Assignment 05: LLM Alignment: SFT, Expert Iteration, GRPO & DPO
1 Dataset Preparation & Model Download
TL;DR: 快速版
只需将运行以下命令,We are ready to GO!!!
下载代码
安装依赖,下载数据集和模型
pip install uv
uv sync --no-install-package flash-attn
uv sync
source .venv/bin/activate
hf download YuYangZhang/Reasoning-Dataset --repo-type dataset --local-dir data
python download_model.py \
--repo-id Qwen/Qwen2.5-Math-1.5B \
--save-dir models/Qwen2.5-Math-1.5B \
--method snapshot --no-symlinks --verify我们先来下载模型权重,只需一个命令:
python download_model.py \
--repo-id Qwen/Qwen2.5-Math-1.5B \
--save-dir models/Qwen2.5-Math-1.5B \
--method snapshot --no-symlinks --verify通过上面的命令,我们就可以把Qwen2.5-Math-1.5B模型下载到models/Qwen2.5-Math-1.5B目录下。
在这个Assignment中,我们将会用到Math Dataset,不过Assignment中,由于版权问题,并没有提供完整的数据,因此我们需要自行下载数据集,在这个Assignment中,我们主要会用到以下两个数据集:
- GSM8K Dataset:一个包含8,500多个高中水平数学问题的数据集,专注于逐步推理和解决方案生成。(这个数据集在Assignment中已经提供
data/gsm8k) - MATH Dataset: 这个数据集包含12,500多个高中和大学水平的数学问题,涵盖多个主题和难度级别 Link。
我们现在下载MATH:
hf download nlile/hendrycks-MATH-benchmark \
--repo-type dataset \
--local-dir ./data/hendrycks-MATH-benchmark
mv ./data/hendrycks-MATH-benchmark ./data/math接下来,我们来预处理一下这些数据集,因为不同的数据集格式不一样,我们需要把他们处理成统一的格式, 以便我们后续的训练。先来看GSM8K数据集的格式:
{
"question": "Natalia sold clips to 48 of her friends in April, and then she sold half as many clips in May. How many clips did Natalia sell altogether in April and May?",
"answer": "Natalia sold 48/2 = <<48/2=24>>24 clips in May.\nNatalia sold 48+24 = <<48+24=72>>72 clips altogether in April and May.\n#### 72"}每个样本包含 question 和 answer 两个字段,我们需要把他们处理成 prompt 和 cot 的格式,并且提取出里面的答案:
assignment5-alignment/cs336_alignment/dataset_utils/gsm8k.py
def extract_gsm8k_answer(answer: str) -> str:
ANS_RE = re.compile(r"####\s*([\-0-9\.\,]+)")
match = ANS_RE.search(answer)
if match:
return match.group(1).strip().replace(",", "")
return "[invalid]"
def process_row(row: Dict[str, Any]):
problem = row["question"]
cot = row["answer"]
clean_cot = re.sub(r"\s*\n####\s*-?\d+(?:\.\d+)?\s*$", "", cot)
answer = extract_gsm8k_answer(row["answer"])
clean_cot = wrap_cot_with_answer(clean_cot, answer)
return problem, str(clean_cot), str(answer).lower() if answer is not None else None在预处理之后,我们会把数据集处理成下面的格式:
{
"question": "Natalia sold clips to 48 of her friends in April, and then she sold half as many clips in May. How many clips did Natalia sell altogether in April and May?",
"cot": "Natalia sold 48/2 = <<48/2=24>>24 clips in May.\nNatalia sold 48+24 = <<48+24=72>>72 clips altogether in April and May.\n</think> <answer>72</answer>",
"answer": "72"
}类似地,我们也需要对MATH数据集进行预处理,MATH数据集的格式如下:
{
"problem": "How many vertical asymptotes does the graph of $y=\\frac{2}{x^2+x-6}$ have?",
"solution": "The denominator of the rational function factors into $x^2+x-6=(x-2)(x+3)$. Since the numerator is always nonzero, there is a vertical asymptote whenever the denominator is $0$, which occurs for $x = 2$ and $x = -3$. Therefore, the graph has $\\boxed{2}$ vertical asymptotes.",
"answer": "2"
}assignment5-alignment/cs336_alignment/dataset_utils/math.py
def process_row(row: Dict[str, Any]):
problem = row["problem"]
cot = row["solution"]
if row["answer"] is None:
answer = extract_final_answer_from_text(cot)
else:
answer = row["answer"]
cot = wrap_cot_with_answer(cot, answer)
return problem, str(cot), str(answer).lower() if answer is not None else None在处理之后,我们会把MATH数据集处理成下面的格式:
{
"question": "How many vertical asymptotes does the graph of $y=\\frac{2}{x^2+x-6}$ have?",
"cot": "The denominator of the rational function factors into $x^2+x-6=(x-2)(x+3)$. Since the numerator is always nonzero, there is a vertical asymptote whenever the denominator is $0$, which occurs for $x = 2$ and $x = -3$. Therefore, the graph has $\\boxed{2}$ vertical asymptotes.\n</think> <answer>2</answer>",
"answer": "2"
}具体的细节,看assignment5-alignment/cs336_alignment/dataset_utils 文件夹下的代码。以及 assignment5-alignment/preprocess.py 这个脚本。在这里就不赘述了。处理完之后,我们会有:
data/
├── alpaca_eval/
├── gsm8k/
├── math/
├── mmlu/
├── pre-processed/
│ ├── gsm8k/
│ │ ├── test.jsonl
│ │ └── train.jsonl
│ └── math/
│ ├── test.jsonl
│ └── train.jsonl当然,大家也可以选择直接使用我已经处理好的数据集, 直接从这里下载即可。或者使用下面的命令:
2 Zero-Shot Evaluation & vLLM
2.1 vLLM
在这个Assignment中,我们会使用vLLM 来进行模型的推理, 以便我们可以更快的进行评估和训练。 以下几个方法:
assignment5-alignment/cs336_alignment/vllm_utils.py
def init_vllm(model_id: str, device: str, seed: int, gpu_memory_utilization: float = 0.85):
vllm_set_random_seed(seed)
world_size_patch = patch("torch.distributed.get_world_size", return_value=1)
profiling_patch = patch(
"vllm.worker.worker.Worker._assert_memory_footprint_increased_during_profiling", return_value=None
)
with world_size_patch, profiling_patch:
return LLM(
model=model_id,
device=device,
dtype=torch.bfloat16,
enable_prefix_caching=True,
gpu_memory_utilization=gpu_memory_utilization,
)
def load_policy_into_vllm_instance(policy: PreTrainedModel, llm: LLM):
state_dict = policy.state_dict()
llm_model = llm.llm_engine.model_executor.driver_worker.model_runner.model
llm_model.load_weights(state_dict.items())
def generate_responses(vllm: LLM, prompts: list[str], sampling_params) -> list[str]:
outputs = vllm.generate(
prompts,
sampling_params=sampling_params,
)
responses = [output.outputs[0].text for output in outputs]
return responses当我们需要使用vLLM进行推理时,我们只需要先初始化vLLM实例, 之后把模型权重load进去, 最后调用generate_responses函数即可完成推理:
vllm = init_vllm(
model_id=MODEL_NAME,
device=str(get_device(rank=1)),
seed=42,
gpu_memory_utilization=0.85,
)
sampling_params = SamplingParams(
max_tokens=1024, temperature=1, top_p=1, stop=["</answer>"], include_stop_str_in_output=True
)
load_policy_into_vllm_instance(policy, vllm)
responses = generate_responses(
vllm,
prompts,
sampling_params=sampling_params,
)接下来,我们先来评估一下Qwen2.5-Math-1.5B在MATH和GSM8K数据集上的表现, 具体的评估代码在 assignment5-alignment/eval.py 以及 assignment5-alignment/cs336_alignment/eval.py, 运行下面的命令即可:
来看一下评估结果:
| dataset_path | total | answer_correct | format_correct | reward_1 | formatted_but_answer_wrong | answer_accuracy |
|---|---|---|---|---|---|---|
| math/train.jsonl | 12000 | 359 | 2038 | 359 | 1679 | 0.029 |
| math/test.jsonl | 500 | 13 | 77 | 13 | 64 | 0.026 |
| gsm8k/train.jsonl | 7473 | 232 | 1433 | 232 | 1201 | 0.031 |
| gsm8k/test.jsonl | 1319 | 41 | 258 | 41 | 217 | 0.031 |
可以看到,在Zero-Shot的情况下,Qwen2.5-Math-1.5B在MATH和GSM8K数据集上的表现都非常差,只有大约2.6%到3.1%的准确率。这也符合预期,因为Qwen2.5-Math-1.5B虽然是一个强大的语言模型,但在没有经过专门微调的情况下,其在复杂数学问题上的表现仍然有限。
3 Supervised Fine Tuning
首先第一个算法就是Supervised Fine Tuning(SFT)。在 Alignment 训练里,SFT 往往被看作“第一阶段”:用人工标注的高质量数据,把 base model 从“会说话”推到“更像助理、更会按指令做事”。在Post-Training中主要起到一个 warm-start 的作用。为之后的Reinforcement Learning 算法做一个铺垫,这样做的主要目的有两个:
- Warm-start:让模型先变“像助理”
base model 可能会乱格式、跑题、答非所问。SFT 直接用示范数据教它: • 看到 prompt 该怎么组织输出 • 该不该写推理、怎么写 • 最终答案要放到
- 稳定、样本效率高(比 RL 好训)
SFT 就是最大似然/交叉熵,训练目标明确、梯度稳定、收敛更可控: • 不需要 reward model • 不需要 rollout、优势估计、clip/KL 等一堆超参 • 同样计算量下,通常比 RL 更“省事、省算力”
- 学会“正确的输出分布”,减少 RL 的探索难度
RL 只给“好/不好”的信号(甚至只有最终对错),如果模型一开始输出很乱,RL 会非常难学、方差很大。 SFT 先把策略带到一个合理区域,RL 才更容易在此基础上做提升(例如提升正确率、减少啰嗦、对齐偏好)。
- 用 response_mask 只优化回答,不逼模型“背 prompt”
你写的 response_mask 很关键:SFT 把 prompt 当条件,只在 response token 上算 loss: • 避免模型花 capacity 去重建 prompt • 训练信号更聚焦在“该怎么回答” 这在长 prompt/长上下文时特别重要。
- 提供“行为先验”,防止 RL 训练崩坏
在 PPO/GRPO 里经常会担心 reward hacking、模式坍塌、输出退化。 SFT 提供一个强先验:即使 RL 更新过猛,KL/参考模型通常也把它拉回 SFT 附近,让训练更稳。
SFT的算法如下
其实,SFT 可以视作一个Imitation Learning,其过程就是
- 给定一个Prompt \(P\), 以及一个对应的Response \(R\),
- 将Prompt传入模型,我们希望可以模型可以根据这个Prompt, 来生成出与对应Response 一样的回答。
这个也就是用过 Maximize Likelihood 来学习,也就是最小化Loss Function,在这个情景中,也就是 Cross Entropy Loss。 \[ \mathcal{L}_{\text{SFT}}(\theta) = - \sum_{t=1}^{|R|} \log p_\theta(R_t \mid P, R_{<t}) \tag{1}\]
接下来,让我们先定义一些helper 函数,来帮我们完成这一系列:
3.1 Tokenize Prompt and Output
首先我们要定义的第一个函数就是 tokenize_prompt_and_output(), 它的作用,顾名思义,就是接收一系列的prompts,和 Response,并且tokenize他们,并且返回他们的ids。不过,需要注意的一点,也是很重要的一点就是,我们要同时返回Response Mask。 我们先来看看这个Response Mask的作用是什么:
假如我们有一个 \(q\) 和 \(o\), 我们将它并在一起,得到了我们的函数 \([q, o ]\), 我们将整段传入Model,在没有Response Mask的情况下,模型就是对所有的token计算loss,这样模型就会被迫去预测:
- prompt 里的下一个 token(本质是在“复述/重建 prompt”)
- output 里的 token(这才是我们真正关心的)
但是在SFT训练的阶段, prompt 是输入条件,我们并不希望优化模型去“背 prompt 的分布”,只希望它在给定 prompt 后生成正确输出。所以用 response_mask 把 loss 限定在 output token 上: 训练信号只来自回答部分。当然,除此之外,Response Mask还对应着pad tokens 举个直观的例子:
假设输入是:
- q: “2+2=?”
