Note
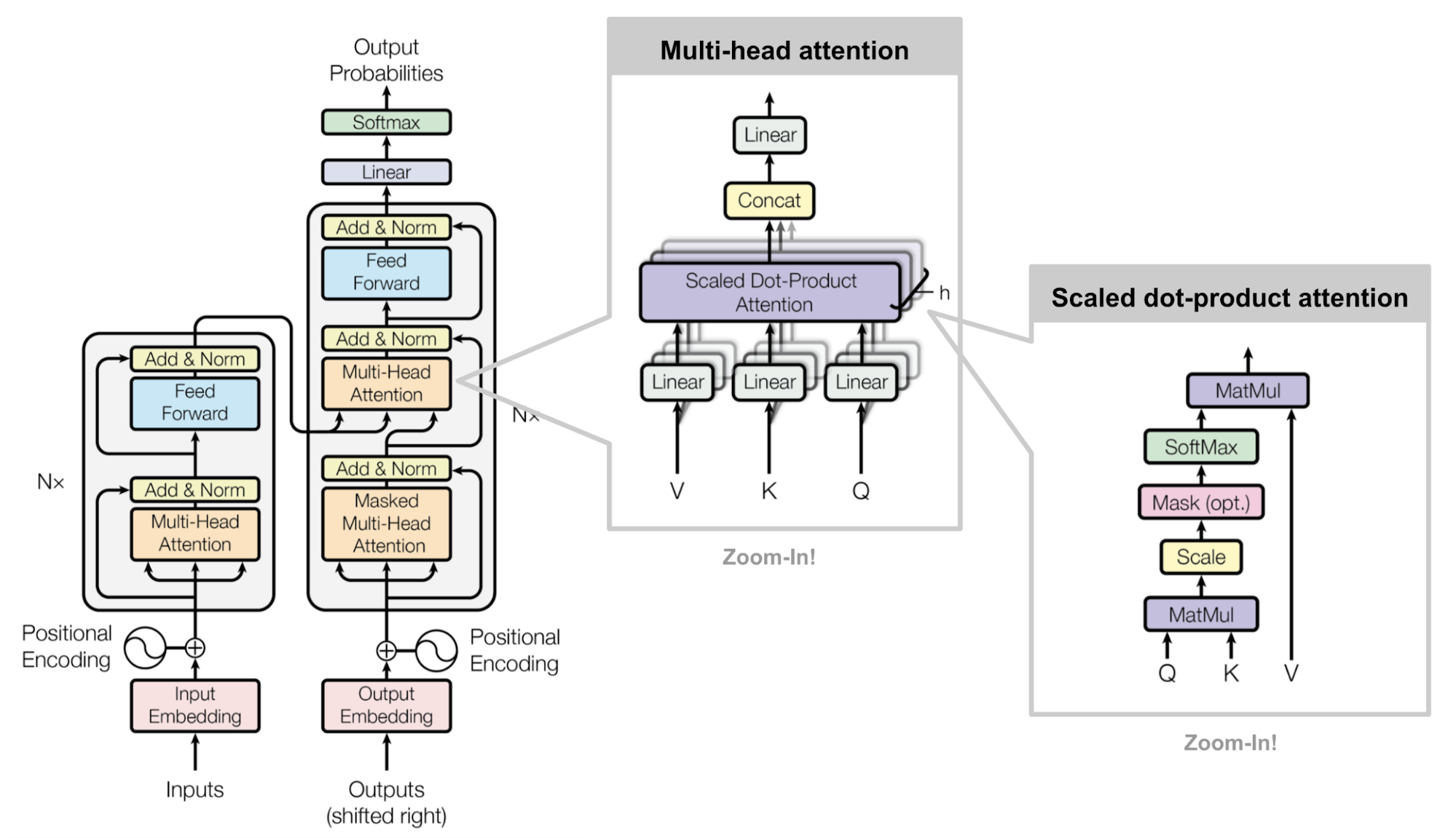
01: Attention is all you need (Transformer )
Transformer
Attention
NLP
Architecture
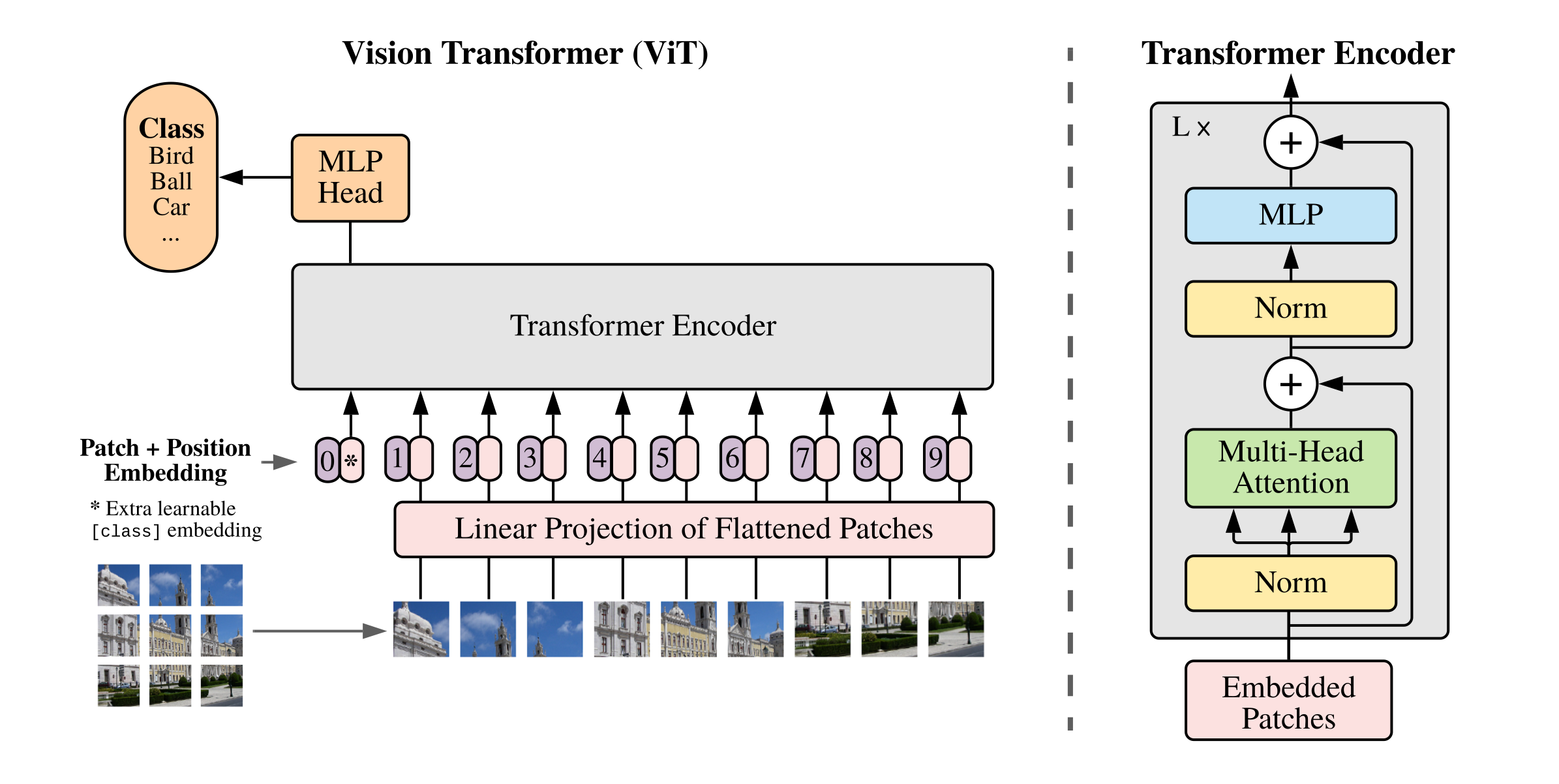
02: AN IMAGE IS WORTH 16X16 WORDS: TRANSFORMERS FOR IMAGE RECOGNITION AT SCALE (Vision-Transformer )
Computer Vision
Transformer
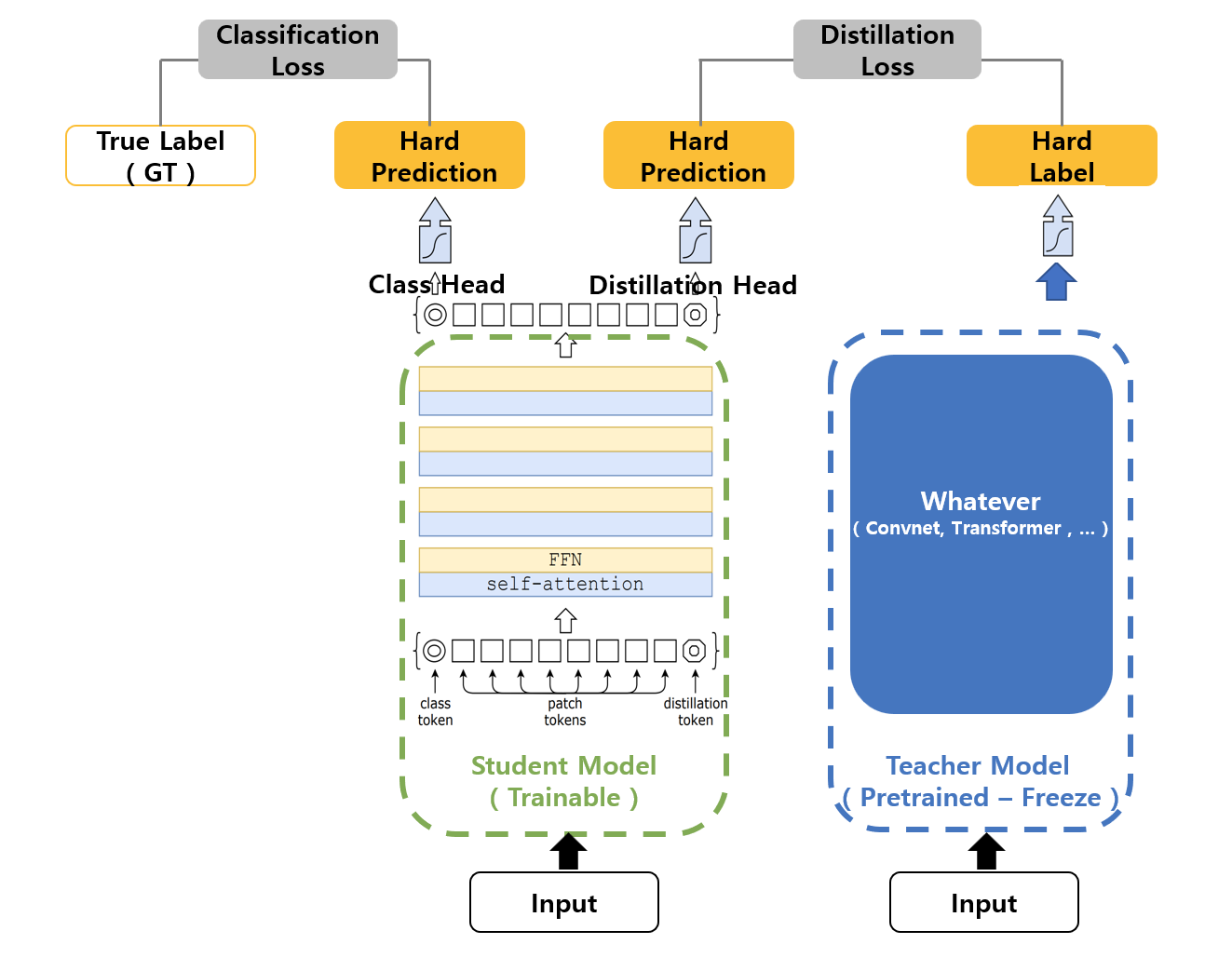
03: Training data-efficient image transformers & distillation through attention (DeiT )
