策略。在强化学习中,智能体(Agent)通过观察环境状态(State),选择动作(Action),并根据环境反馈的奖励(Reward)来调整策略,从而最大化累积奖励。 在交互的过程中,Agent所产生的动作通常是离散的(Discrete Action),这就导致了强化学习中的一个核心问题:如何在离散动作空间中进行有效的策略优化。常用的方法包括策略梯度(Policy Gradient)和Q-learning等。 因此,我们可以将MoE的路由问题视作一个强化学习问题,通过设计合适的奖励函数,来引导路由器学习更优的路由策略。
但是,强化学习的方法通常比较复杂,且训练过程不稳定(Gradient Estimation Variance较大),因此在实际应用中并不常用。
12.1.2 Stochastic Approximation
另一种思路是使用随机近似(Stochastic Approximation)的方法来优化路由器的参数。具体来说,在 router 打分(logits)里注入噪声/扰动,让 top-K 的选择在训练早期“偶尔换路”,从而更像 bandit 的探索策略。其中一个经典的例子就是 Stochastic Jittering. 它通过在路由器的打分中添加高斯噪声,从而实现对专家的随机选择。接下来我们来看一下Stochastic Jittering的具体实现细节。
12.1.2.1 Stochastic Jittering
Stochastic Jittering 的实现步骤如下:
- Router 计算:对于每个 token 的 hidden state \(h_i\),通过一个线性层计算每个专家的分数: \[ s_{i,j} = W_g h_i + b_g \tag{23}\]
- 添加噪声:在每个专家的分数中添加高斯噪声: \[ \tilde{s}_{i,j} = s_{i,j} + \epsilon_{i,j}, \quad \epsilon_{i,j} \sim \mathcal{N}(0, \sigma(x_i)^2) \tag{24}\]
- Top-K 选择:对于每个 token,选择添加噪声后的分数最高的 K 个专家: \[ g_{i, j} = \begin{cases} \tilde{s}_{i, j}, \quad \tilde{s}_{i, j} \in \text{Top-K}(\tilde{s}_i) \\ 0, \quad \text{otherwise} \end{cases} \tag{25}\]
其中,\(\sigma(x_i)\) 是噪声的标准差, 它是一个可学习的函数,通常通过一个小的神经网络来实现。通过调整噪声的大小,可以控制路由器的探索程度,从而提升模型的训练效果。
那么这个Stochastic Jittering解决了什么问题呢? 它其实解决了类似于“探索与利用”(Exploration vs. Exploitation)的问题。在MoE的训练过程中,我们希望路由器能够既能利用当前的知识(选择表现好的专家),又能探索新的可能性(尝试其他专家)。这于 \(\epsilon_{i,j} \sim \mathcal{N}(0, \sigma(x_i)^2)\) 中的噪声注入机制相呼应,通过在路由器的打分中添加噪声,可以让路由器在训练早期“偶尔换路”,从而更像 bandit 的探索策略。
但是,它显然没有解决Top-K选择的不可微问题,并且,噪声的引入也可能导致训练过程的不稳定:
- 噪声过大:可能导致路由器选择的专家过于随机,每个专家不够专门化,影响模型性能。
- 噪声过小:可能无法有效促进探索,路由器仍然倾向于选择少数几个专家,导致专家崩溃(Expert Collapse)。
课上还提到对 logits做乘法噪声(Multiplicative Perturbation),也是类似的思路,但是也有类似的问题。
12.1.3 Auxiliary / Heuristic Balancing Losses
既然MoE训练的难点在于避免专家崩溃(Expert Collapse),那么一个直接的思路就是在主任务损失(Cross Entropy Loss)之外,添加一些辅助损失(Auxiliary Losses)来鼓励专家的均衡使用。这样做的好处是,可以直接引导模型学习更均衡的专家使用策略,从而提升整体性能。在这里,我们介绍两种常用的辅助损失:Load Balancing Loss 和 Z-Loss。
12.1.3.1 Load Balancing Loss
Load Balancing Loss 是Switch Transformer(Fedus, Zoph, and Shazeer 2022)中提出的一种辅助损失,旨在鼓励路由器均衡地使用所有专家。具体来说,它通过计算每个专家被选择的频率,并与理想的均衡分布进行比较,从而计算出负载均衡损失。其公式如下: $$
L_{} = N _{i=1}^{N} f_i P_i $${#eq-load-balancing-loss}
其中:
- \(f_i\) 是专家 \(i\) 被选择的频率, 定义为: \[ f_i = \frac{1}{T} \sum_{x \in \mathcal{B}} \mathbb{1} \{\text{argmax } p(x) = i\} \tag{26}\] \(\mathcal{B}\) 是当前批次的样本集合,\(T\) 是token 的数量,\(\mathbb{1}\) 是指示函数,当专家 \(i\) 被选择时取值为1,否则为0。直观来说:expert i 实际上“承担”了多少负载。
- \(P_i\) 是专家 \(i\) 的平均路由概率,定义为: \[ P_i = \frac{1}{T} \sum_{x \in \mathcal{B}} p_i(x) \tag{27}\] 其中,\(p_i(x)\) 是路由器对专家 \(i\) 的输出分数。直观来说:router “本来倾向”把多少概率分给 expert i。
直观来看:如果某个 expert 实际拿了很多 tokens (\(f_i\) 很大),同时 router 还继续给它很高概率(\(P_i\) 很大),那么它的负载均衡损失就会很大,从而促使路由器减少对该专家的选择。反之亦然。