- o: “4”
拼接后 token 序列是:[q_tokens][o_tokens][pad...]
response_mask 会像这样:
- q_tokens → False False False …
- o_tokens → True True …
- pad → False False …
结果:loss 只在 “4” 的 token 上算,prompt 部分完全不参与。
我们来看看代码是怎么实现的:
首先第一步自然是Tokenize Prompts和Response:
assignment5-alignment/cs336_alignment/algs/utils.py
注意! 在这里,我们并不会返回Tensor 返回的是List, 并且List里面每个元素的长度是不一样的,
接下来, 我们把这两个List中的内容 concat 在一起,得到 [q, o], 并且计算出我们的Response Mask
assignment5-alignment/cs336_alignment/algs/utils.py
到目前为止,input_ids 和 response_mask 里面的内容长度不一样长,所以我们要将它Pad 到同样的长度,这样才可以传入模型:
assignment5-alignment/cs336_alignment/algs/utils.py
MAX_LEN = max(len(ids) for ids in input_ids)
# 151643 for Qwen/Qwen2.5-Math-1.5B
pad_id = tokenizer.pad_token_id if tokenizer.pad_token_id is not None else tokenizer.eos_token_id
def pad_to(x, value):
return x + [value] * (MAX_LEN - len(x))
full = torch.tensor([pad_to(x, pad_id) for x in input_ids], dtype=torch.long)
response_mask = torch.tensor([pad_to(x, False) for x in response_mask], dtype=torch.bool)接下来就构建我们的input和labels, Labels中记录的是inputs中的下一个:
assignment5-alignment/cs336_alignment/algs/utils.py
需要注意的是, Response Mask中是Labels中的mask,而不是inputs_ids中的mask。
TL;DR: Tokenization & Prompts
在这里函数中,我们主要做两件事情:
- Tokenize Prompt 和 Output,这里的Prompt是我们添加了Template之后
- Concat Tokenized Prompt, Output一起,并且生成Response Mask
- Padding到相同的长度
- 将Concat之后的内容移一位,得到inputs和labels
3.2 Per Token Entropy
对于每一个位置\(t\), 模型会给出一下个token的分布,也就是 \(p_{t}(x) = \text{softmax}(\text{logits}_{t})\), Entropy定义为:
\[ H(p) = - \sum_{x \in \mathcal{X}} p(x) \log p(x) \tag{2}\]
- Entropy 高: 分布更“平”,模型不那么确定(探索更强)(对于Category Distribution,\(p(x) = \frac{1}{| x| }\) 有最高的Entropy
- Entropy 低:分布更“尖”,模型更确定(可能变得过度自信、模式坍缩(model collapse)
在 RL 里如果你看到 entropy 很快掉到很低,常见含义是:
- 策略变得太确定(exploration 变差)
- 训练可能开始“钻 reward 漏洞”或输出单一模板
- 学习可能不稳定(尤其和 KL/clip 配合不当时)
计算entropy也很简单的,
\[ \begin{split} \ell &= \text{logits} \\ \log p &= \log\text{softmax}(\ell) \\ p &= \exp(\log p) \\ H(p) &= - \sum_{x \in \mathcal{X}} p(x) \log p(x) \end{split} \tag{3}\]
用上面的公式,我们可以定义一个函数 compute_entropy 来计算entropy:
3.3 Getting Log Probs from Model
接下来,我们来定义另一个Helper Function get_response_log_probs 它的作用是:把“模型对每个位置真实 token 的条件概率”算出来(以 log 形式),并按 token 粒度返回 可能现在理解这个有点困难,在之后SFT 和 RL 的算法中,我们会具体讲解一下的。在这里,我们先定义一下这个函数 我们知道,SFT 的Loss Equation 1 中需要用到 \(\log p_\theta(R_t \mid P, R_{<t})\), 也就是模型在位置\(t\)上, 对真实token \(R_t\)的log prob。 因此,我们需要定义一个函数来计算这个值:
def get_response_log_probs(
model, input_ids: torch.Tensor, labels: torch.Tensor, return_token_entropy: bool = False
) -> dict[str, torch.Tensor]:对于模型输出 \(f_{\theta}(x)\), 其输出的是Logits,也就是没有normalized的distribution,我们第一步自然是利用softmax来将其变为分布, 之后我们再根据我们需要的label,作为索引,来提取出我们需要的log-probs
assignment5-alignment/cs336_alignment/algs/utils.py
def get_response_log_probs(
model,
input_ids: torch.Tensor, # (B, T)
labels: torch.Tensor, # (B, T)
return_token_entropy: bool = False
) -> dict[str, torch.Tensor]:
logits = model(input_ids=input_ids).logits # (B, T, V)
logp = F.log_softmax(logits, dim=-1)
log_probs = logp.gather(-1, labels.unsqueeze(-1)).squeeze(-1)
res = {
"log_probs": log_probs,
}
if return_token_entropy:
entropy = compute_entropy(logits)
res["token_entropy"] = entropy
return res这个函数最关键的部分就是第10行, 通过 gather 函数,我们可以根据labels,来提取出我们需要的log_probs。logp的shape是(B, T, V), 其中B是Batch Size, T是Sequence Length, V是Vocabulary Size,而labels的shape是(B, T), 因此通过 gather 函数,我们可以得到每个位置上,真实token的log_probs, 最终得到的log_probs shape是 (B, T), 也就是我们想要的结果。
WARNING: About Response Mask
我们在这一步,并没用用到Response Mask,也就是说,这个函数会返回所有位置的Log Probs, 包括Prompt部分和Pad部分。我们需要在之后的Loss计算中 masked_normalize,使用Response Mask来Mask掉Prompt和Pad部分。
因此,在SFT 中,Log Probs 我们通过 log_probs.sum(dim=-1) 可以计算出Loss,当然,在做这个计算之前,我们还需要Mask掉Prompts,我们接下去来实现它:
3.4 Masked Normalize
接下来,我们来实现 masked_normalize 函数, 这个函数的作用是:根据Mask,对Tensor进行Mask,并且进行Normalize
assignment5-alignment/cs336_alignment/algs/utils.py
def masked_normalize(
tensor: torch.Tensor, # (B, T)
mask: torch.Tensor, # (B, T)
normalize_constant: float = 1.0,
dim: int | None = None
) -> torch.Tensor:
assert tensor.shape == mask.shape, "Tensor and mask must have the same shape"
masked_f = mask.type_as(tensor)
masked_tensor = tensor * masked_f
masked_sum = torch.sum(masked_tensor, dim=dim) if dim is not None else torch.sum(masked_tensor)
return masked_sum / normalize_constant这个函数很简单,首先我们会根据Mask来Mask掉Tensor中不需要的部分, 之后我们会对剩下的部分进行Sum, 最后我们会根据normalize_constant来进行Normalize。 传入masked_normalize的tensor,一般是Log Probs, 这样我们就可以计算出Masked Log Probs的和, 也就是我们想要的Loss。其中我认为一个很巧妙的设计是 normalize_constant 和 dim 参数, 通过这两个参数,我们可以灵活的控制我们想要的Normalize方式, 以及想要Sum的维度, 比如:
- 如果我们想要计算Batch中所有Token的Loss,我们可以传入
dim=None, 并且normalize_constant = mask.sum(), 这样我们就可以得到Batch中所有Token的平均Loss。 (Token Level Loss) - 如果我们想要计算Batch中每个Sequence的Loss,我们可以传入
dim=-1, 并且normalize_constant = mask.sum(dim = -1), 这样我们就可以得到Batch中每个Sequence的Loss。 (Sequence Level Loss)
3.5 SFT Micro-batch Training Step
有了这些Helper Functions,我们可以来实现SFT的训练, 由于Qwen2.5-Math-1.5B的模型比较大, 我们不能完全实现Batch Size较大的,因此,我们需要通过Gradient Accumulation的技术,来使得训练变得可能,我们先来定义一小步:
assignment5-alignment/cs336_alignment/algs/sft.py
其实很简单,这个函数就做两件事情:
- 计算Loss
- Backward 计算Gradient
\[ \mathcal{L}_{\text{SFT}}^{\text{batch-sum}} = -\sum_{i=1}^{B}\sum_{t=1}^{T} m^{(i)}_t\; \log p_\theta\!\big(y^{(i)}_t \mid x^{(i)}_{<t}\big) \tag{4}\]
其中 \(m_{t}^{(i)}\) 表示的是Mask值
assignment5-alignment/cs336_alignment/algs/sft.py
loss_unscaled = masked_normalize(
policy_log_probs,
response_mask,
normalize_constant=normalize_constant,
dim=-1,
) # 我们可以看到, dim=-1, 而且 normalize_constant = 1.0, 也就是Sequence Level Loss
loss_unscaled = -loss_unscaled.mean()
loss_scaled = loss_unscaled / gradient_accumulation_steps
loss_scaled.backward()
metadata = {
"loss_unscaled": loss_unscaled.detach(),
}
return loss_scaled.detach(), metadataGradient Accumulation的实现也很简单, 我们只需要在计算Loss之后, 除以 gradient_accumulation_steps 即可。 这样我们就可以在之后的SFT Trainer中, 实现Gradient Accumulation的功能了。
3.6 SFT Trainer
有了这些Helper Functions,我们就可以定义我们的SFT Trainer了。相当的直观
class SFTTrainer:
def __init__(
self,
model: PreTrainedModel,
train_config: SFTTrainingConfig,
device: torch.device,
dataset_dir_base: str = "./data/pre-processed",
):
...