Computer Vision
Transformer
Knowledge Distillation
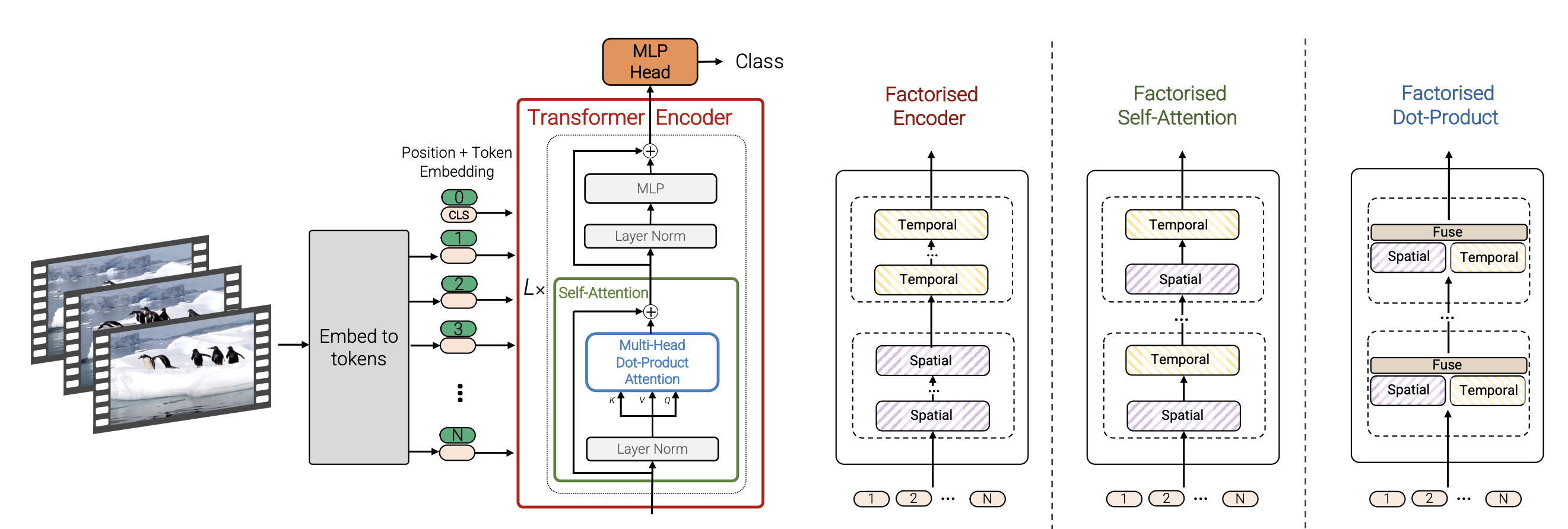
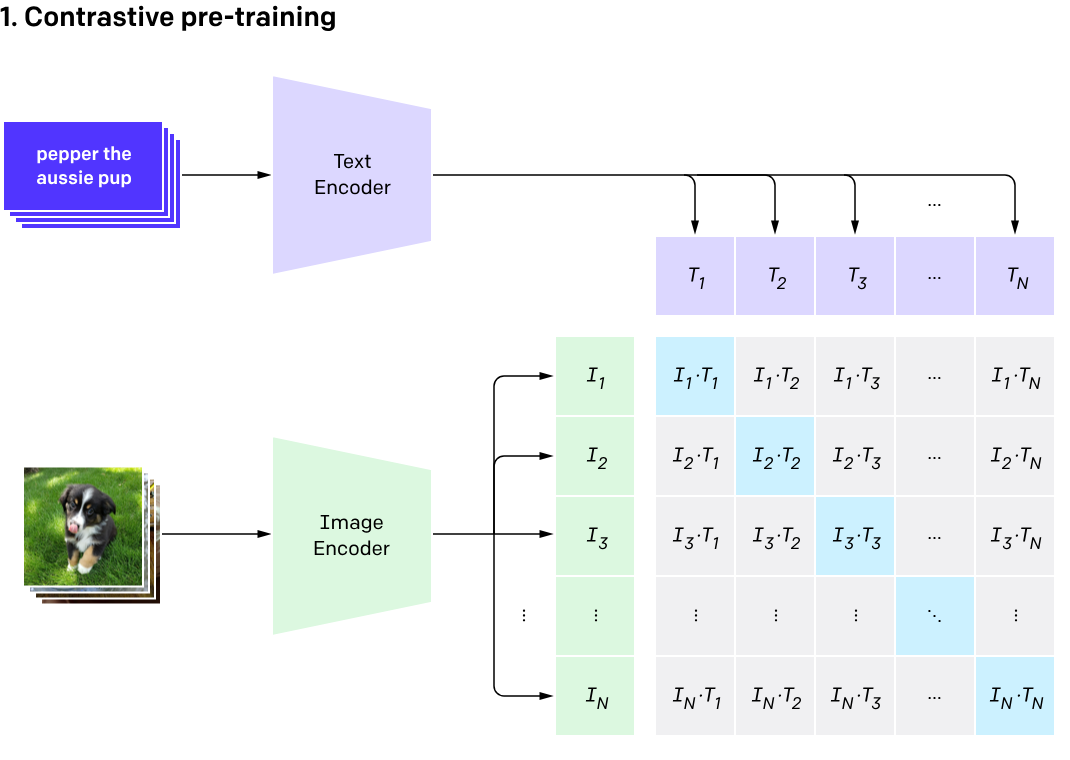
06: Learning Transferable Visual Models From Natural Language Supervision (CLIP )
