Lecture 01: Diffusion
1 Problem Setting
假设我们手上有一个数据集 \(\mathcal{D} = \{\mathbf{z}_1, \mathbf{z}_2, \ldots, \mathbf{z}_N\}\),其中每个数据点 \(\mathbf{x}_i\) 都是从某个未知的分布 \(q_\text{data}(\mathbf{z})\) 中采样得到的。我们的目标是学习一个生成模型 \(p_\theta(\mathbf{z})\),使得它能够很好地拟合数据分布 \(q_\text{data}(\mathbf{z})\),从而能够生成与训练数据相似的新样本: \(p_\theta(\mathbf{z}) \approx q_\text{data}(\mathbf{z})\)。在前3节的Lecture中,我们将会focus在Unconditioned生成模型上,即我们不考虑任何条件信息(Prompts)的情况下进行生成建模。
我们有很多种方法可以用来学习生成模型,比如PixelCNN, GAN, VAE, Diffusion Models等。其中Diffusion Models是现在主流的生成模型,它的核心思想就是:从一个Noise开始,逐步去噪,最终得到一个清晰的图像。如下图所示:

这种方式有什么好处:
- Noise 是一个简单的分布,我们可以很容易地从中采样。
- 在这个过程中,引入了randomness,这使得模型能够生成多样化的样本,因为每次采样的Noise都不一样。
- Gaussian Distribution的性质使得我们可以使用简单的数学工具来分析和优化模型。
接下来,我们来看一下Diffusion Models的开山模型:Denoised Diffusion Probabilistic Models (DDPM) (Ho, Jain, and Abbeel 2020)。
2 Denoised Diffusion Probabilistic Models (DDPM)
NOTE:More details about DDPM
在这里,我们简单的介绍一下DDPM,对于具体的细节推导和代码实现,请参考我的100-Papers-with-Code系列里的DDPM这篇文章。
在上一节,我们提到了Diffusion Models的核心思想是从一个Noise开始,逐步去噪,最终得到一个清晰的图像。那么DDPM就是基于这个思想提出的一种具体的实现方法。DDPM的核心思想是通过一个前向过程(Forward Diffusion Process)和一个反向过程(Reverse Denoising Process)来实现这个逐步去噪的过程。我们来具体看一下
2.1 Forward Diffusion Process
图Figure 1 中\(x_0\) 到 \(x_T\) 的过程就是一个前向过程(Forward Diffusion Process),在这个过程中,我们逐步向数据添加噪声,最终得到一个完全被噪声覆盖的图像。这个过程可以用以下的公式来描述:
{kind=link}
\[ q(\mathbf{x}_t | \mathbf{x}_{t-1}) = \mathcal{N}(\mathbf{x}_t; \sqrt{1 - \beta_t} \mathbf{x}_{t-1}, \beta_t \mathbf{I}) \tag{1}\]
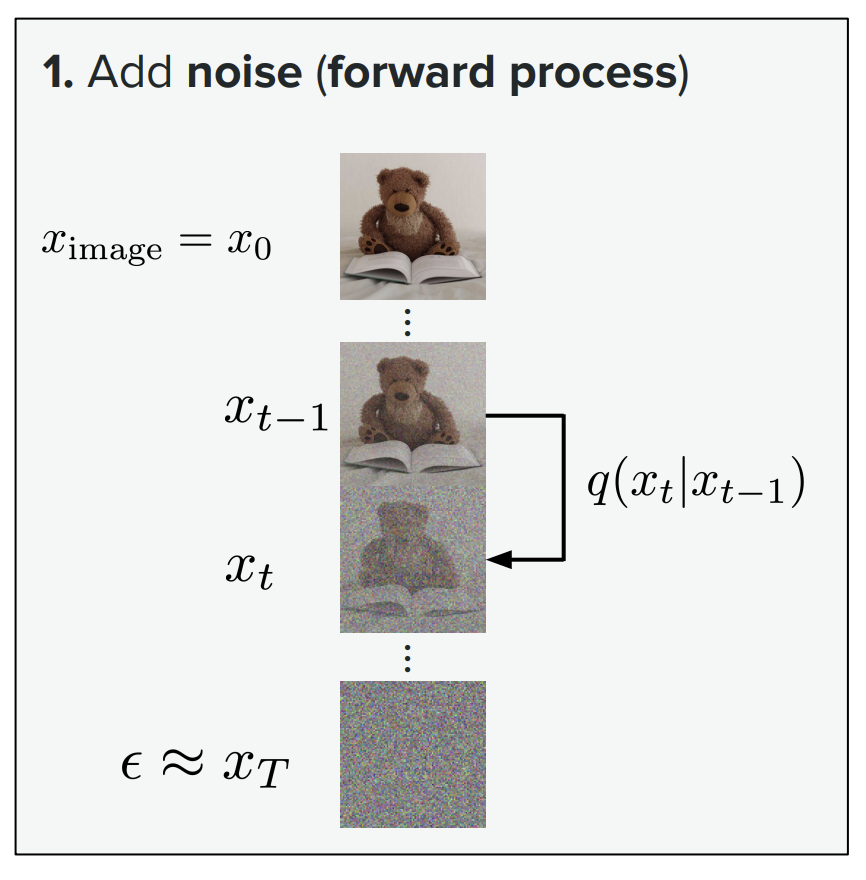
需要注意的是,在这个Forward Diffusion Process中,所有的都是已知的,因为所有的参数,包括噪声的方差 \(\beta_t\) 都是我们自己设定的。因此,我们可以很容易地从这个过程中采样得到任意时间步 \(t\) 的图像 \(\mathbf{x}_t\),而不需要依赖于任何模型。我们可以通过以下的公式来直接采样得到 \(\mathbf{x}_t\):
\[ \mathbf{x}_t = \sqrt{1 - \beta_t} \mathbf{x}_{t-1} + \sqrt{\beta_t} \boldsymbol{\epsilon}_t, \quad \boldsymbol{\epsilon}_t \sim \mathcal{N}(\mathbf{0}, \mathbf{I}) \tag{2}\]
通过Recursive的方式,我们可以将上面的公式展开,得到一个更为直接的采样公式:
\[ \begin{split} \mathbf{x}_t &= \sqrt{1 - \beta_t} \mathbf{x}_{t-1} + \sqrt{\beta_t} \boldsymbol{\epsilon}_t \\ &= \sqrt{1 - \beta_t} \left( \sqrt{1 - \beta_{t-1}} \mathbf{x}_{t-2} + \sqrt{\beta_{t-1}} \boldsymbol{\epsilon}_{t-1} \right) + \sqrt{\beta_t} \boldsymbol{\epsilon}_t \\ &= \sqrt{1 - \beta_t} \sqrt{1 - \beta_{t-1}} \mathbf{x}_{t-2} + \sqrt{1 - \beta_t} \sqrt{\beta_{t-1}} \boldsymbol{\epsilon}_{t-1} + \sqrt{\beta_t} \boldsymbol{\epsilon}_t \\ &= \cdots \\ &= \sqrt{\bar{\alpha}_t} \mathbf{x}_0 + (1 - \bar{\alpha}_t) \boldsymbol{\epsilon}_t \end{split} \tag{3}\]
其中 \(\bar{\alpha}_t = \prod_{s=1}^t (1 - \beta_s)\)。通过这个公式,我们可以直接从原始图像 \(\mathbf{x}_0\) 和一个随机噪声 \(\boldsymbol{\epsilon}_t\) 中采样得到任意时间步 \(t\) 的图像 \(\mathbf{x}_t\)。
需要注意的一点是, \(\beta_t\)的选择,因为我们在Forward Diffusion Process的最后,希望得到一个完全被噪声覆盖的图像,也就是说 \(\mathbf{x}_T\) 应该接近于一个纯噪声图像。因此,我们需要选择一个合适的 \(\beta_t\) 序列,使得在 \(t=T\) 时,\(\bar{\alpha}_T\) 非常小,从而使得 \(\mathbf{x}_T\) 主要由噪声组成。通常情况下,我们会选择一个线性递增的 \(\beta_t\) 序列,例如:
\[ \beta_t = \beta_\text{start} + \frac{t}{T} (\beta_\text{end} - \beta_\text{start}) \tag{4}\]
在这个公式中,
2.2 Reverse Denoising Process
图Figure 1 中\(x_T\) 到 \(x_0\) 的过程就是一个反向过程(Reverse Denoising Process),在这个过程中,我们逐步去噪,最终得到一个清晰的图像。总的来说,我们的训练目标是:
\[ \max_\theta \mathbb{E}_{\mathbf{x}_0 \sim q_\text{data}(\mathbf{x}_0)} \left[ \log p_\theta(\mathbf{x}_0) \right] \tag{5}\]
我们可以通过Maximize Evidence Lower Bound (ELBO) 来优化这个目标函数:
\[ \mathbb{E}_{\mathbf{x}_0 \sim q_\text{data}(\mathbf{x}_0)} \left[ \log p_\theta(\mathbf{x}_0) \right] \geq \mathbb{E}_{\mathbf{x}_0 \sim q_\text{data}(\mathbf{x}_0)} \left[ \log \frac{p_\theta(\mathbf{x}_{0:T})}{q(\mathbf{x}_{1:T} | \mathbf{x}_0)} \right] \tag{6}\] (具体的推导请参考这篇文章)
把这个ELBO展开,我们可以得到以下的分解:
\[ \begin{split} \mathbb{E}_{\mathbf{x}_0 \sim q_\text{data}(\mathbf{x}_0)} \left[ \log p_\theta(\mathbf{x}_0) \right] &\geq \mathbb{E}_{\mathbf{x}_0 \sim q_\text{data}(\mathbf{x}_0)} \left[ \log \frac{p_\theta(\mathbf{x}_{0:T})}{q(\mathbf{x}_{1:T} | \mathbf{x}_0)} \right] \\ &= \mathbb{E}_{\mathbf{x}_0 \sim q_\text{data}(\mathbf{x}_0)} \left[ \log p_\theta(\mathbf{x}_T) + \sum_{t=1}^T \log \frac{p_\theta(\mathbf{x}_{t-1} | \mathbf{x}_t)}{q(\mathbf{x}_t | \mathbf{x}_{t-1})} \right] \\ &= \mathbb{E}_{\mathbf{x}_0 \sim q_\text{data}(\mathbf{x}_0)} \left[ \log p_\theta(\mathbf{x}_T) + \sum_{t=1}^T \mathbb{E}_{\mathbf{x}_t \sim q(\mathbf{x}_t | \mathbf{x}_0)} \left[ \log \frac{p_\theta(\mathbf{x}_{t-1} | \mathbf{x}_t)}{q(\mathbf{x}_t | \mathbf{x}_{t-1})} \right] \right] \end{split} \tag{7}\]
最后我们得到以下的训练目标:
\[ \mathcal{L}(\theta) = \mathbb{E}_{t, x_0, \boldsymbol{\epsilon}} \left[ \| \boldsymbol{\epsilon} - \boldsymbol{\epsilon}_\theta(\mathbf{x}_t, t) \|^2 \right] \tag{8}\]
2.3 Training DDPM
有了上面的数据,目标函数,模型(之后我们会介绍),我们就可以开始训练DDPM了。训练的过程非常简单,我们只需要按照以下的步骤进行:
- 从数据分布 \(q_\text{data}(\mathbf{x}_0)\) 中采样一个图像 \(\mathbf{x}_0\)。
- 从均匀分布 \(U(1, T)\) 中采样一个时间步 \(t\)。
- 从标准正态分布 \(\mathcal{N}(\mathbf{0}, \mathbf{I})\) 中采样一个噪声 \(\boldsymbol{\epsilon}\)。
- 根据公式Equation 2,计算得到 \(\mathbf{x}_t\)。
- 将 \(\mathbf{x}_t\) 和 \(t\) 输入到模型 \(\boldsymbol{\epsilon}_\theta\) 中,得到预测的噪声 \(\boldsymbol{\epsilon}_\theta(\mathbf{x}_t, t)\)。
- 计算损失函数 \(\mathcal{L}(\theta)\),并且使用反向传播来更新模型参数 \(\theta\)。
- 重复上述步骤,直到模型收敛。
我们来看看简单代码实现:
# Assume we have:
# dataloader, model, optimizer
x_0 = next(iter(dataloader)) # Step 1
t = torch.randint(1, T + 1, (x_0.size(0),)) # Step 2
epsilon = torch.randn_like(x_0) # Step 3
x_t = sqrt_alpha_bar[t] * x_0 + sqrt_one_minus_alpha_bar[t] * epsilon # Step 4
epsilon_theta = model(x_t, t) # Step 5
loss = F.mse_loss(epsilon_theta, epsilon) # Step 6
optimizer.zero_grad()
loss.backward()
optimizer.step() # Step 72.4 Sampling from DDPM
\[ \mathbf{x}_{t-1} = \frac{1}{\sqrt{1 - \beta_t}} \left( \mathbf{x}_t - \frac{\beta_t}{\sqrt{1 - \bar{\alpha}_t}} \boldsymbol{\epsilon}_\theta(\mathbf{x}_t, t) \right) + \sqrt{\beta_t} \mathbf{z}, \quad \mathbf{z} \sim \mathcal{N}(\mathbf{0}, \mathbf{I}) \tag{9}\]