def train_step(
self,
) -> tuple[float, float]:
...
def train(self, vllm=None):
...在这里就不过多的赘述了,有需要的同学请自行查看代码 assignment5-alignment/cs336_alignment/algs/sft.py 以及它的训练代码 assignment5-alignment/train_sft.py
3.7 SFT Experiment
接下来我们来看看SFT 的训练结果:
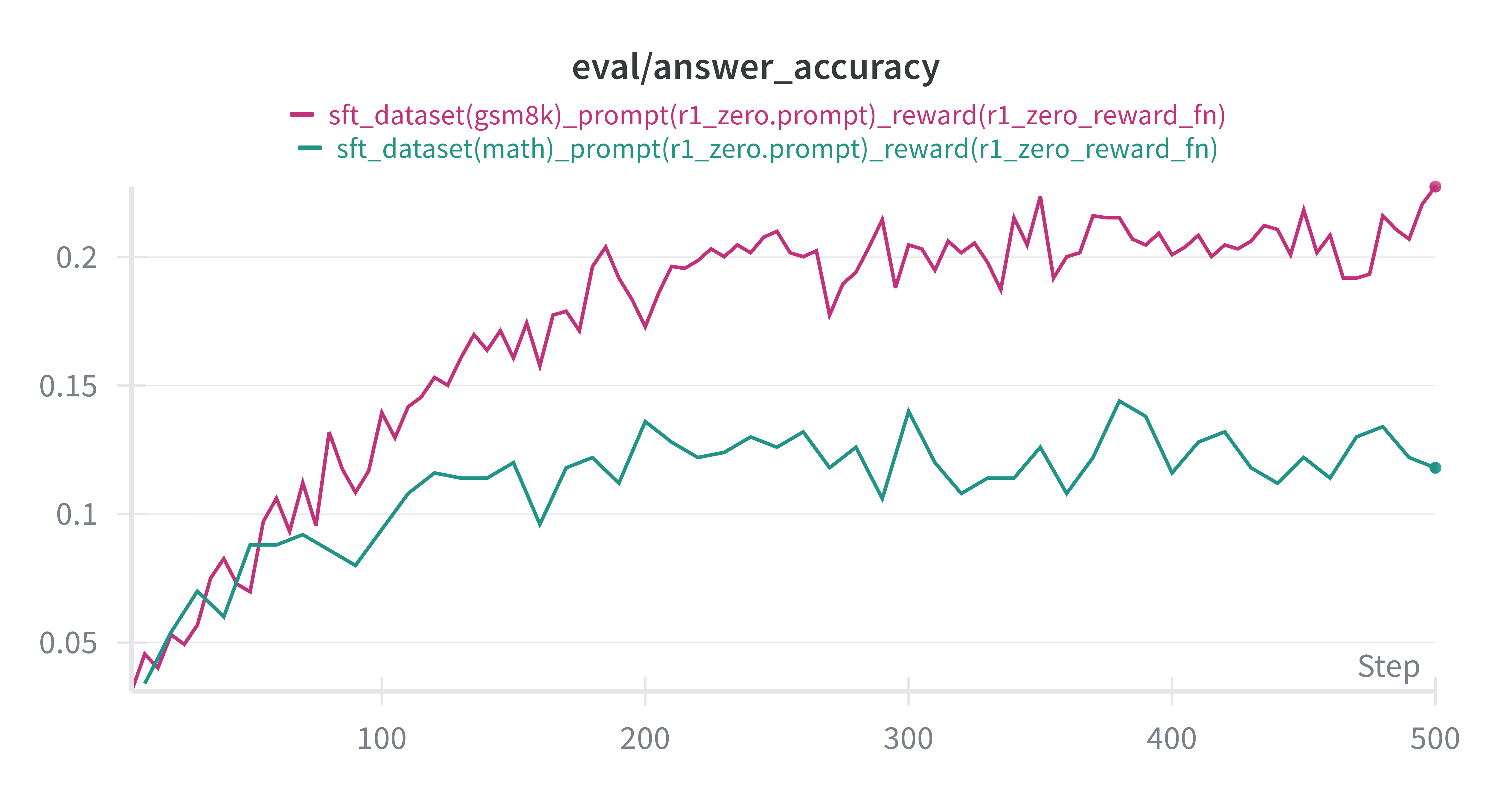
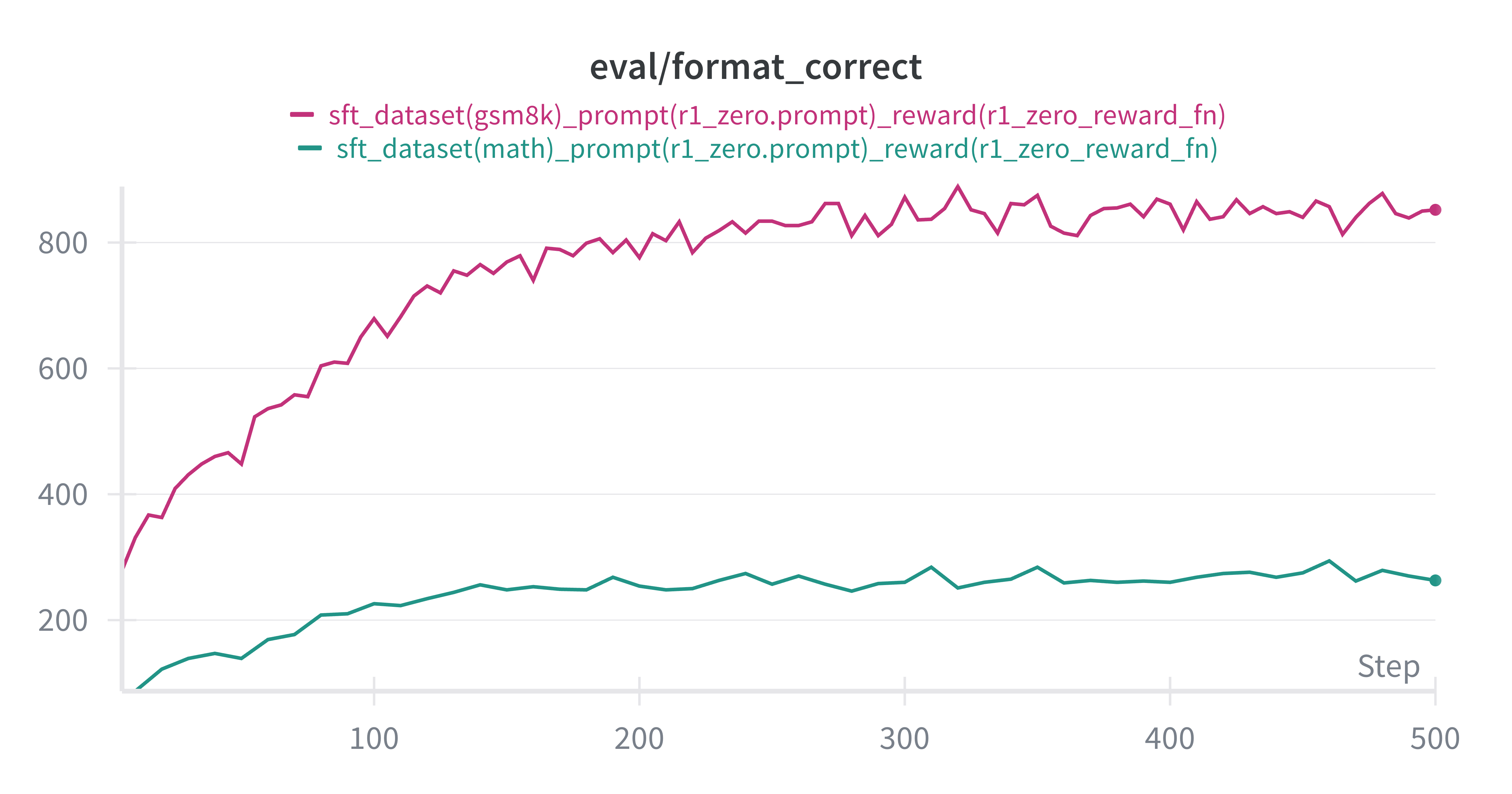
可以看到,经过SFT训练之后,模型在MATH, GSM8K数据集上的表现都有了显著的提升,尤其是在Format Reward上,提升非常明显,这也符合我们之前提到的SFT的作用, 让模型变得更像助理,更会按指令做事。并且Accuracy也有了显著的提升, 这也说明SFT在提升模型能力方面是有效的。
4 Expert Iteration
Expert Iteration, 在SFT的基础上,只多了几步采样的步骤,通过这几个步骤,我们可以得到更多的Prompt-Reponse Paris, 以便我们更好的训练SFT。同时,里面的Functions,我们也可以在GRPO中复用,可以看作是为GRPO做好准备。
在这里,采样的时候,我们会先重复 prompts 和 answers, 以便我们可以对每个prompt采样多个response:
assignment5-alignment/cs336_alignment/algs/ei.py
def get_ei_batch(
prompts: list[str],
answers: list[str],
batch_size: int = 512,
num_responses_per_prompt: int = 4,
):
random_index = random.sample(range(len(prompts)), k=batch_size)
random_prompts = [prompts[i] for i in random_index]
random_answers = [answers[i] for i in random_index]
all_prompts = []
for prompt in random_prompts:
all_prompts.extend([prompt] * num_responses_per_prompt)
all_true_answers = []
for answer in random_answers:
all_true_answers.extend([answer] * num_responses_per_prompt)
return {
"prompts": list(all_prompts),
"true_answers": list(all_true_answers),
}有了prompts 和 answers之后, 我们就可以进行采样了, 采样的代码和之前的vLLM推理代码是一样的:
assignment5-alignment/cs336_alignment/algs/ei.py
之后我们就可以计算Reward, 以及过滤出高质量的Prompt-Response Pairs, 以便我们进行SFT训练:
assignment5-alignment/cs336_alignment/algs/ei.py
rewards_dict = compute_rewards_from_responses(
sampled_responses,
true_answers,
reward_fn=REWARD_FN_MAP[self.train_config.reward_fn],
)
# 7. Filter responses by reward
filtered_prompts, filtered_responses, filtered_answers = filter_by_reward(
sampled_prompts,