Multi Modality
Representation Learning

07: Emerging Properties in Self-Supervised Vision Transformers (DINO )
Self Supervised Learning
Representation Learning
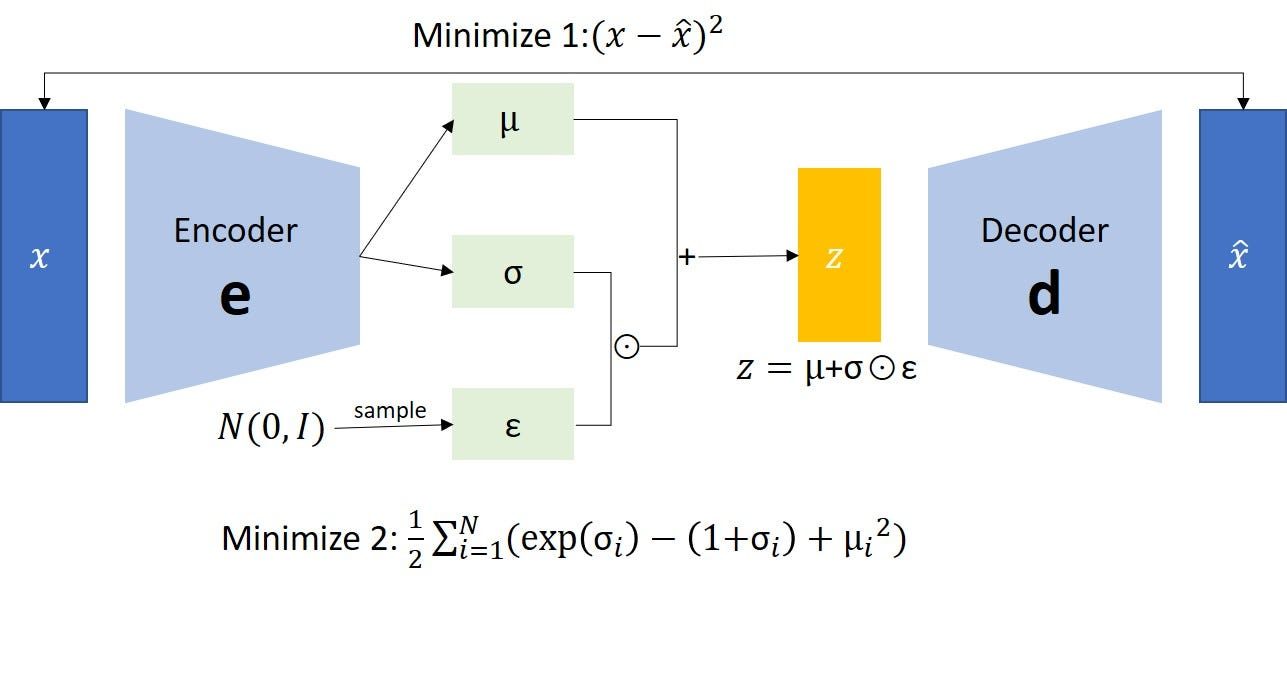
