09: Masked Autoencoders Are Scalable Vision Learners(MAE )
Self Supervised Learning
Representation Learning
AutoEncoder
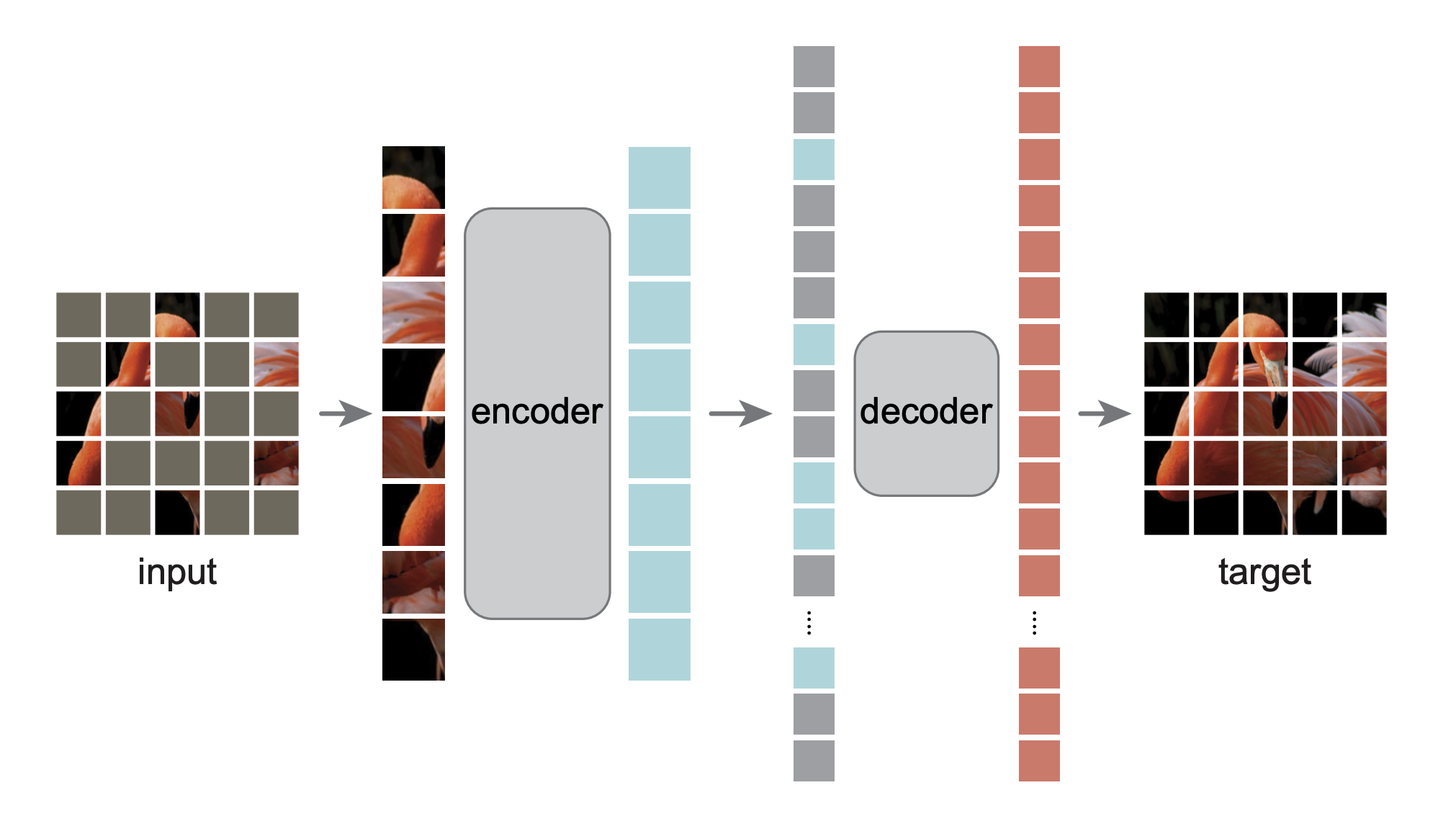
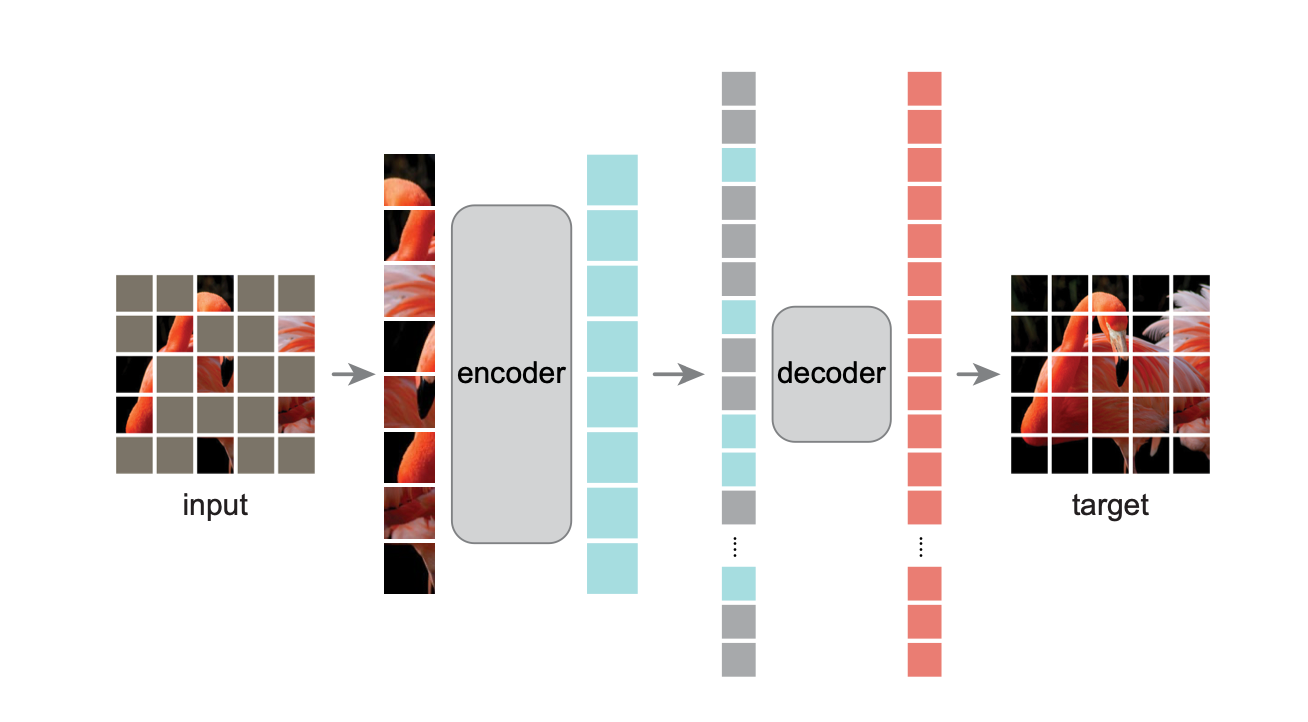
一种通过随机遮挡大比例图像 patch 并重建缺失内容进行自监督学习的方法,使 Vision Transformer 能以更高效率和更好可扩展性学习通用视觉表示。
 # Preliminary
# Preliminary
1 MAE
1.1 Experiment
2 Summary
3 Key Concepts
4 Q & A
6 Preliminary
7 MAE
8 Summary
9 Key Concepts
10 Q & A
11 Related resource & Further Reading