sampled_responses,
true_answers,
rewards_dict,
)具体的细节,大家可以查看代码 assignment5-alignment/cs336_alignment/algs/ei.py 以及它的训练代码 assignment5-alignment/train_ei.py
4.1 EI Experiment
接下来我们来看看EI 的训练结果:
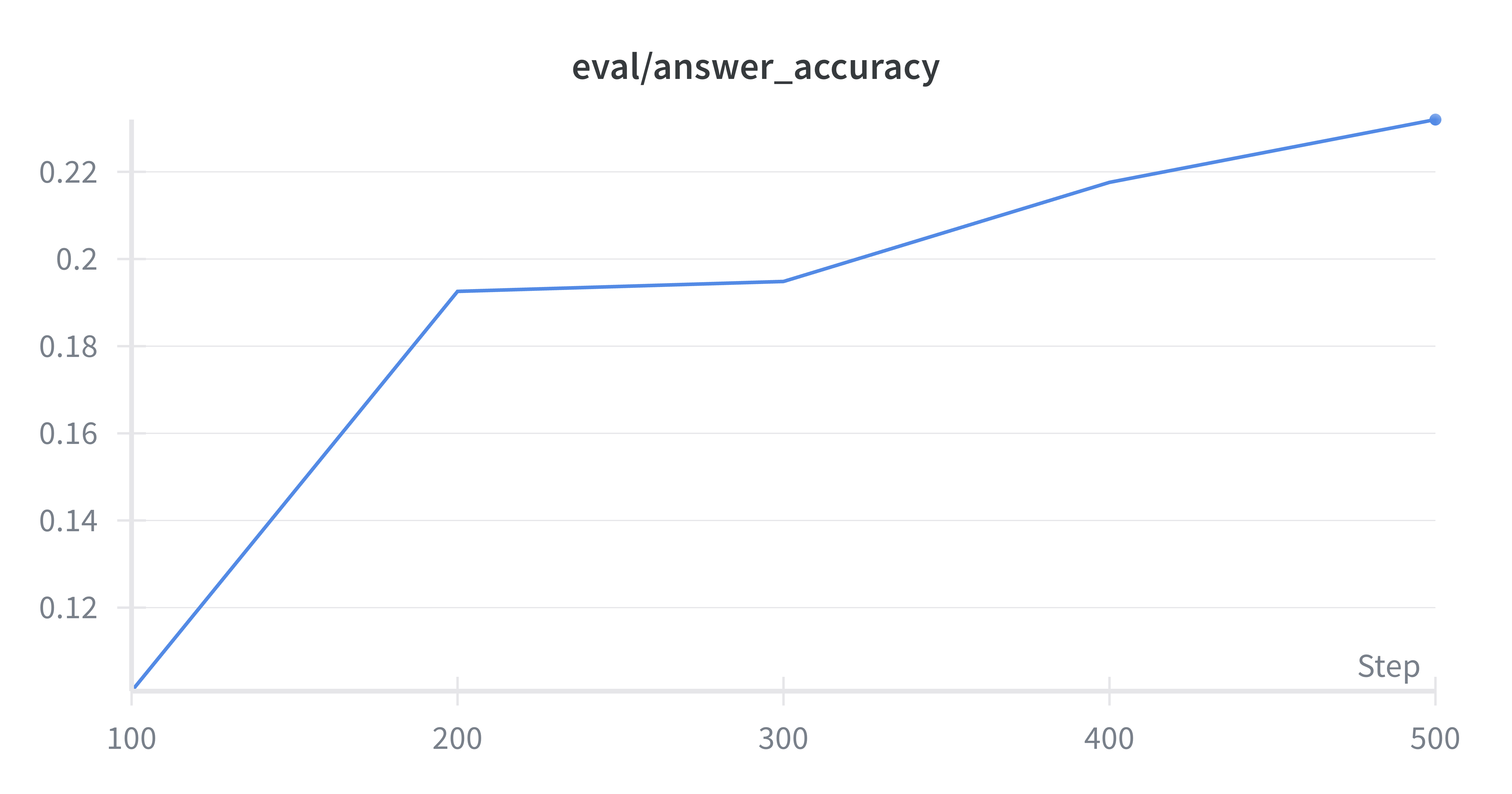
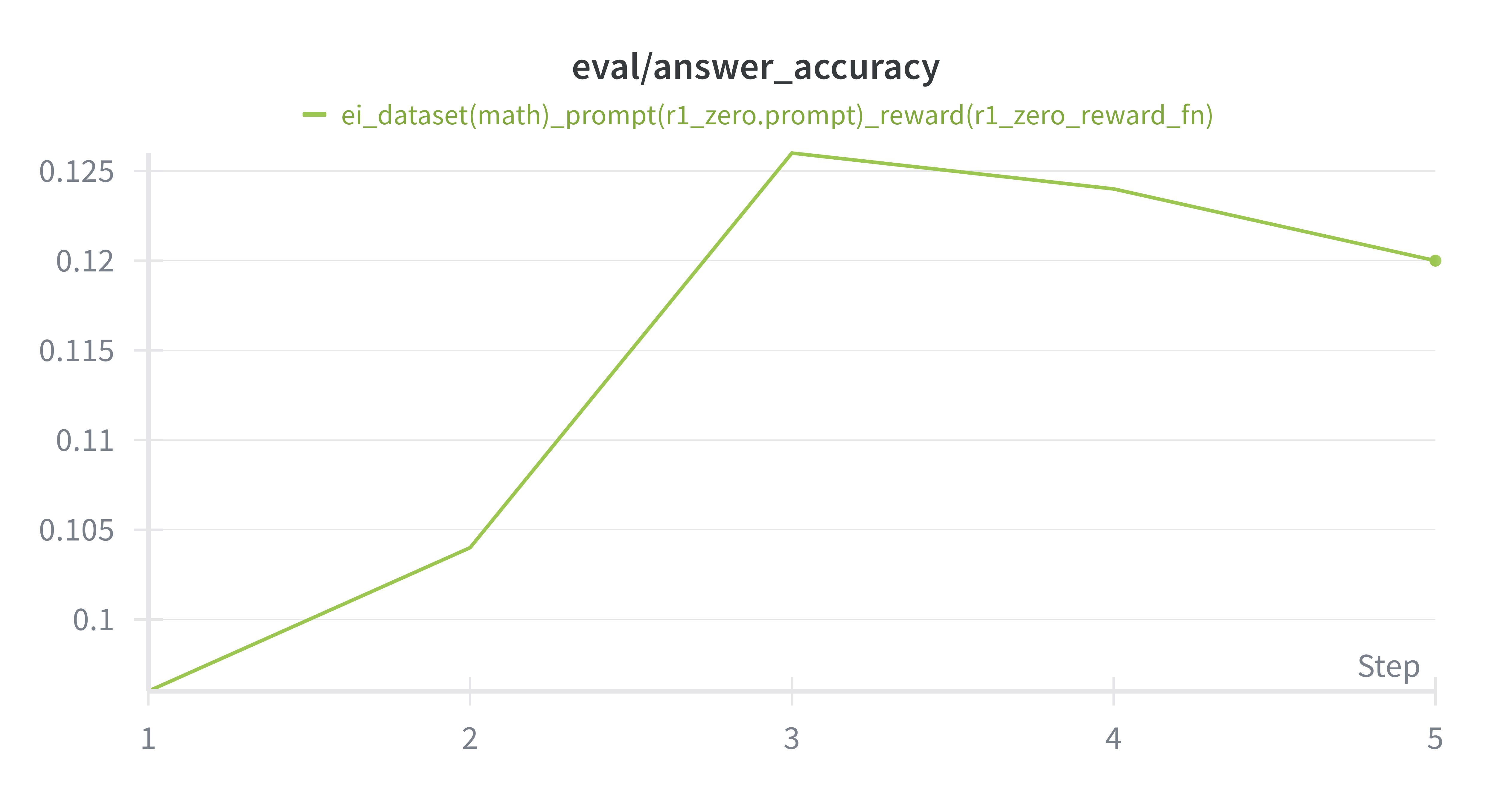
可以看到,经过EI训练之后,模型在MATH, GSM8K数据集上的表现都有了显著的提升,尤其是在Accuracy上,提升非常明显,这也符合我们之前提到的EI的作用,通过采样更多的Prompt-Response Pairs,来提升模型的能力。并且Format Reward也有了显著的提升, 这也说明EI在提升模型能力方面是有效的。
5 GRPO
经过前两轮的热身,终于到了我们本次Assignment的重头戏:GRPO。 GRPO的算法如下:
在实现代码之前,我们先来看看GRPO的几个关键步骤:
- 采样:和EI类似,我们需要对每个prompt采样多个response,以便我们可以计算reward。
- 计算Reward:我们需要计算每个response的reward,以便我们可以进行后续的优化。
- 计算Log Probs:我们需要计算每个response的log probs,包括Old Policy和New Policy的log probs。
- 计算Advantage:我们需要计算每个response的advantage。
- 计算Loss:我们需要计算GRPO的Loss,并且进行Backward。
- 更新Old Policy:我们需要在每个Step结束后,更新Old Policy为当前的New Policy。
我们一步一步来看。首先是采样和计算Reward,这部分和EI是一样的,我们就不赘述了,我这里采用的方法,也是先重复prompts 和 answers, 以便我们可以对每个prompt采样多个response:
assignment5-alignment/cs336_alignment/algs/grpo.py
def sample_batch_questions(
prompts: list[str],
answers: list[str],
batch_size: int,
group_size: int = 8,
) -> tuple[list[str], list[str]]:
index = random.sample(range(len(prompts)), k=batch_size)
sampled_prompts = [prompts[i] for i in index]
sampled_answers = [answers[i] for i in index]
batch_prompts = []
batch_answers = []
for p, a in zip(sampled_prompts, sampled_answers):
batch_prompts.extend([p] * group_size)
batch_answers.extend([a] * group_size)
return batch_prompts, batch_answers
rollout_responses = generate_responses(vllm, sample_prompts, self.sampling_params)有了采样的responses之后, 我们就可以计算Reward了:
assignment5-alignment/cs336_alignment/algs/grpo.py
def compute_group_normalized_rewards(
reward_fn: Callable,
rollout_responses: list[str],
repeated_ground_truths: list[str],
group_size: int,