08: Auto-Encoding Variational Bayes (VAE )
Self Supervised Learning
Generative Model
Representation Learning
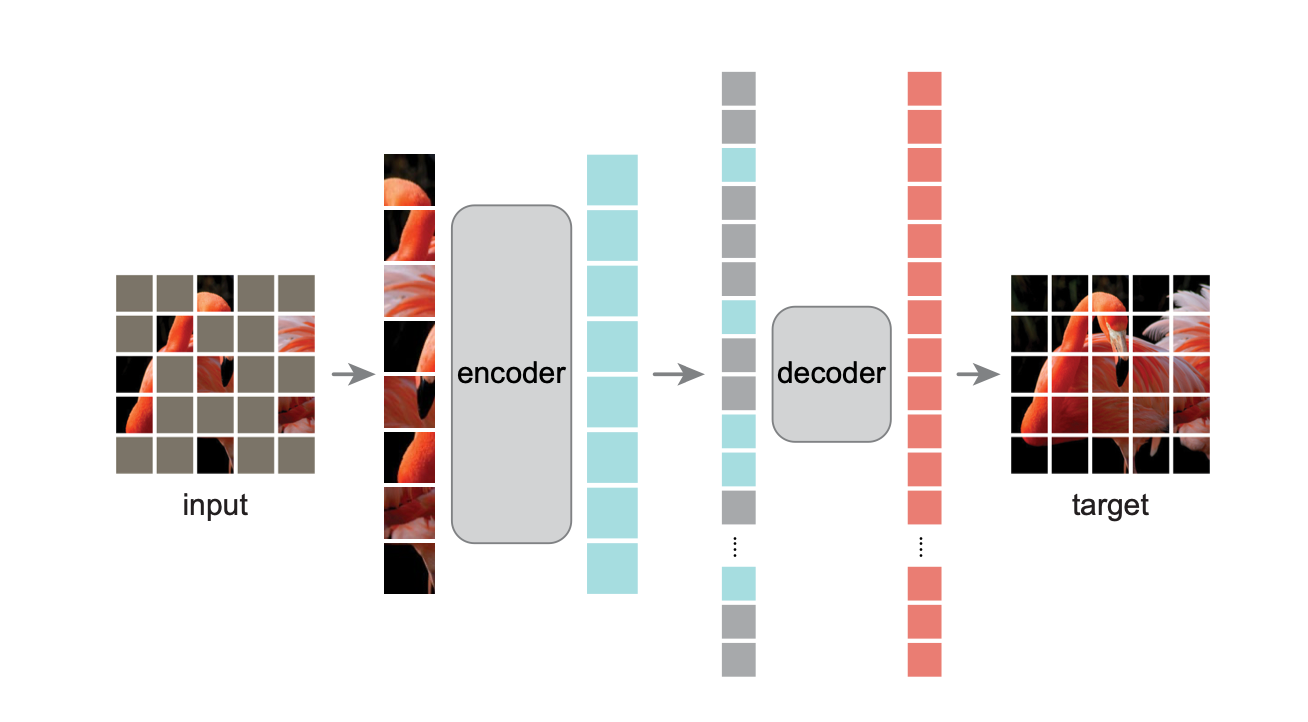
09: Masked Autoencoders Are Scalable Vision Learners(MAE )