训练完成之后,我们看一下如何从训练好的DDPM模型中采样。采样的过程就是图Figure 1 中\(x_T\) 到 \(x_0\) 的过程,也就是一个反向过程(Reverse Denoising Process)。我们可以按照以下的步骤进行采样:
- 从标准正态分布 \(\mathcal{N}(\mathbf{0}, \mathbf{I})\) 中采样一个噪声 \(\mathbf{x}_T\)。
- 对于 \(t = T, T-1, \ldots, 1\),执行以下步骤:
- 将 \(\mathbf{x}_t\) 和 \(t\) 输入到模型 \(\boldsymbol{\epsilon}_\theta\) 中,得到预测的噪声 \(\boldsymbol{\epsilon}_\theta(\mathbf{x}_t, t)\)。
- 根据公式Equation 9,计算得到 \(\mathbf{x}_{t-1}\)。
- 最终得到 \(\mathbf{x}_0\),这就是我们生成的图像。
用代码实现的话,可以写成如下的形式:
# Assume we have:
# model, T, beta, sqrt_alpha_bar, sqrt_one_minus_alpha_bar
x_t = torch.randn(batch_size, channels, height, width) # Step 1
for t in range(T, 0, -1): # Step 2
epsilon_theta = model(x_t, t) # Step 2a
z = torch.randn_like(x_t) if t > 1 else torch.zeros_like(x_t) # Step 2b
x_t = (1 / sqrt_alpha_bar[t]) * (x_t - (beta[t] / sqrt_one_minus_alpha_bar[t]) * epsilon_theta) + sqrt_beta[t] * z需要注意的是,在采样的过程中,我们在每一步都添加了一个随机噪声 \(\mathbf{z}\),这使得每次采样的结果都是不同的,从而保证了生成样本的多样性。
显然,这个采样过程是非常慢的,因为我们需要进行 \(T\) 次迭代才能得到一个样本。通常情况下,\(T\) 的值可以是1000或者更多,这就意味着我们需要进行1000次迭代才能得到一个样本,这对于实际应用来说是非常不友好的。因此,在下一节,我们将会介绍一种加速Diffusion Models的方法:Denoising Diffusion Implicit Models (DDIM)。
3 Denoising Diffusion Implicit Models (DDIM)
Denoising Diffusion Implicit Models (DDIM) (Song, Meng, and Ermon 2022) 是一种加速Diffusion Models的方法,它的核心思想是通过引入一个新的反向过程(Reverse Denoising Process)来实现更快的采样。DDIM的反向过程可以用以下的公式来描述:
\[ \mathbf{x}_{t-1} = \sqrt{\bar{\alpha}_{t-1}} \left( \frac{\mathbf{x}_t - \sqrt{1 - \bar{\alpha}_t} \boldsymbol{\epsilon}_\theta(\mathbf{x}_t, t)}{\sqrt{\bar{\alpha}_t}} \right) + \sqrt{1 - \bar{\alpha}_{t-1}} \boldsymbol{\epsilon}_\theta(\mathbf{x}_t, t) \tag{10}\]
既然我们在Forward Diffusion Process的时候是一个Markov Process,那么我们在Reverse Denoising Process的时候也可以是一个Markov Process,也就是说我们可以直接从 \(\mathbf{x}_T\) 采样得到 \(\mathbf{x}_{T-1}\),然后再从 \(\mathbf{x}_{T-1}\) 采样得到 \(\mathbf{x}_{T-2}\),以此类推,最终得到 \(\mathbf{x}_0\)。这样,我们就不需要进行 \(T\) 次迭代了,而是可以直接从 \(\mathbf{x}_T\) 采样得到 \(\mathbf{x}_0\),大大加快了采样的速度。