advantage_eps: float,
normalized_by_std: bool = True,
):
formatted_rewards = []
answer_correct_rewards = []
rewards = []
for response, true_answer in zip(rollout_responses, repeated_ground_truths):
reward_info = reward_fn(response, true_answer)
rewards.append(reward_info["reward"])
formatted_rewards.append(reward_info["format_reward"])
answer_correct_rewards.append(reward_info["answer_reward"])
advs = []
for i in range(0, len(rewards), group_size):
group_rewards = rewards[i : i + group_size]
group_rewards_tensor = torch.tensor(group_rewards)
group_mean = torch.mean(group_rewards_tensor)
if normalized_by_std:
group_std = torch.std(group_rewards_tensor) + advantage_eps
normalized_rewards = (group_rewards_tensor - group_mean) / group_std
else:
normalized_rewards = group_rewards_tensor - group_mean
advs.extend(normalized_rewards.tolist())
meta_info = {}
return advs, rewards, meta_info
advantages, raw_rewards, metadata = compute_group_normalized_rewards(
reward_fn=self.reward_fn,
rollout_responses=rollout_responses,
repeated_ground_truths=repeated_ground_truths,
group_size=self.train_config.group_size,
advantage_eps=self.train_config.advantage_eps,
normalized_by_std=self.train_config.norm_by_std,
)在这个函数中, 我们计算了每个response的reward, 之后我们根据group size, 来计算group normalized advantages。 具体来说, 我们会将每个group中的rewards, 计算mean和std, 之后我们会根据mean和std来计算normalized rewards, 也就是advantages。 这样做的好处是, 可以减少不同group之间的reward scale差异, 使得训练更加稳定。
有了advantages之后, 我们就可以计算Log Probs了,
assignment5-alignment/cs336_alignment/algs/grpo.py
input_ids = tokenized["input_ids"].to(self.device, non_blocking=True)
labels = tokenized["labels"].to(self.device, non_blocking=True)
response_mask = tokenized["response_mask"].to(self.device, non_blocking=True)
ave_length = response_mask.sum(dim=1).float().mean().item()
old_log_probs = []