Self Supervised Learning
Representation Learning
AutoEncoder
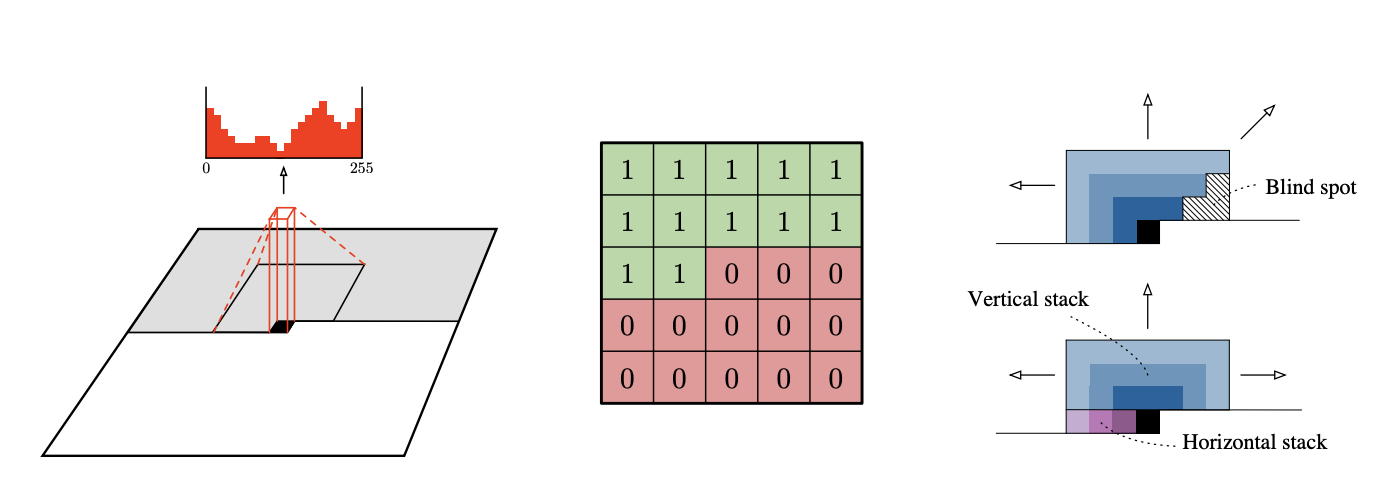
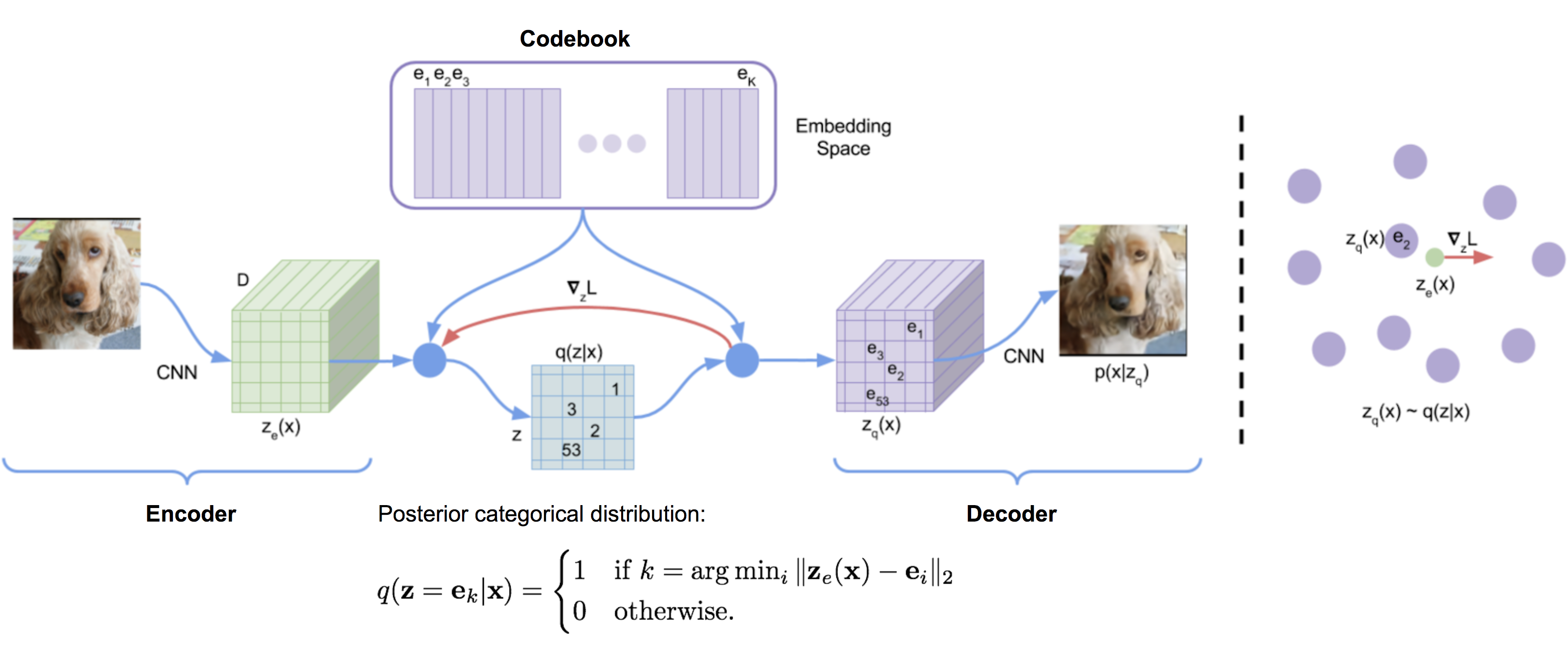
11: Neural Discrete Representation Learning (VQ_VAE )
Representation Learning
Self Supervised Learning
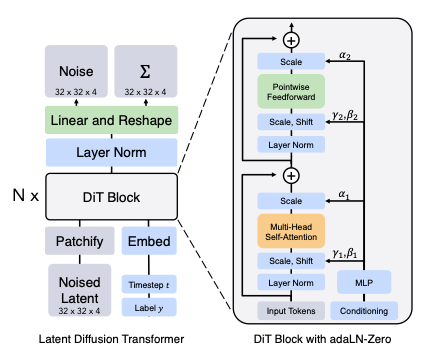
16: Scalable Diffusion Models with Transformers (DiT )
Generative Model
Diffusion Model
No matching items