通过最小化负载均衡损失,可以鼓励路由器均衡地使用所有专家,从而提升模型的训练效果。具体来说: - 如果某个专家被选择的次数远高于平均水平,那么它的负载均衡损失就会很大,从而促使路由器减少对该专家的选择。 - 反之,如果某个专家被选择的次数远低于平均水平,那么它的负载均衡损失也会很大,从而促使路由器增加对该专家的选择。
12.1.3.2 DeepSeek Load Balancing Loss
Deepseek 根据上面的 Load Balancing Loss 设计了一个改进版本。它们提出:
- Per-expert Balancing Loss:将上述的负载均衡损失,拓展为Top-K专家的情况。
- Per-Device Balancing Loss:在分布式训练中,考虑每个计算设备上的专家负载均衡。
我们来看看Per-Device Balancing Loss做的是什么。 我们知道,在分布式训练中,不同的计算设备上可能会有不同数量的专家。如果某个设备上的专家被选择的次数远高于平均水平,那么这个GPU很可能过载,甚至损坏,从而影响整体训练效率。而有些设备上的专家可能几乎没有被选择,导致资源浪费。因此,DeepSeek提出了Per-Device Balancing Loss,旨在鼓励每个计算设备上的专家均衡使用。其公式如下: \[ L_{\text{device}} = \beta \cdot D \cdot \sum_{d=1}^{D} f_d P_d \tag{28}\]
其中: - \(D\) 是计算设备的数量。 - \(f_d\) 是设备 \(d\) 上的专家被选择的频率, - \(P_d\) 是设备 \(d\) 上的专家的平均路由概率。
Per-expert 保证“专家别死”,Per-device 保证“GPU 别爆”。
DeepSeek V3 还提出了另一种改进版本,它们称作Auxiliary Loss Free Balancing,其核心思想是:不再主要依赖 \(\mathcal{L}_{\text{ExpBal}}\) 来做负载均衡,而是通过调整路由器的偏置项(Bias)来实现均衡使用专家。具体来说:
\[ g_{i,j} = \being{cases} s_{i,j} + b_j, \quad s_{i,j} \in \text{Top-K}(s_i) \\ 0, \quad \text{otherwise} \end{cases} \tag{29}\]
直观来看:
- 如果 expert i 最近拿到 token 太小 → 增大\(b_i\) → 它更容易进入 top-K
- 如果 expert i 拿到的 token 太多 → 减小 \(b_i\) → 它更不容易被选中
这是一种在线控制/在线学习式的负载均衡:用规则更新 \(b_i\), 而不是通过梯度下降去学习 \(P_i\)
12.1.3.2.1 Z-Loss
Z-Loss 是另一种常用的辅助损失,旨在鼓励路由器的输出分布更加均匀。其公式如下: \[ L_{z} = \sum_{i} \left( \frac{p_i}{\sum_{j} p_j} - \frac{1}{E} \right)^2 \tag{30}\] 其中,\(p_i\) 是路由器对专家 \(i\) 的输出分数,\(E\) 是专家的总数。通过最小化这个损失,可以鼓励路由器的输出分布更加均匀,从而提升模型的训练效果。
12.1.3.3 Loss Combination
在实际应用中,MoE模型的总损失通常由主任务损失(Cross Entropy Loss)和辅助损失(Load Balancing Loss 和 Z-Loss)组成: \[ L_{total} = L_{CE} + \lambda_{load} L_{load} + \lambda_{z} L_{z} \tag{31}\] 其中,\(L_{CE}\) 是主任务损失,\(L_{load}\) 是负载均衡损失,\(L_{z}\) 是Z-Loss,\(\lambda_{load}\) 和 \(\lambda_{z}\)
12.1.4 System Side
在MoE模型的实现中,系统层面的优化也是非常重要的。由于MoE模型通常包含大量的专家,因此在分布式训练中,需要考虑如何高效地管理和调度这些专家,以提升训练效率和模型性能。但是,它们也带来了系统实现上的挑战,比如:
- 每个 token 只激活少数专家(top-K)才能省 FLOPs,但专家往往分散在不同 GPU/节点上,于是训练要频繁做 all-to-all dispatch + all-to-all gather(把 token 发给对应专家算,再收回来合并)。这类通信是否划算取决于专家 FFN 计算是否“够大够重”,能否 amortize 通信成本。
12.1.5 Fine-tuning MoE
MoE fine-tune 更难:更容易不稳定(blow up)+ 更容易过拟合(train–val gap 大)。
12.1.6 Upcycling
MoE 的另一个有趣应用是“Upcycling”(回收利用)。具体来说,先训练好一个 dense Transformer,再把其中的 FFN/MLP 复制成多份专家(experts),加上一个 router,让模型从这一刻起变成 MoE;继续训练一段时间,就能用较低成本得到“总参数更大、推理仍稀疏激活”的 MoE。它解决了“从零训练 MoE 太慢太难”的问题。
13 DeepSeek V3 Others Tricks
课程的最后介绍了DeepSeek成功的一些其他技巧,包括:
- Multihead Latent Attention:
- Multi Tokens Prediction
在这里就先不展开介绍了,之后会专门写一篇文章来介绍DeepSeek系列论文的细节。
14 Summary
15 In the end
创作不易,如果你觉得内容对你有帮助,欢迎请我 喝杯咖啡/支付宝红包,支持我继续创作!你们的支持是我最大的动力! :)