self.model.eval()
with torch.no_grad():
for i in trange(0, input_ids.size(0), self.train_config.micro_batch_size):
batch_input_ids = input_ids[i : i + self.train_config.micro_batch_size]
batch_labels = labels[i : i + self.train_config.micro_batch_size]
with self.ctx:
policy_outputs = get_response_log_probs(
self.model,
input_ids=batch_input_ids,
labels=batch_labels,
return_token_entropy=False,
)
batch_log_probs = policy_outputs["log_probs"]
old_log_probs.append(batch_log_probs.cpu())
old_log_probs = torch.cat(old_log_probs, dim=0)
self.model.train()在这里,我也用了类似于Gradient Accumulation的技术, 来计算Old Policy的Log Probs, 以便节省显存。 计算New Policy的Log Probs也是类似的, 这里就不赘述了。
有了Old Policy和New Policy的Log Probs之后, 我们就可以计算GRPO的Loss了:
assignment5-alignment/cs336_alignment/algs/grpo.py
def grpo_microbatch_train_step(
policy_log_probs: torch.Tensor,
response_mask: torch.Tensor,
gradient_accumulation_steps: int,
loss_type: Literal["no_baseline", "reinforce_with_baseline", "grpo_clip"],
raw_rewards: torch.Tensor | None = None,
advantages: torch.Tensor | None = None,
old_log_probs: torch.Tensor | None = None,
cliprange: float = 0.2,
) -> tuple[torch.Tensor, dict]:
"""
Compute the GRPO loss over microbatches for training.
"""
loss, metadata = compute_policy_gradient_loss(
policy_log_probs=policy_log_probs,
loss_type=loss_type,
raw_rewards=raw_rewards,
advantages=advantages,
old_log_probs=old_log_probs,
cliprange=cliprange,
)
masked_loss = masked_mean(
tensor=loss,
mask=response_mask,
dim=-1,
)
masked_loss = masked_loss.mean()
masked_loss = masked_loss / gradient_accumulation_steps
masked_loss.backward()
return masked_loss, metadata在这个函数中, 我们计算了GRPO的Loss, 具体来说, 我们会根据传入的loss type, 来计算不同类型的Loss, 之后我们会根据Response Mask来Mask掉不需要的部分, 最后我们会进行Backward。
最后, 在每个Step结束后, 我们需要更新Old Policy为当前的New Policy, 这部分代码也很简单, 直接赋值即可.
