03: Training data-efficient image transformers & distillation through attention (DeiT )
再上一篇,我们介绍了 Vision Transformer(ViT),它将 Transformer 架构成功应用于计算机视觉任务,展示了在大规模数据集上优越的性能。然而,ViT 对训练数据的需求非常高(data hungry),在中小规模数据集上表现不佳(在CIFAR-10上仅有30%左右的准确率)。为了解决这个问题,DeiT(Data-efficient Image Transformers)提出了一种基于知识蒸馏的方法,通过引入一个专门的蒸馏 token 和 attention-based distillation 技术,使得 ViT 能在中小规模数据集上高效训练并达到与 CNN 可比的性能。
在本篇文章中,我们将深入探讨 DeiT 的核心思想、实验结果以及其在计算机视觉领域的影响。我们将首先介绍 DeiT 的基本架构和训练方法,然后分析其在多个数据集上的表现,最后总结其关键概念并提供相关资源供进一步学习。
1 Preliminary
首先,我们来准备一些必要的背景知识,以便更好地理解 DeiT 的创新之处。当然,我们要先了解什么是Vision Transformer 在这里就不多赘述了,有需要的同学可以回顾一下上一篇文章。其次,我们还需要了解一下知识蒸馏(Knowledge Distillation)的基本概念。
1.1 Knowledge Distillation
Knowledge Distillation((Hinton, Vinyals, and Dean 2015)) 是一种Model Compression技术,旨在将一个大型、复杂的教师模型(teacher model)中的知识传递给一个较小、较简单的学生模型(student model)。通过这种方式,学生模型可以在保持较高性能的同时减少计算资源的需求。通过最小化KL-Divergence等损失函数,学生模型学习模仿教师模型的输出分布,从而获得更好的泛化能力:
\[ L_{KD} = \alpha L_{CE}(y, p_{student}) + (1 - \alpha) L_{KL}(p_{teacher}, p_{student}) \tag{1}\]
其中,\(L_{CE}\) 是学生模型的Cross Entropy Loss,\(L_{KL}\) 是教师模型和学生模型输出分布之间的 KL 散度,\(\alpha\) 是一个权衡参数, \(p_{teacher}\) 和 \(p_{student}\) 分别是教师模型和学生模型的输出概率分布, \(y\) 是真实标签的one-hot encoding。
从这个损失函数(Equation 1)可以看出,知识蒸馏不仅考虑了学生模型与真实标签之间的误差(通过交叉熵损失),还考虑了学生模型与教师模型输出分布之间的差异(通过 KL 散度)。这种双重监督机制使得学生模型能够更好地捕捉教师模型中的知识,从而在性能上得到提升。
2 DeiT
有了上述背景知识,我们现在可以深入探讨 DeiT 的核心创新。DeiT是由 Facebook AI Research(FAIR)的研究人员提出的,旨在通过知识蒸馏显著提升 Vision Transformer 的数据效率。DeiT 的核心思想是引入一个专门的蒸馏 token 和 attention-based distillation 技术,使得 ViT 能在中小规模数据集上高效训练并达到与 CNN 可比的性能。DeiT的整体架构如下图所示:
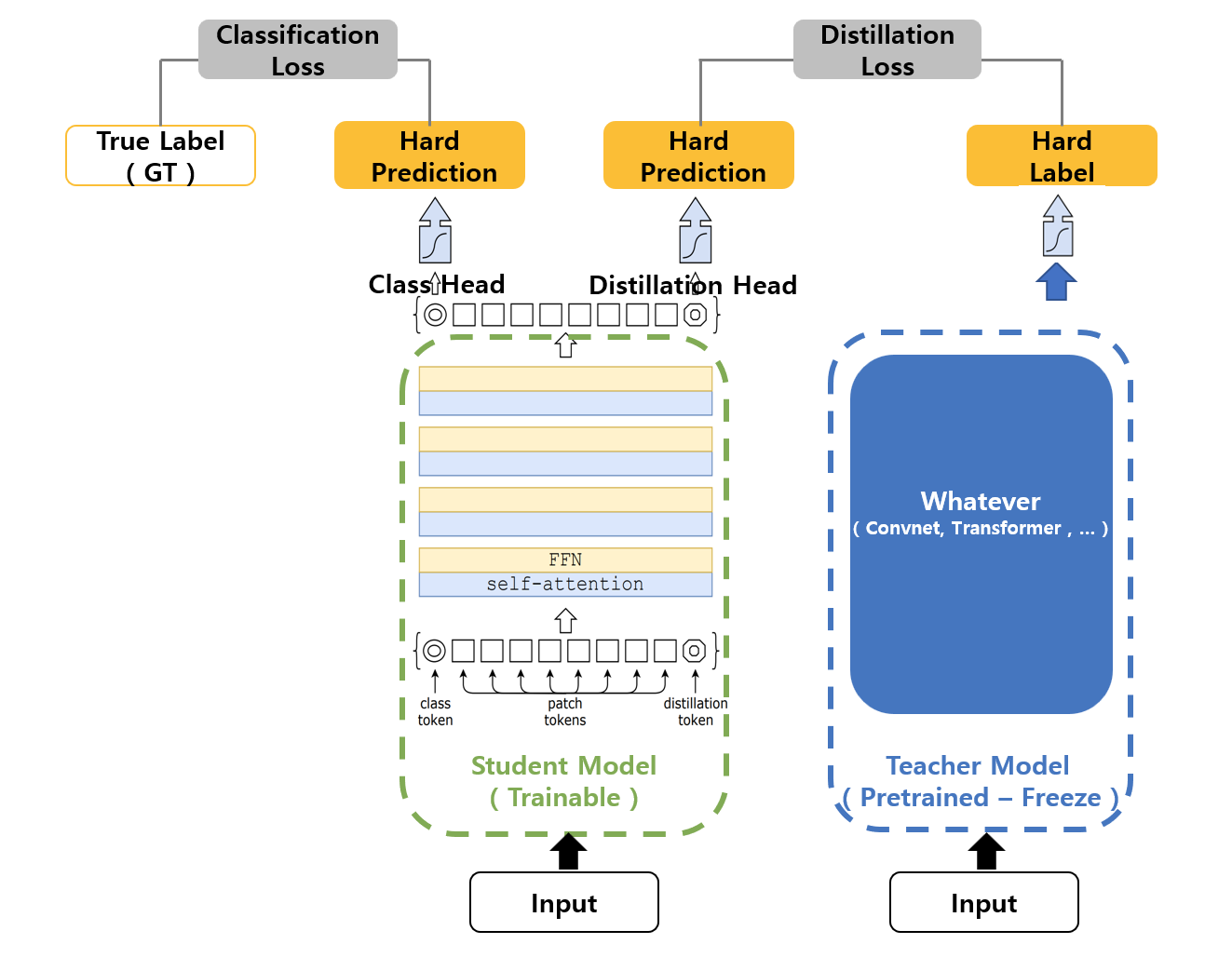
从图中可以看出,DeiT 在 ViT 的基础上引入了一个新的蒸馏 token ([DIS]),该 token 通过与教师模型的输出进行对齐来学习教师模型的知识。并且在训练过程中,DeiT 同时优化两个损失函数:
- 一个是常规的交叉熵损失,用于监督 class token 的分类性能;
- 另一个是 KL 散度损失,用于监督 distillation token 的输出与教师模型的输出分布之间的一致性。
从代码实现的角度来看,DeiT 的训练过程可以分为以下几个步骤:
- 教师模型训练:首先,训练一个大型的教师模型(通常是一个预训练的 CNN)来获得高性能的视觉特征表示。
- 学生模型初始化:然后,初始化一个较小的学生模型(DeiT),并引入一个新的蒸馏 token。
- 知识蒸馏训练:在训练过程中,学生模型通过最小化与教师模型输出的 KL 散度来学习教师模型的知识,同时通过最小化注意力分布差异来进一步提升性能。
接下来我们来具体看一下DeiT的实现细节,以及为什么要这么设定。
2.1 Why need distillation?
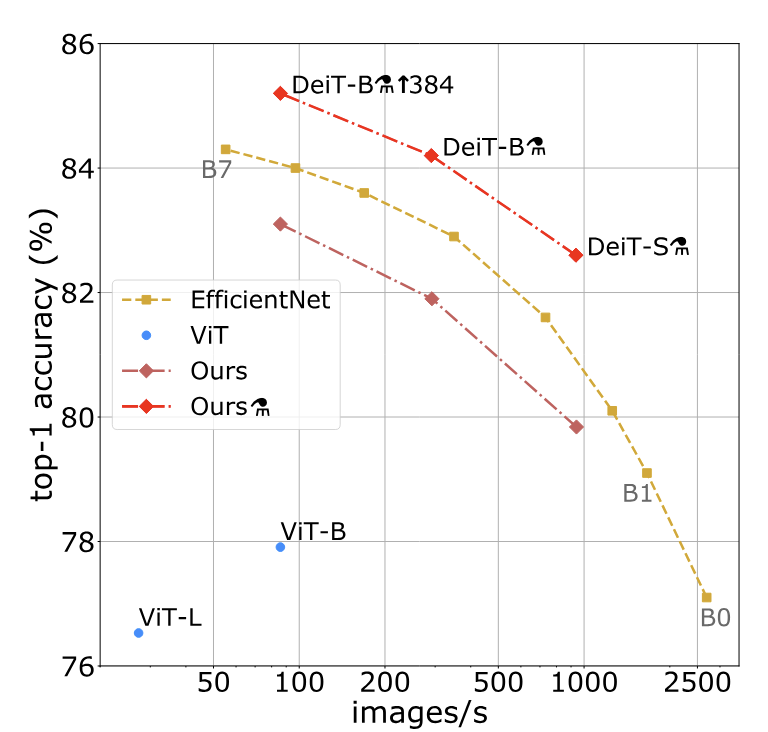
在 DeiT 的实验中,作者比较了不同模型在吞吐量(images/s)和精度(top-1 accuracy)上的权衡。通过引入知识蒸馏,DeiT 在保持较高精度的同时显著提升了吞吐量。这表明 DeiT 的核心创新(引入 distillation token 和 attention-based distillation)在提升 ViT 的数据效率方面起到了关键作用,使得 ViT 能够在中小规模数据集上高效训练并达到与 CNN 可比的性能。
2.2 Loss Functions in DeiT
在DeiT这篇文章中,它将Distillation 分为两个维度:
- Hard vs Soft Distillation:Hard distillation 直接使用教师模型的 argmax 类别作为伪标签进行交叉熵监督,而 soft distillation 则通过对齐教师模型和学生模型的 softmax 分布来进行监督。
- Classical Distllation vs Token Distillation:Classical distillation 直接对学生模型的 class token 输出进行蒸馏,而 token distillation 则引入一个专门的 distillation token,通过自注意力与其他 token 交互并预测教师模型的标签。
我们先来看一下Hard vs Soft Distillation
2.2.1 Hard vs. Soft Distillation
Soft Distllation 是最常见的Knowledge Distillation的方法,与我们在前面提到的 KD Loss(Equation 1) 中的 KL 散度部分类似,旨在对齐教师模型和学生模型的输出分布。它的损失函数可以表示为:
\[ \mathcal{L}_\text{global} = (1 - \lambda) \cdot \mathcal{L}_\text{CE}(\psi(Z_s), y) + \lambda \cdot T^2 \cdot \mathcal{L}_\text{KL}(\psi(Z_t / T), \psi(Z_s / T)) \]
其中,\(T\) 是温度参数,用于平滑教师模型的输出分布,\(Z_t\) 和 \(Z_s\) 分别是教师模型和学生模型的输出的 logits,\(\psi\) 是 softmax 函数,\(\lambda\) 是权衡参数。
通过调节温度参数 \(T\),我们可以控制教师模型输出分布的平滑程度,从而影响学生模型学习的效果。通常情况下,较高的温度会使教师模型的输出分布更加平滑,有助于学生模型更好地捕捉教师模型中的知识。
与soft distillation相比, DeiT提出了hard distillation的概念,即直接使用教师模型的 argmax 类别作为伪标签进行交叉熵监督。它的损失函数可以表示为:
\[ \mathcal{L}_\text{global}^{\text{hard}} = \frac{1}{2} \cdot \mathcal{L}_\text{CE}(\psi(Z_s), y) + \frac{1}{2} \cdot \mathcal{L}_\text{CE}(\psi(Z_s), \text{argmax}(Z_t)) \]
在 DeiT 的实验中,作者发现 hard distillation 在强增强和数据匮乏的情况下表现更好,推测是因为 hard 监督更稳健、更“像标签”,而 soft distillation 在这种情况下可能过于平滑,导致学生模型难以捕捉教师模型中的关键信息。
NOTE: Convert Between Hard and Soft Distillation
论文中提到,Hard-Label Disllation 可以通过Label Smoothing的方法,从而转化为Soft Distillation。具体来说,在Transformer的章节,我们已经了解了Label Smoothing的概念:它通过将真实标签的 one-hot encoding 转换为一个平滑的分布来防止模型过拟合:
\[ y_{smooth} = (1 - \epsilon) \cdot y + \epsilon / K \]
其中,\(y\) 是原始的 one-hot 标签,\(\epsilon\) 是平滑参数,\(K\) 是类别总数,通过这种方法,True Label有\(1 - \epsilon\) 的概率,而其他类别有 \(\epsilon / K\) 的概率。通过调整 \(\epsilon\) 的值,我们可以在 Hard Distillation 和 Soft Distillation 之间进行平滑过渡, 比如当 \(\epsilon\) 接近 0 时,\(y_{smooth}\) 接近于原始的 one-hot 标签,类似于 Hard Distillation;当 \(\epsilon\) 较大时,\(y_{smooth}\) 更加平滑,类似于 Soft Distillation。
2.2.2 Classical Distillation vs. Token Distillation
了解了 Loss 函数的不同,接下来我们来看一下 Classical Distillation 和 Token Distillation 的区别。我们知道在传统的知识蒸馏方法中,学生模型直接对齐教师模型的输出 logits,这种方法我们称之为 Classical Distillation。 并且ViT 的输出是一个 class token 的表示,我们可以直接对齐这个 class token 的输出与教师模型的输出进行蒸馏,这也是一种常见的做法。然而,DeiT 提出了一个创新的概念,即引入一个专门的 distillation token,通过自注意力与其他 token 交互并预测教师模型的标签。这种方法被称为 Token Distillation。 在 Token Distillation 中,学生模型不仅通过 class token 来进行分类,还通过 distillation token 来学习教师模型的知识。具体来说,distillation token 会通过自注意力机制与其他 token 进行交互,从而形成一个结构化的信息流,使得学生模型能够更好地捕捉教师模型中的知识。
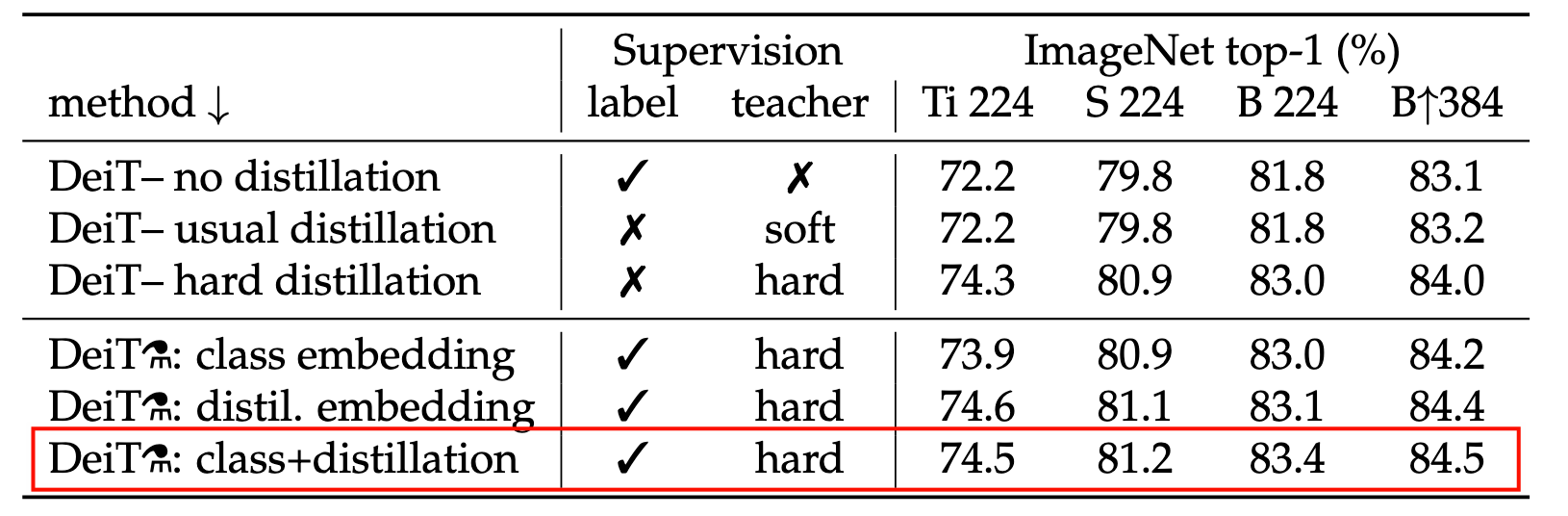
我们可以看到,通过不用的Loss 以及不用的蒸馏方法,组合 (Hard + Token) 的效果明显优于其他组合,说明 DeiT 的核心创新(引入 distillation token 和 hard distillation)在提升 ViT 的数据效率方面起到了关键作用。
TL;DR: DeiT
回头看DeiT的核心创新,我们可以总结为以下几点:
- 引入 Distillation Token:DeiT 在 ViT 的基础上引入了一个专门的 distillation token,通过自注意力与其他 token 交互并预测教师模型的标签,从而实现了更有效的知识蒸馏。
- Hard Distillation 的优势:DeiT 强调在强增强和数据匮乏的情况下,hard distillation 比 soft distillation 更稳健、更“像标签”,从而在多个数据集上取得了更好的性能。
- Late Fusion 的效果:在推理时,DeiT 通过融合 class head 和 distill head 的预测来提升鲁棒性和精度,这种 late fusion 的策略在实验中表现出色。
很简单,也很实用。
2.3 Teacher Model
有了损失函数,以及Token Distillation的概念,接下来我们来看看如何选择Teacher Model。DeiT的团队观察到:用卷积网络(convnet)当 teacher,蒸馏效果更好,甚至比“用另一个性能差不多的 transformer 当 teacher”更能让学生 DeiT 提升,他们认为这是因为 CNN 的归纳偏置(局部性等)能通过蒸馏迁移给 ViT,缓解 ViT 在小数据训练时的劣势。因此,DeiT 的默认设置是使用一个预训练的 CNN 作为教师模型来指导 DeiT 的训练。
在CNN中,它们比较不同的RegNet的变体,
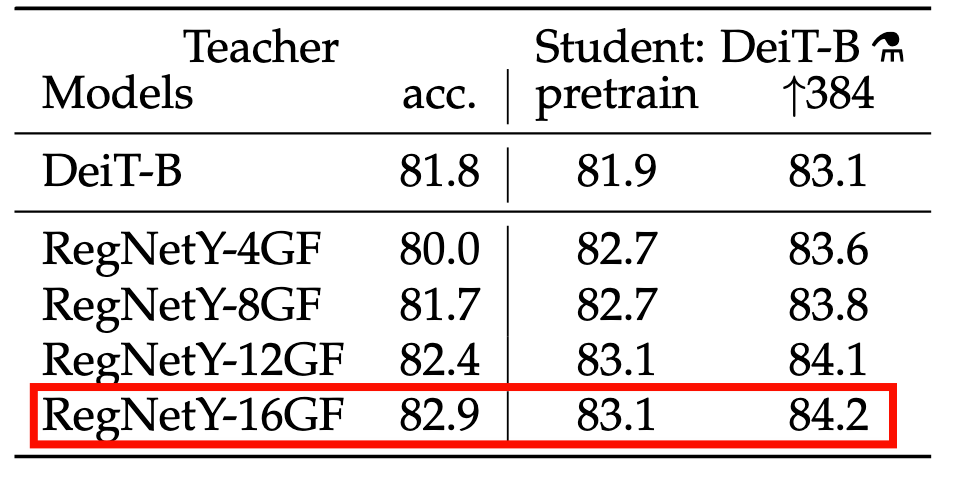
因此在 DeiT 的实验中,作者选择了 RegNetY-16GF 作为教师模型,因为它在 ImageNet 上表现出色,并且具有适当的容量来指导 DeiT 的训练。通过使用这个预训练的 CNN 作为教师模型,DeiT 能够更有效地学习到视觉特征,从而在多个数据集上取得了显著的性能提升。
2.4 Experiment
3 Summary
在这篇文章中,我们深入探讨了 DeiT(Data-efficient Image Transformers)的核心创新和实验结果。DeiT 通过引入一个专门的蒸馏 token 和 attention-based distillation 技术,显著提升了 Vision Transformer 的数据效率,使其能够在中小规模数据集上高效训练并达到与 CNN 可比的性能。我们还分析了 DeiT 在多个数据集上的表现,并总结了其关键概念,如 hard distillation、token distillation 和 late fusion 等。
4 Key Concepts
| Concept | Description |
|---|---|
| Data-efficient training | 通过更强的数据增强/正则/训练日程等,使 ViT 在 ImageNet-only 下也能稳定收敛并获得高精度 |
| Knowledge distillation | Teacher–student 训练范式,让 student 学 teacher 的输出/分布 |
| Hard-label distillation | 用 teacher 的 argmax 类别当伪标签做交叉熵监督 |
| Soft distillation (KL) | 对齐 teacher/student 的 softmax 分布,常见为 KL + CE |
| Distillation token | 在输入序列加入专职 token,通过自注意力与其他 token 交互并预测 teacher 标签 |
| Late fusion | 推理时融合 class head 与 distill head 的预测 |
| Inductive bias transfer | 借助 CNN teacher 把局部性等归纳偏置迁移给 ViT |
| Throughput–accuracy trade-off | 用 image/s 与 top-1 精度共同衡量部署价值。 |
5 Q & A
Question 1: DeiT 和 ViT 的结构差异到底在哪里?
Answer: DeiT-B 与 ViT-B 结构基本一致,主要差异在训练策略;引入 distillation 时额外加入 distillation token 以及对应的 head/损失与融合策略。
Question 2: 为什么 DeiT 强调 hard distillation,soft distillation 反而不行?
Answer: 论文实证显示在相同设置下 hard distill 明显优于 soft(例如 DeiT-B@224:soft≈81.8,而 hard≈83.0),推测 hard 监督在强增强与数据匮乏下更稳、更“像标签”。
Question 3: distillation token 相比“直接对 logits 做蒸馏”到底多了什么?
Answer: 它把 teacher 信号绑定到序列里一个专职 token,并让该 token 通过自注意力与 patch/class token 交互,形成结构化的信息流;实证上 token 蒸馏与双头融合优于常规蒸馏基线。
Question 4: 推理时用 class token 还是 distillation token?
Answer: 两者都可以单独做分类,但论文默认用 late fusion(两路 softmax 相加)效果最好;并且 distillation token 往往略强、与 CNN 预测更相关。
Question 5: 为什么“CNN 当 teacher 比 Transformer 当 teacher 更好”?
Answer: 论文观察到 CNN teacher 的蒸馏效果更佳,合理解释是 CNN 的归纳偏置(局部性等)能通过蒸馏迁移给 ViT,缓解 ViT 在小数据训练时的劣势。