其实熟悉了 GRPO 的算法之后,在回过头看这个算法实现, 你会发现, GRPO的实现其实并不复杂, 主要是把之前SFT和EI的代码进行了一些复用, 以及增加了一些新的功能, 比如计算Advantage, 以及计算不同类型的Loss。 只要理解了这些关键步骤, 实现起来其实并不难。
5.1 GRPO Experiment
接下来我们来看看GRPO 的训练结果:
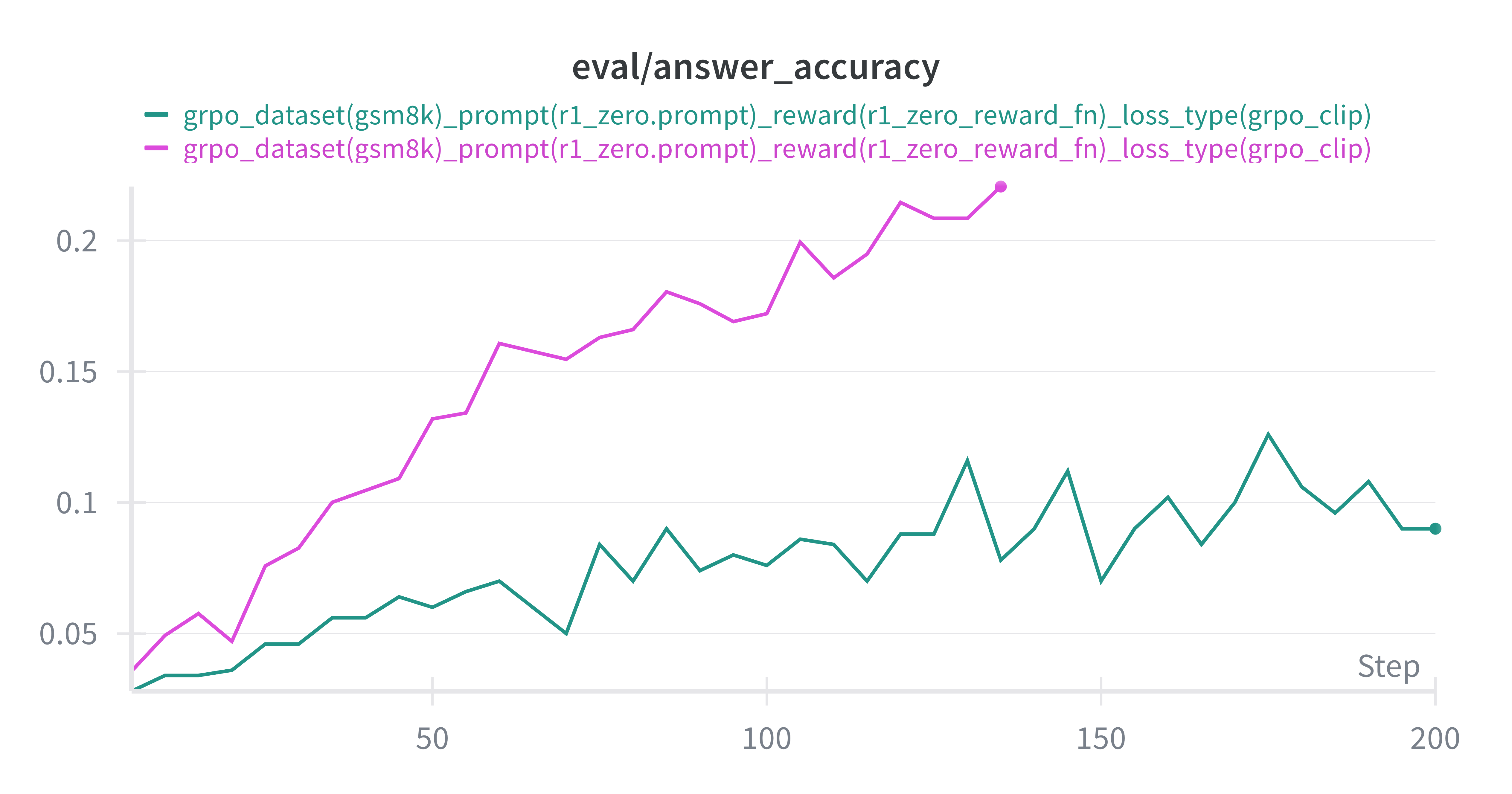
5.2 Other Experiments
在Assignment中, 我还实现了一些其他的实验, 比如不同的Reward Function, 不同的Loss Type, 以及不同的Group Size。由于时间的关系,我并没有做这些实验,不过在代码中,可以很容易的实现这些实验。
5.2.1 Learning Rate Tuning
首先第一个实验就是学习率的调节, 由于GRPO的训练比较不稳定, 因此学习率的选择非常重要。 我尝试了不同的学习率, 发现0.0001是一个比较合适的选择, 过高的学习率会导致训练不稳定, 过低的学习率会导致训练收敛慢。
5.2.2 Effect of Baseline
Baseline的作用是减少训练的方差, 因此我尝试了不同的Baseline, 发现使用Baseline可以显著提升训练的稳定性, 并且可以提升模型的性能。
5.2.3 Length Normalization
在计算Log Probs的时候,根据不同的Length Normalization方式, 也会对训练产生影响。 我尝试了不同的Normalization方式, 发现使用Token Level Normalization可以提升模型的性能。
5.2.4 Normalization with group std
在计算Advantage的时候, 我尝试了是否使用Group Std来进行Normalization,
5.2.5 Off-Policy vs. On-Policy
要想把GRPO 训练好, 还有一个很重要的点就是Off-Policy 和 On-Policy的选择。 在GRPO中, 我们使用的是On-Policy的方式, 也就是使用Old Policy来采样数据, 然后使用New Policy来进行优化。 这种方式可以提升训练的稳定性, 并且可以提升模型的性能。要想把它改成Off-Policy也是可以的, 但是需要注意一些细节, 比如Importance Sampling等。
5.2.6 Off Policy Clipping
5.2.7 Different Prompts
当然,我们还可以尝试不同的Prompts, 以便提升模型的性能。 不同的Prompt会对模型的性能产生影响, 因此选择合适的Prompt也是很重要的。当Prompts改变时,对应的Reward Function也需要相应的调整, 以便更好的适应新的Prompt。
6 DPO
这个部分,是Assignment05 的补充内容,其主要目的是了解DPO算法的基本思想和实现方式。 由于时间的关系, 我并没有实现DPO的完整代码, 但是我会介绍DPO的基本思想和实现方式。DPO的算法如下: